[DEVIEW 2023] ML/AI 개발자를 위한 단계별 Python 최적화 가이드라인 (NAVER Cloud) 정리
발표 자료 및 영상: https://deview.kr/2023/sessions/541
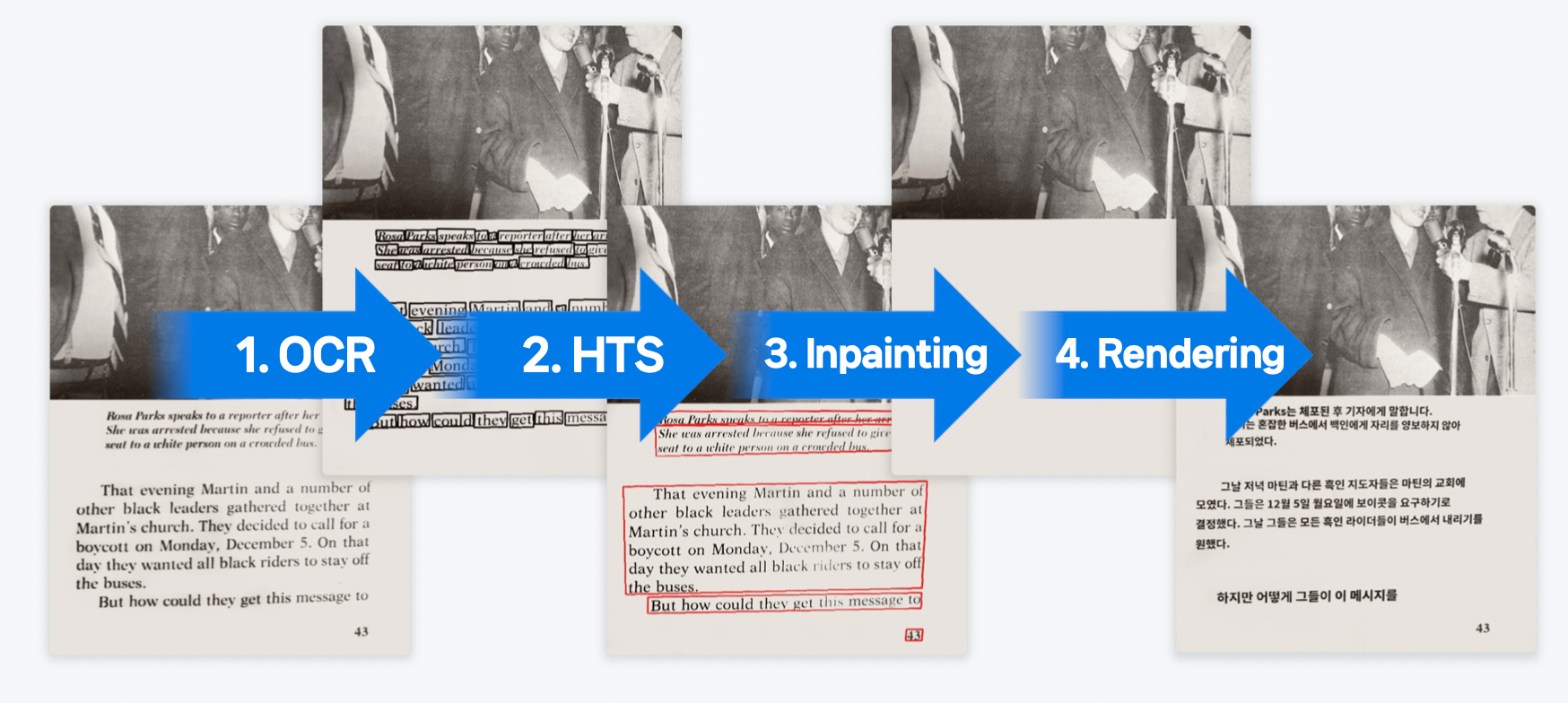 파파고 이미지 번역 과정
파파고 이미지 번역 과정
한 장의 이미지를 번역하기 위해…
입력 형태가 각기 다른 여러 ML/AI 모델이 투입된다.
