[Paper] Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
📎 Paper: https://arxiv.org/abs/1912.02424
본 논문에서는 one-stage anchor-based detector(ex. RetinaNet)와 center-based anchor-free detector(ex. FCOS)의 본질적인 차이는 positive와 negative training samples를 정의하는 방법이라고 말하고 있다.
또한, positive sample과 negative sample을 정의하는 새로운 방법인 ATSS를 소개하여, 이를 통해 anchor-based 방법과 anchor-free 방법 간의 차이를 줄일 수 있다고 주장한다.
1. Abstract
object detection은 anchor-based detectors에 의해 주도되어 왔으나, 최근에는 FPN과 focal loss의 등장으로 anchor-free detectors도 주목받고 있다.
anchor-based와 anchor-free의 가장 중요한 차이점이 “positive / negative training samples를 정의하는 방법”이라고 언급한다.
즉, positive / negative samples를 같게 정의한다면, box를 regression(= anchor-based)하든 point를 regression(= anchor-free)하든지간에 최종 성능에는 차이가 없다.
📌 Positive Sample vs. Negative Sample
positive sample 객체 영역 negative sample 배경 영역 - Adaptive Training Sample Selection(ATSS)을 제안한다.
- object의 통계적 특성을 이용하여 positive / negative samples를 자동으로 선택하는 방법이다.
- anchor-based와 anchor-free의 performance를 크게 향상시키며, 그 둘 사이의 성능 차이를 줄여준다.
- overhead 없이 SOTA detectors의 성능을 크게 향상시킬 수 있다. (50.7% AP)
- 이미지의 각 location 마다 여러 anchors를 tiling 하는 것은 불필요하다.
2. Introduction & Related Work
2.1 Anchor-based Detector
dominate, SOTA의 대다수를 차지한다.
- one-stage methods (ex. SSD)
- 계산의 효율성 → 빠르다.
- two-stage methods (ex. Faster R-CNN)
- 보다 정확한 예측 결과를 도출한다.
- 공통점
- 각 이미지마다 많은 수의 preset anchors를 tiling 한다.
- 이러한 anchors의 카테고리를 예측하고 좌표를 정제한다.
- 정제한 anchors를 detection 결과로 도출한다.
2.2 Anchor-free Detector
FPN과 Focal Loss의 등장으로 주목 받고 있다.
- preset anchors 없이 바로 object를 찾는다.
- keypoint-based methods
- 동작
- locate several pre-defined or self-learned keypoints
- bound the spatial extent of objects
- pose estimation 분야에서 주로 많이 쓰이는 방법이다.
- ex) CornerNet(top-left, bottom-right), ExtremeNet(top-most, left-most, bottom-most, right-most, center 등)
- 동작
- center-based methods
- 동작
- use the center point or region of objects to define positives (as foreground)
- predict the four distances from positives to the object boundary (four sides)
- ex) FCOS, DenseBox, GA-RPN 등
- 동작
- 특징
- anchors와 관련된 hyperparameters가 필요하지 않다.
- anchor-based detectors와 비슷한 성능을 낸다.
- generalization ability 측면에서 잠재력이 있다.
2.3 RetinaNet vs. FCOS
RetinaNet
one-stage detector의 경우, 이미지를 grid로 나누어 각 cell마다 bounding box를 예측하도록 하므로, positive sample(객체 영역) « negative sample(배경 영역)인 문제가 발생한다.
two-stage detector의 경우, region proposal 단계에서 background sample을 어느정도 제거한다.
이러한 class imbalance 문제를 해결하기 위해 쉬운 예제에 작은 가중치를, 어려운 예제에 큰 가중치를 부여하는 focal loss를 도입하여 성능을 향상시킨 모델이다.
FCOS
모델의 성능이 anchor box의 속성에 민감한 anchor-based 방법이 아닌, anchor-free 방법을 도입한 모델이다. (RetinaNet 이후)
region proposal과 anchor가 모두 필요하지 않은 one-stage 모델이다.
- feature map에서의 위치 (x, y)가 GT bounding box에 속하면 positive sample로 간주한다.
- multi-level FPN 구조, center-ness 등을 사용하여 성능을 향상시켰다.
Comparison
anchor-free FCOS(MS COCO dataset 기준 37.1%)가 anchor-based RetinaNet(32.5%)보다 성능이 높다.
| RetinaNet | FCOS | |
|---|---|---|
| Type | one-stage anchor-based detector | center-based anchor-free detector |
| Number of anchors tiled per location | several anchor boxes per location | one anchor point per location (* anchor point == center of an anchor box) |
| Definition of positive and negative samples | resorts to the IoU | utilizes spatial and scale constraints to select samples |
| Regression starting status | from the preset anchor box | from the anchor point |
3. Difference Analysis of Anchor-based and Anchor-free Detection
RetinaNet과 FCOS의 비교를 통해 anchor-based와 anchor-free detectors 간의 essential difference를 찾아본다.