모델별로 input/output 형태가 달라 전/후처리가 필요하므로, CPU 처리가 병목이 되기도 한다.
렌더링의 경우, ML로 대체되지 못했다.
GPU, ML 모델, Quantization & Transformation, 네트워크 통신 관련 최적화가 아닌, ML/AI 개발자가 직접 해야하는 CPU 최적화에 대한 내용을 다뤄보자.
1. Python 프로파일링: Line Profiler
코드 내에서 어디가 가장 오래 걸릴까?
→
time.time()으로 찾을 수 있으나 귀찮다.
Line Profiler
- Python에서의 line-by-line profiling을 제공한다.
설치 방법
1
pip install line_profiler- 사용 방법
- 타겟 함수
def위해@profile을 명시한다. terminal -
kernprof -l -v my_code.py와 같이 실행한다.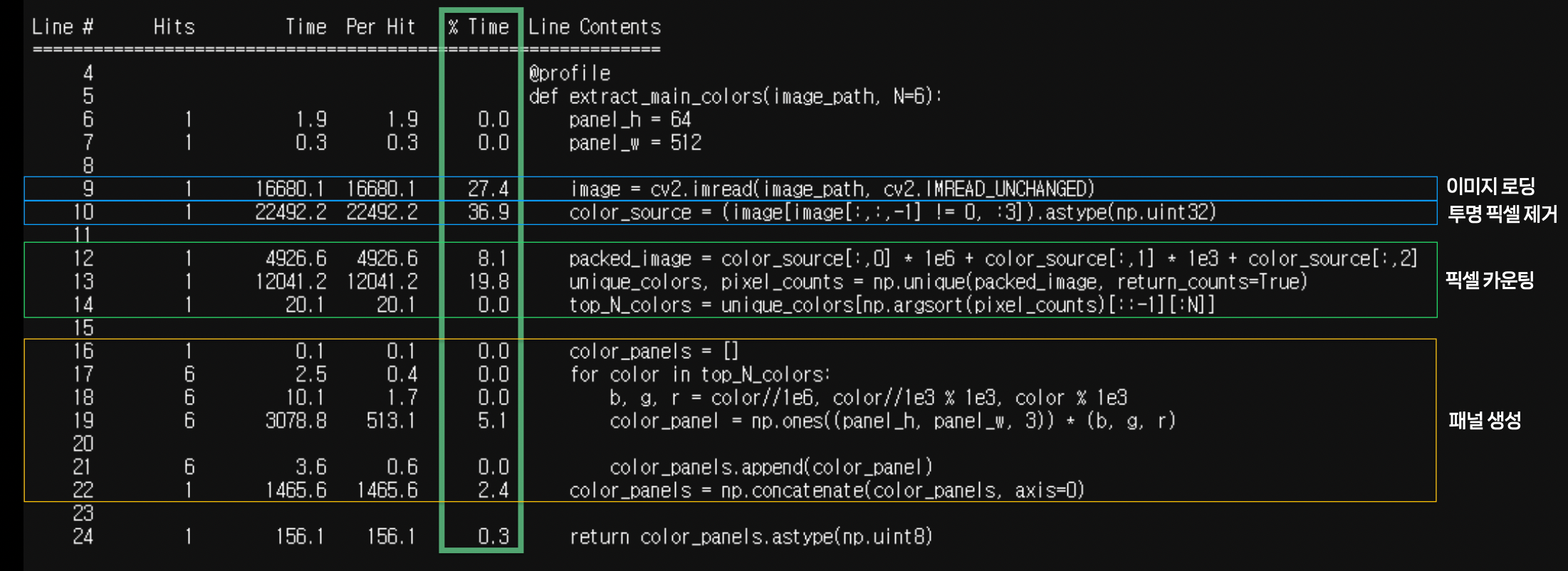
jupyter notebook
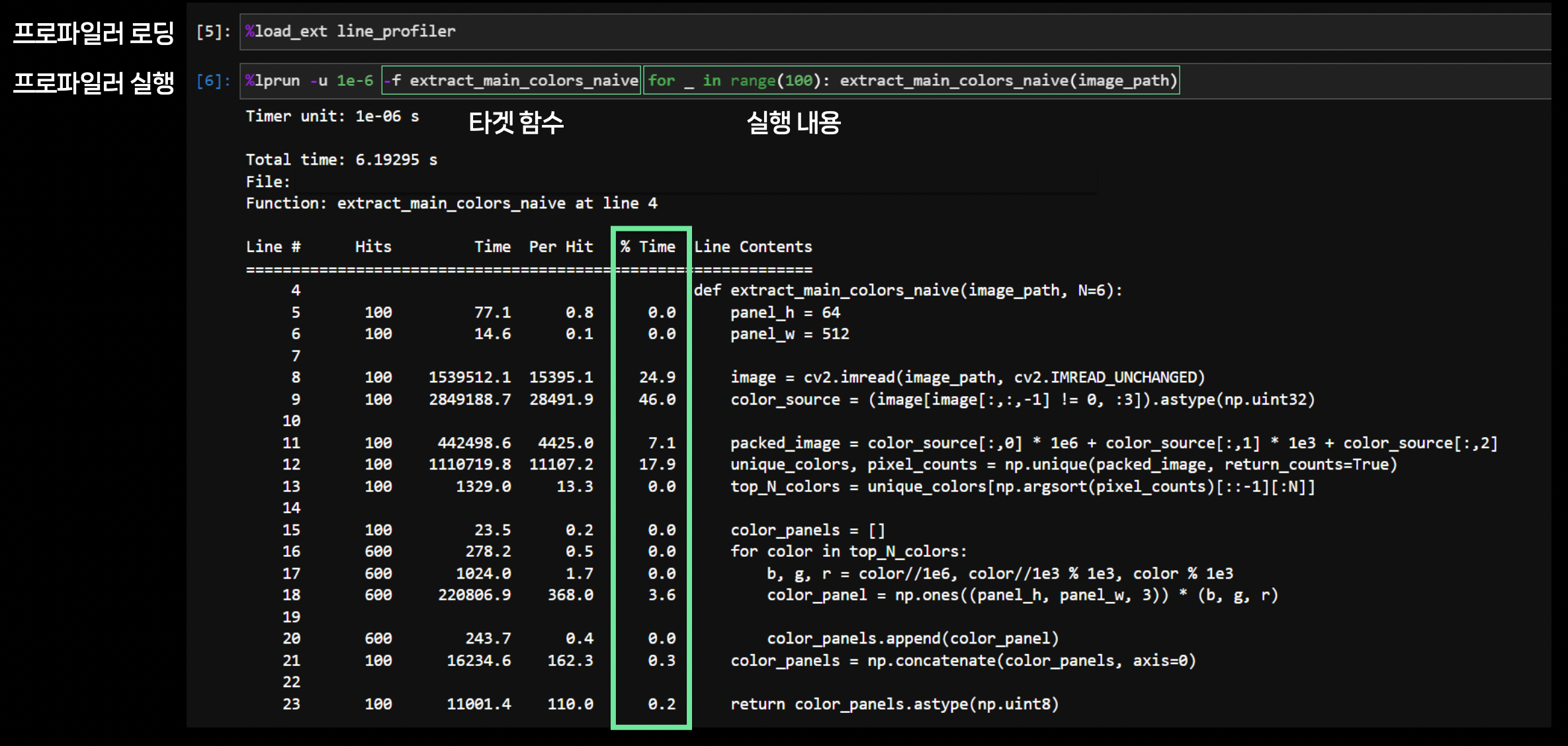
- 타겟 함수
2. Python Level 최적화: NumPy, OpenCV 더 빠르게 쓰기
프로파일링을 통해 수정할 부분을 타겟팅한다.
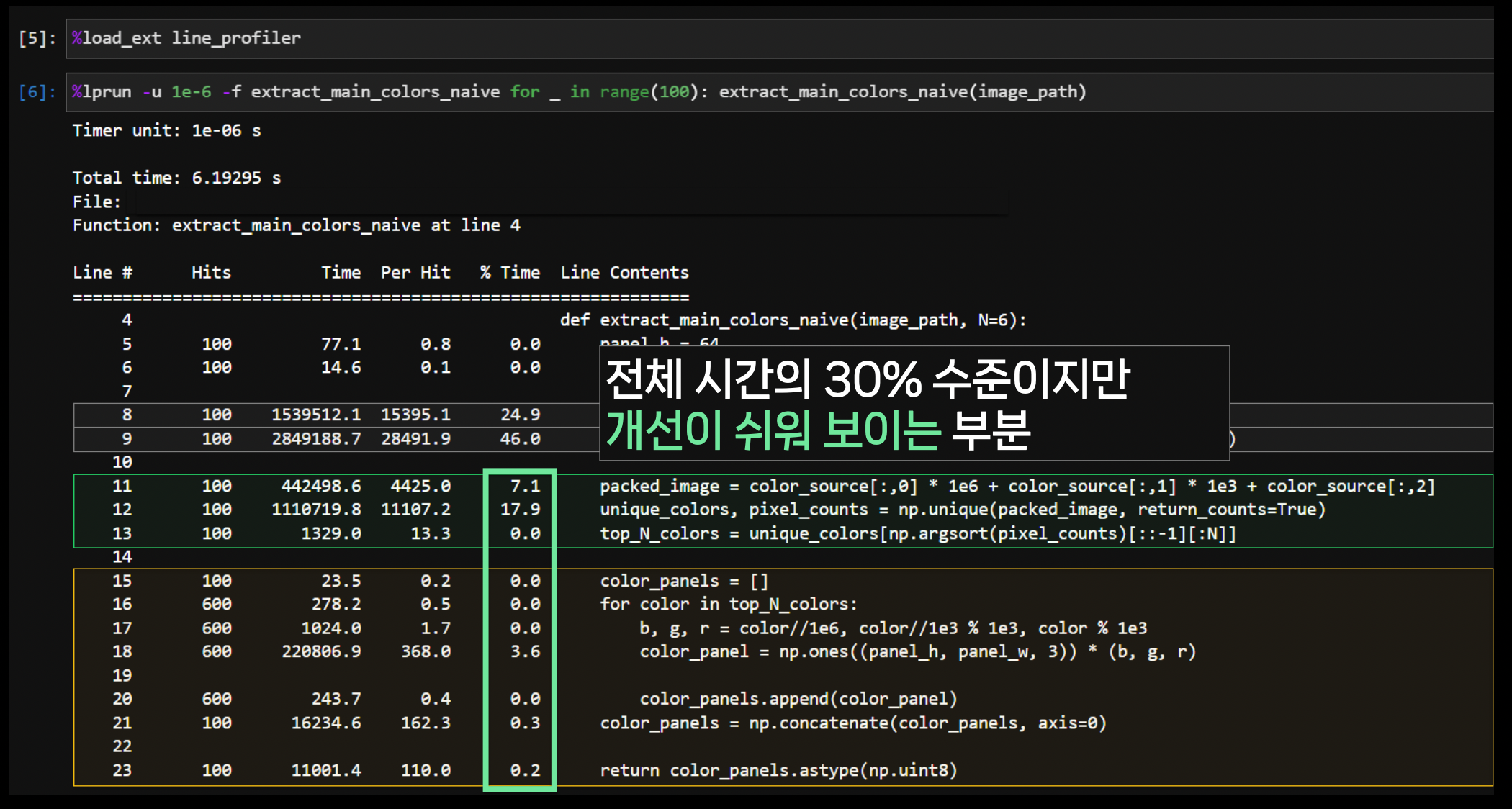
- 동일 출력이지만 더 빠른 연산을 조사한다.