3.1 Experiment setting
- dataset - challenging MS COCO dataset
- training detail
- backbone - ImageNet pretrained ResNet-50 w/ 5-level feature pyramid structure
- image size - shorter side는 800, longer side는 1,333 이하로
- SGD, weight decay 0.0001, 16 batch size, initial LR 0.01
- inference detail
- training phase와 동일하게 resize the input image
- preset score 0.05 → filter out plenty of background bounding boxes
- output the top 1000 detections per feature pyramid
- NMS w/ IoU threshold 0.6 → top 100 confident detections per image
3.2 Inconsistency Removal
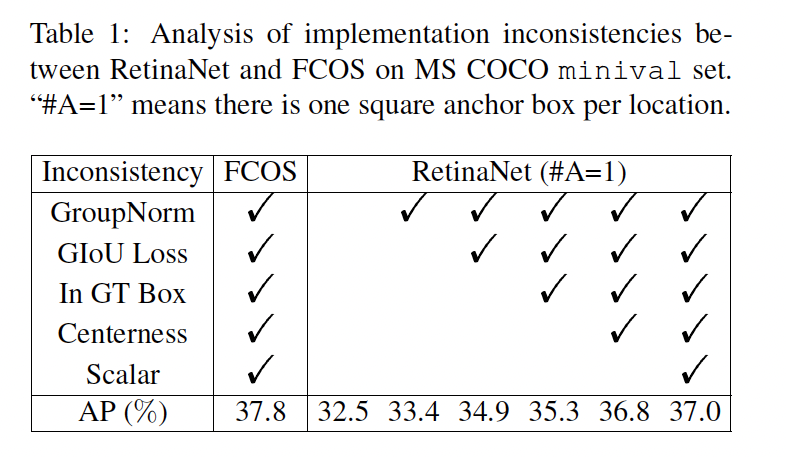
- FCOS의 특징 & 새로운 개선 사항 중 anchor-based detectors에도 적용될 수 있는 것들을 RetinaNet에도 적용하여 inconsistencies를 제거하였다.
- 기존 RetinaNet은 9 anchors per location 이지만, FCOS처럼 1 anchor per location으로 조정하였다. (⇒ RetinaNet(#A=1))
- GroupNorm, GIoU Loss 등을 RetinaNet에도 적용하였다.
- 결과적으로, anchor-free FCOS(37.8%)와 anchor-based RetinaNet(37.0%)의 essential gap은 0.8%이다.
3.3 Essential Differences
이제, anchor-based RetinaNet(#A=1)과 anchor-free FCOS의 차이점은 다음 뿐이다. 어떤 것이 essential difference 일까?
- about classification sub-task in detection
- ex) the way to define positive and negative samples
- about regression sub-task
- ex) regression starting from an anchor box or an anchor point
[1] Classification