- 더 빠른 연산이 같은 라이브러리 내에 존재할 수 있다.
- 10진수가 아닌 16진수를 이용하여 bit 연산을 사용할 수도 있다.
결과를 관찰한다.
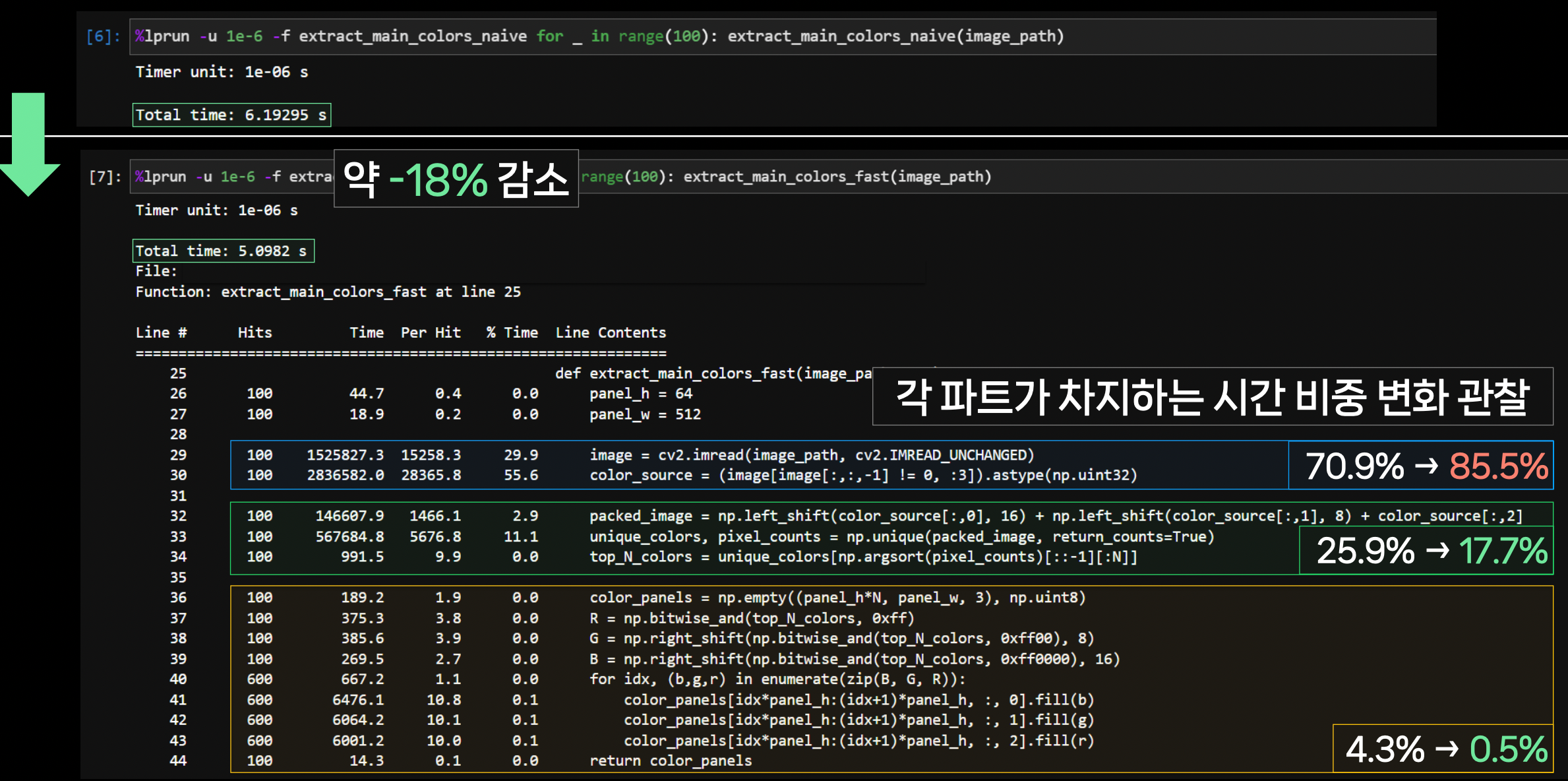 이제 미뤄뒀던 85.5% 부분을 고쳐보자…
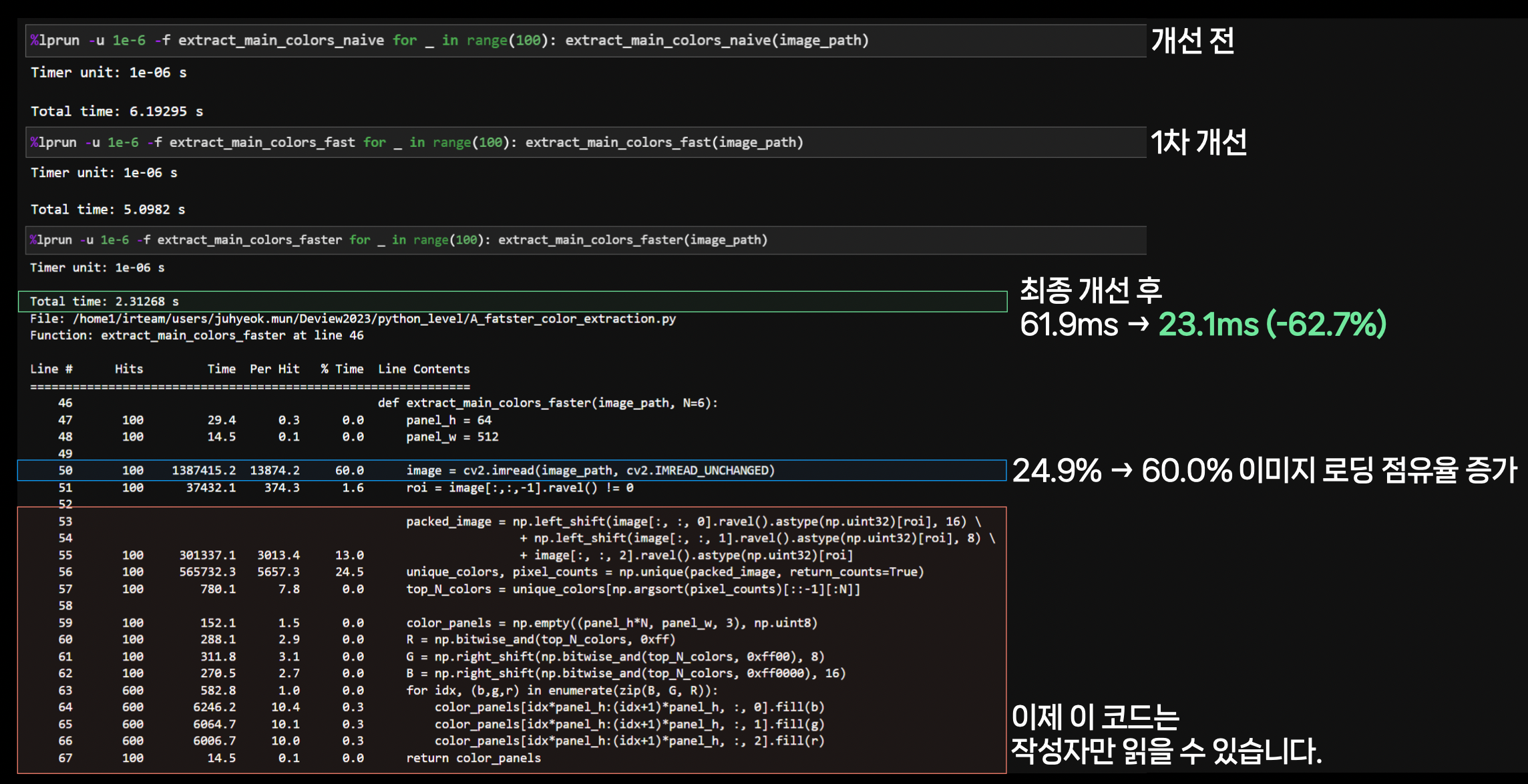
이제 미뤄뒀던 85.5% 부분을 고쳐보자…만족스러울 때까지 반복한다.