positive / negative samples를 정의하는 방법
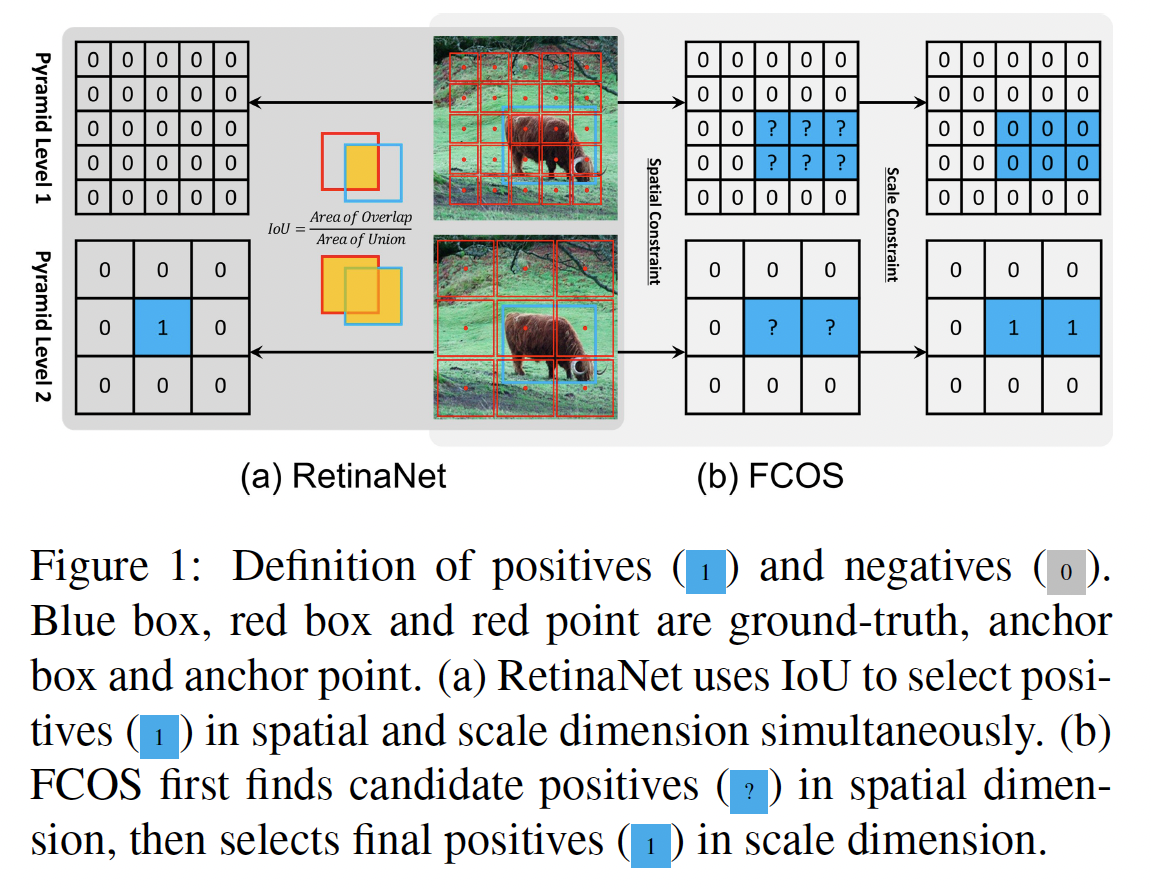
- RetinaNet
different pyramid levels에서 뽑은 anchor boxes를 positive와 negative로 나누기 위해 IoU를 사용한다.
⇒ final positives를 spatial & scale dimension에서 동시에 선택한다.
IoU가 특정 threshold (\(\theta_p, \theta_n\))를 넘지 못하면 학습 단계에서 무시된다.
- FCOS
- different pyramid levels에서 뽑은 anchor points를 positive와 negative로 나누기 위해 spatial & scale constraints를 사용한다.
- GT box 안에 있는 anchor points를 candidate positive samples로 고려한다.
⇒ candidate positives → spatial dimension(constraint)에서
selects the final positive samples from candidates based on the scale range defined for each pyramid level
⇒ final positives → scale dimension(constraint)에서
unselected anchor points are negative samples
- different pyramid levels에서 뽑은 anchor points를 positive와 negative로 나누기 위해 spatial & scale constraints를 사용한다.
이처럼 positive / negative sample을 찾는 방법이 다르다.

- RetinaNet이 spatial & scale constraint strategy를 사용한다면 - AP performance 37.0% → 37.8% (improves)
- FCOS가 IoU strategy를 사용한다면 - AP performance 37.8% → 36.9% (decreases)
the definition of positive and negative samples 는 anchor-based와 anchor-free detectors 간의 essential difference 이다.
[2] Regression
positive/negative samples가 정해지고 나면, location of obejct가 regressed from positive samples 된다.
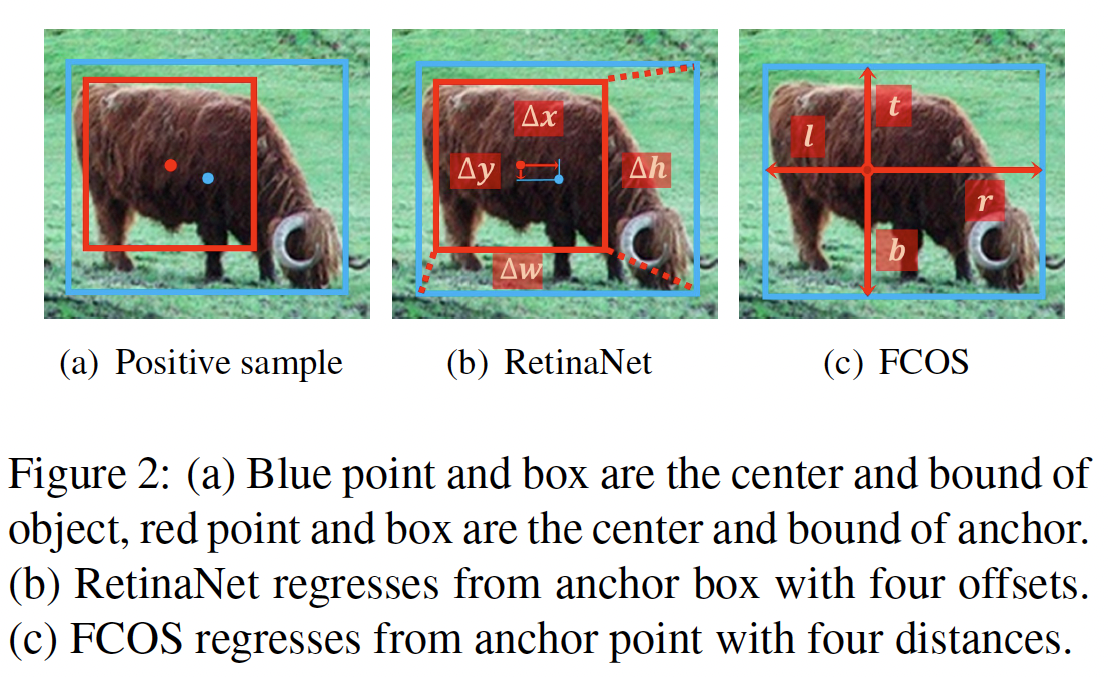
- RetinaNet
- regresses from the anchor box w/ four offsets between the anchor box and the object box
- regression starting status = a box
- FCOS
- regresses from the anchor point w/ four distances to the bound of object
- regression starting status = a point
- 하지만, RetinaNet과 FCOS가 같은 sample selection strategy to have consistent positive/negative samples를 사용한다면, regressing이 box에서 시작하든 point에서 시작하든 최종 성능에 유의미한 차이가 없다.
- 37.0% vs. 36.9%
- 37.8% vs. 37.8%

the regression starting status is an irrelevant difference rather than an essential difference
one-stage anchor-based detector와 center-based anchor-free detector의 essential difference:
“how to define positive and negative training samples”
4. Adaptive Training Sample Selection
- object detector를 학습시키려면, 우선 positive / negative samples for classification을 정하고, positive samples를 regression에 이용해야 한다.
- positives / negatives를 정의하는 새로운 방법을 소개한다.
- traditional IoU-based strategy(RetinaNet)보다 향상된 성능을 보여준다.
ATSS (Adaptive Training Sample Selection)
- almost has no hyperparameters
- robust to different settings
4.1 Previous Sample Selection Strategies
- some sensitive hyperparameters가 필요하다.
- anchor-based detectors: IoU thresholds 등
- anchor-free detectors: scale ranges 등
hyperparameter가 다 설정되면, all GT boxes는 고정된 rule에 의해 their positive samples를 선택해야 한다.
대부분의 object에는 suitable 하나, some outer objects는 neglected 된다.
- 따라서 hyperparemter setting에 따라 결과가 달라진다.
4.2 ATSS(Adaptive Training Sample Selection) method
positive / negative samples를 object의 통계적 특성을 통해 거의 자동적으로(= hyperparameter 없이) 나누는 방법이다.

image의 각 GT box \(g\)에 대해서, 그것의 candidate positive samples를 찾는다.
→ spatial dimension
- 각 pyramid level에 대해서, center of \(g\)와 center 간의 L2 distance가 가장 가까운 \(k\) anchor boxes를 선택한다.
- \(\mathcal L\) feature pyramid levels라면, GT box \(g\)는 \(k \times \mathcal L\) candidate positive samples를 가지게 된다.
- 이러한 candidates와 GT \(g\) 간의 IoU \(\mathcal D_g\)를 계산한다.
- 이것의 mean은 \(m_g\), standard deviation은 \(v_g\) (⇒ statistics)
candidates 중 IoU가 threshold \(t_g\) 이상인 것들을 final positive samples로 선택한다.
→ scale dimension
- IoU threshold for this GT \(g\)는 \(t_g=m_g+v_g\) 로 구한다.
- positive samples의 center가 GT box 안에 있는 경우에만 선택한다.
- 만약 anchor box가 multiple GT boxes에 assigned 되었다면, highest IoU를 가진 것이 선택된다.
- positive sample로 선택받지 못한 나머지 anchors는 negative samples가 된다.
[1] anchor box - object 간 center distance 기반으로 candidates를 선택하는 이유
- RetinaNet - center of anchor box와 center of object가 가까울 때 IoU is larger
- FCOS - closer anchor point to the center of object가 produce higher-quality detections
- 따라서 closer anchor to the center of object가 better candidate 이다.
[2] IoU threshold로 mean + standard deviation을 사용하는 이유
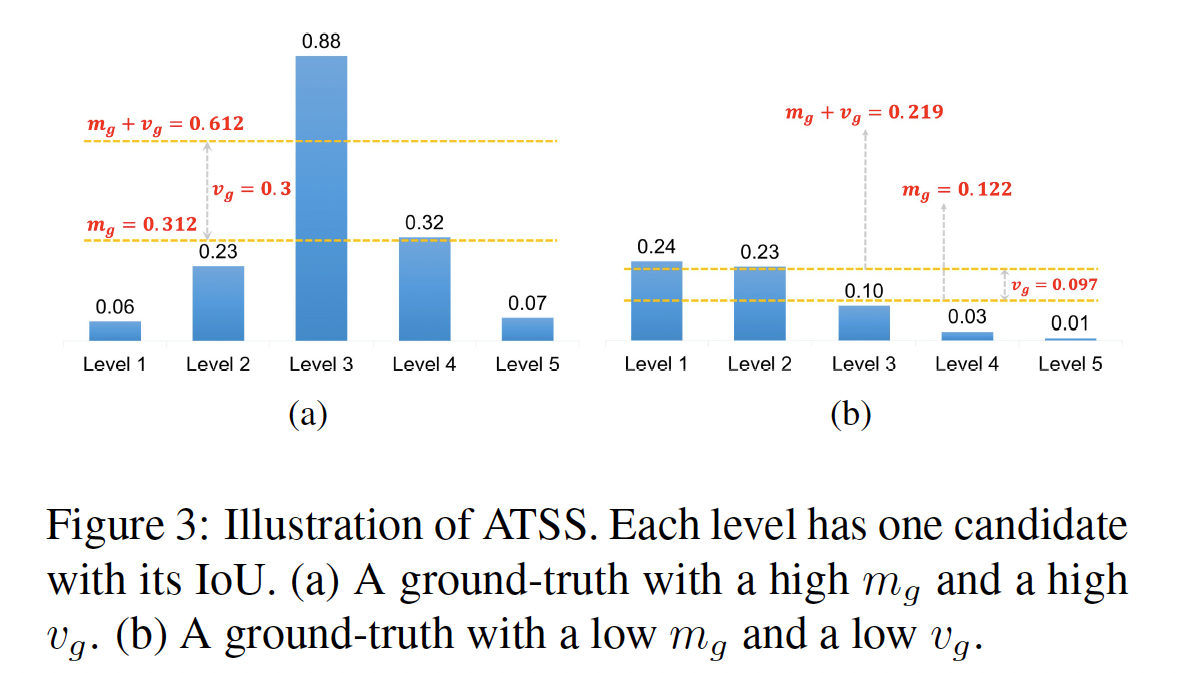
- IoU mean \(m_g\) of an object - a measure of suitability of th epreset anchors for this object
- high \(m_g\): high-quality candidates / IoU threshold is supposed to be high
- low \(m_g\): low-quality candidates / IoU threshold should be low
- IoU standard deviation \(v_g\) of an object - a measure of which layers are suitable to detect this object
- high \(v_g\): 해당 object에 suitable한 pyramid level이 존재한다.
- \(v_g+m_g\)을 threshold로 사용한다는 것 = high threshold to select positives only from that level 을 나타낸다.
- low \(v_g\): several pyramid levels suitable for this object
- \(v_g+m_g\)를 threshold로 사용한다는 것 = low threshold to select appropriate positives from these levels
- high \(v_g\): 해당 object에 suitable한 pyramid level이 존재한다.
- 이처럼, sum of mean \(m_g\)과 standard deviation \(v_g\)를 IoU threshold \(t_g\)로 사용하는 것은 object의 통계적 특성에 따라 적절한 pyramid levels에서 positives를 adaptively 하게 선택할 수 있도록 하는 것이다.
[3] almost hyperparameter-free
- 본 방법에 사용되는 hyperparameter는 anchor box의 개수인 \(k\) 뿐이다.
- 또한, \(k\) 값에 대해 insensitive 하므로 almost hyperparameter-free라고 간주할 수 있다.
4.3 Verification
RetinaNet과 FCOS의 sample selection strategy를 ATSS로 바꿔보고, ATSS의 effectiveness를 anchor-based와 anchor-free로 나누어 살펴본다.
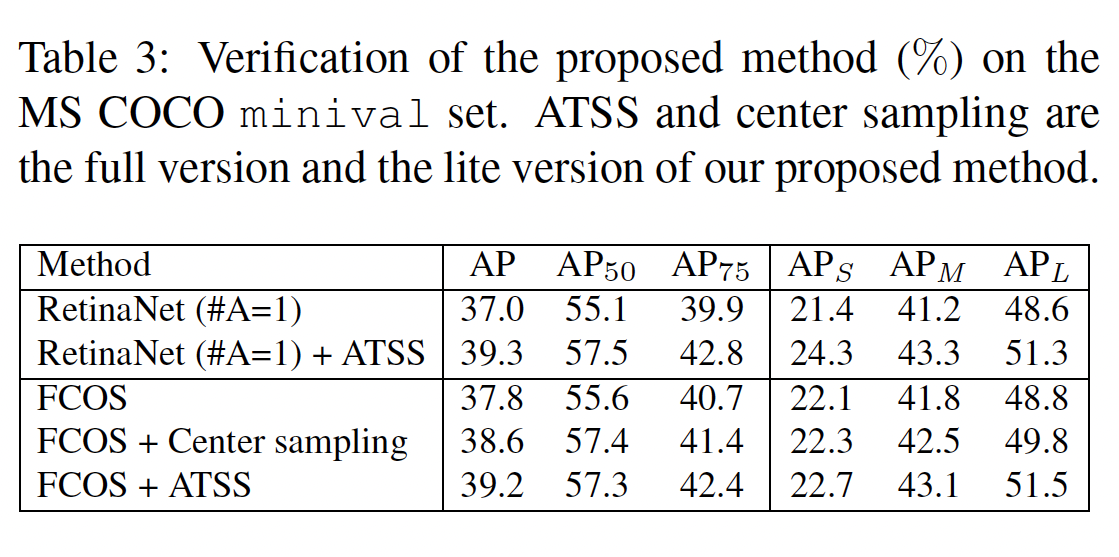
- Anchor-based RetinaNet에 적용 - improve RetinaNet (#A=1)을 사용한다.
- 성능이 향상되었다. (adaptive selection of positive samples for each GT based on its statistical characteristics)
- positive / negative samples를 additional overhead 없이 재정의하므로 이 improvements는 cost-free라고 볼 수 있다.
- Anchor-free FCOS에 적용 - 두 가지 version으로 가능하다.
- lite version (center sampling): candidate positives를 선택하는 방법만 ATSS로 적용
- FCOS - anchor points in the object box를 candidate로 간주 (plenty of low-quality positives)
- ATSS - top(closest) k=9 candidates per pyramid level for each GT를 선택
- 37.8% → 38.6% on AP
- 하지만 여전히 hyperparameters of scale ranges가 존재한다.
- full version (ATSS): anchor box 도입
- FCOS - anchor point
- ATSS - anchor box w/ 8S scale to define positive and negative samples, then regress these positive samples to objects
- significantly increases the performance (outperforms the lite version)
두 버전의 공통점 same candidates selected in the spatial dimension 두 버전의 차이점 different ways to select final positives from candidates along the scale dimension - lite version (center sampling): candidate positives를 선택하는 방법만 ATSS로 적용
4.4 Analysis
ATSS는 only involves on hyperparameter \(k\)와 one related setting of anchor boxes
Hyperparameter \(k\)
each pyramid level에서 candidate positive samples를 뽑을 때 사용

- too large \(k\) ⇒ too many low-quality candidates
- too small \(k\) ⇒ too few candidate positive samples → statistical instability
- \(k\)가 7 ~ 17 인 경우, 성능이 꽤나 insensitive 하였다.
- quite robustness & can be enarly regarded as hyperparameter-free
Anchor Size
ATSS는 resorts to the anchor boxes to define positives
- (이전 실험) one square anchor with 8S(S = the total stride size of the pyramid level) is tiled per location
different scales of the square anchor - performances are quite stable
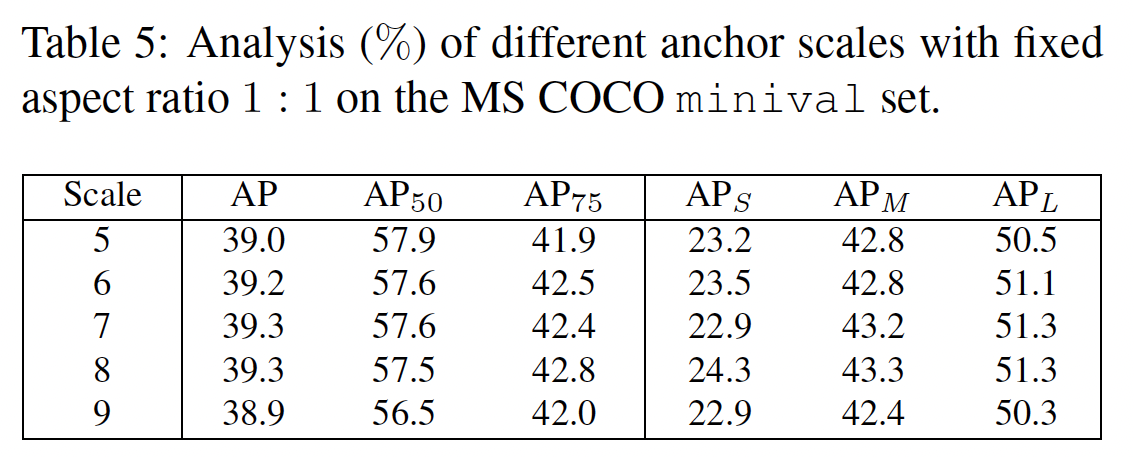
different aspect ratios of the 8S anchor box - insensitive to this variation
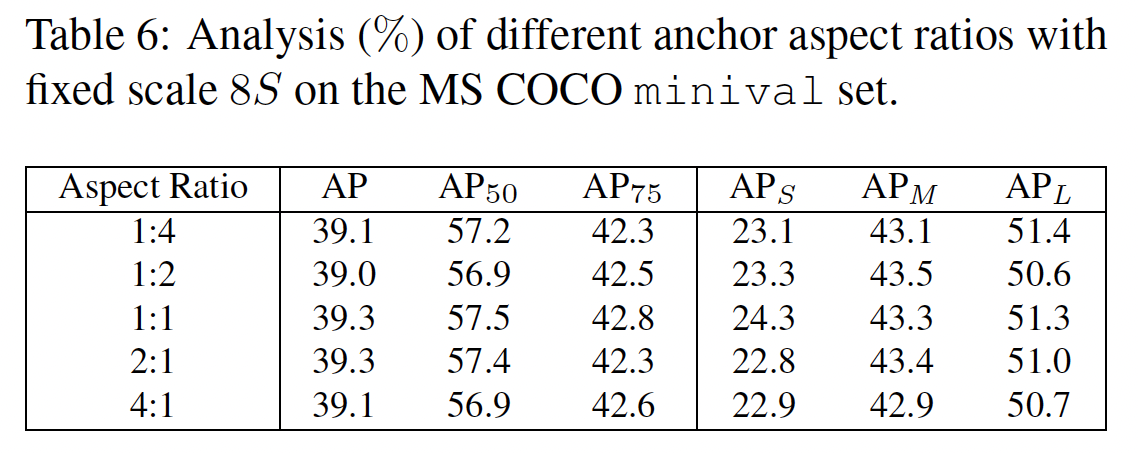
ATSS는 different anchor settings에 대해 robust 하다.
4.5 Comparison
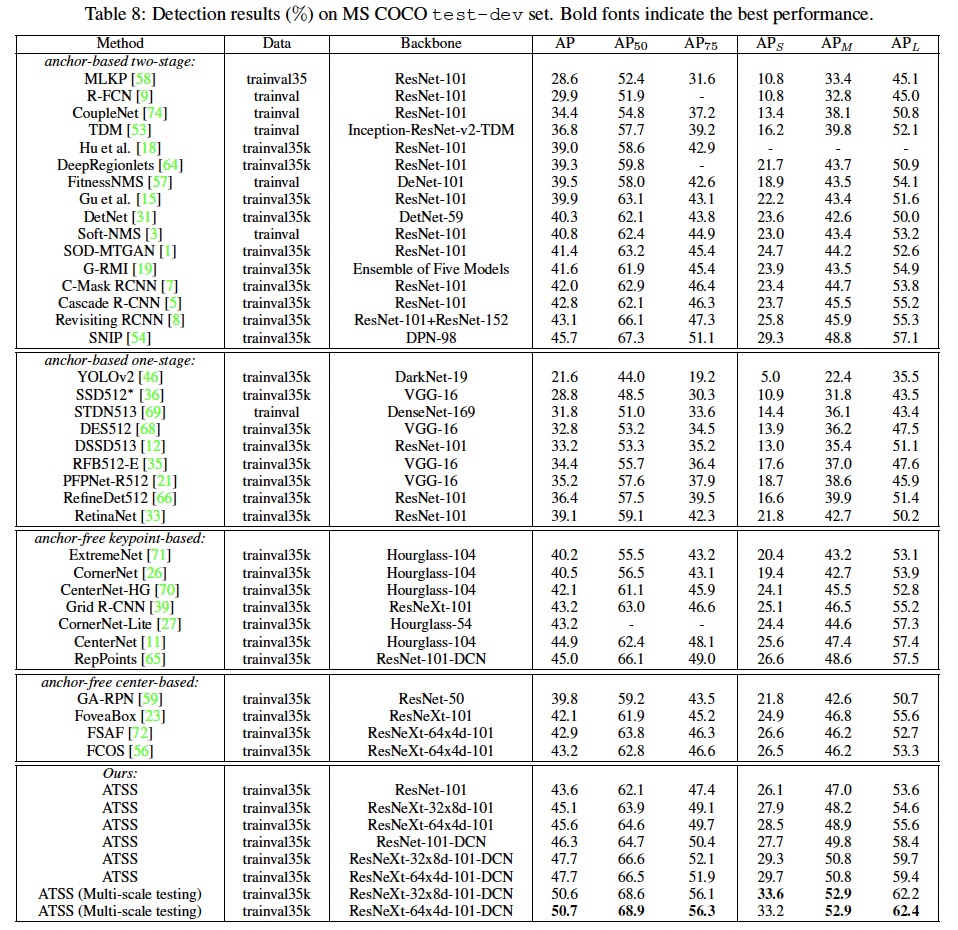
- 다른 methods와 같은 backbone 모델을 사용했음에도 불구하고 Cascade R-CNN, C-Mask RCNN, RetinaNet 등의 성능을 앞질렀다.
- further improve (w/ larger backbone)로 성능을 더 높일 수 있다.
당시의 all the anchor-free and anchor-based detector보다 성능이 좋았다. (SNIP 제외하고. 0.1% lower)
- ATSS는 positive / negative samples의 정의에 관한 것이므로, 대부분의 다른 기법에 compatible & complementary 하다.
- DCN(Deformable Convolutional Networks)도 사용해본 결과, AP가 또 증가했다. (single-model & single-scale testing)
- multi-scale testing strategy까지 적용하니 50.7% AP까지 달성할 수 있었다.
4.6 Discussion
anchor-based 와 anchor-free의 difference 중 아직 다루지 않은 것:
the number of anchors tiled per location
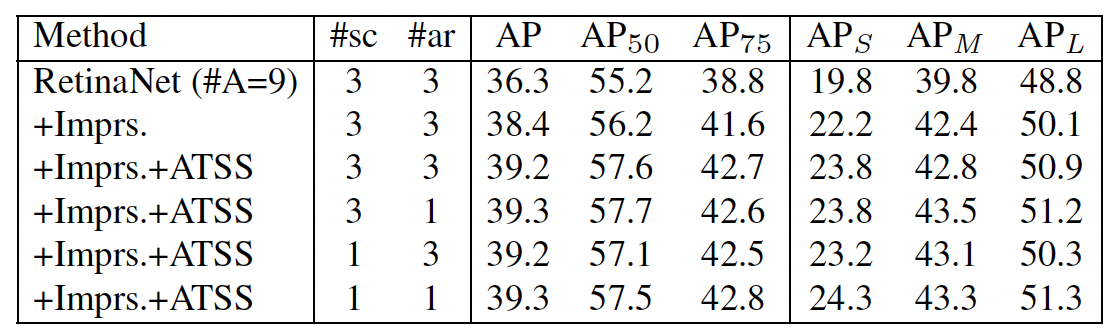
- 지금까지 실험들은 FCOS와의 비교를 위해 RetinaNet(#A=1, one anchor per location)로 진행했다.
- 원래의 RetinaNet은 (#A=9), 즉, 9 anchors per location (3 scales × 3 aspect ratios)이다.
- table 1의 universal improvements 적용하면 AP performance 향상된다.
- ATSS 사용하지 않고서도 이 improved RetinaNet(#A=9)(38.4%)가 RetinaNet(#A=1)(37.0%)보다 성능이 좋았다.
- 즉, traditional IoU-based sample selection strategy를 사용한다면, tiling more anchor boxes per location은 효과적이다.
- 하지만 ATSS를 사용한다면?
- improved RetinaNet(#A=9)와 RetinaNet(#A=1)에 모두 ATSS를 적용해봤을 때, 비슷한 성능을 보인다. (3, 6 line)
- number of anchor scales나 aspect ratios를 3에서 1로 바꾸어보아도 성능에 크게 변화가 없다. (line 4, 5)
즉, positive samples가 적절하게 선택되기만 한다면, 각 location마다 얼마나 많은 anchor를 두는지와는 상관 없이 결과는 같다.
→ ATSS를 사용한다면, tiling multiple anchors per location은 useless operation이다.
5. Conclusion
one-stage anchor-based와 center-based anchor-free detector의 essential difference는 positive / negative training samples를 정의하는 방법이다.
ATSS는 object의 통계적 특징을 이용하여 자동으로 positive / negative training samples를 나눈다.
→ bridging the gap between anchor-based and anchor-free detectors
ATSS를 사용한다면 tiling multiple anchors per location이 유용한 도구가 아닐 수 있다.
ATSS를 통해 overhead 없이 detection 분야에서의 SOTA performance를 이룰 수 있다.