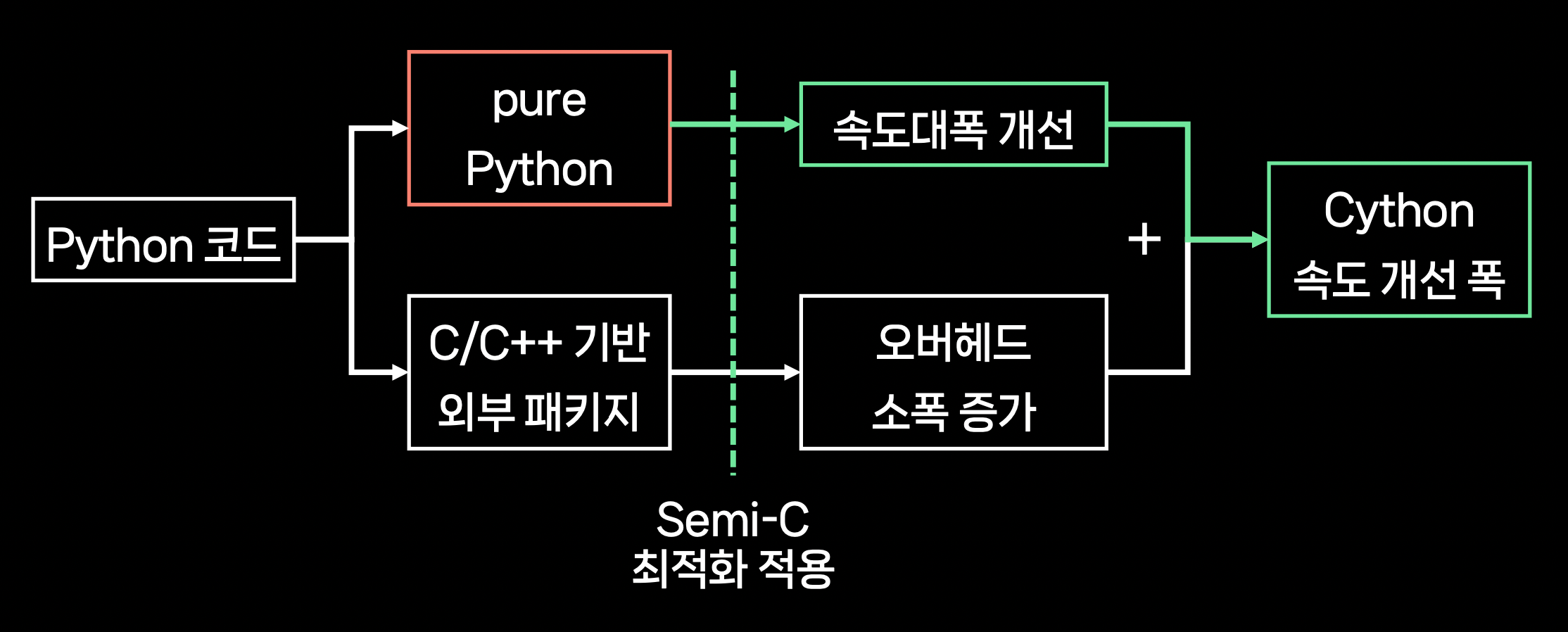
3. Semi-C Level 최적화: Cython, Numba가 유용한 경우
- Cython, Numba는 코드 내 pure Python 구현의 비중이 큰 경우에만 유용하다.
- 외부 패키지를 많이 사용한다면 다른 방법을 찾아보자.
4. C/C++ Level 최적화: Python/C API 어디까지 가능한가
Python/C API
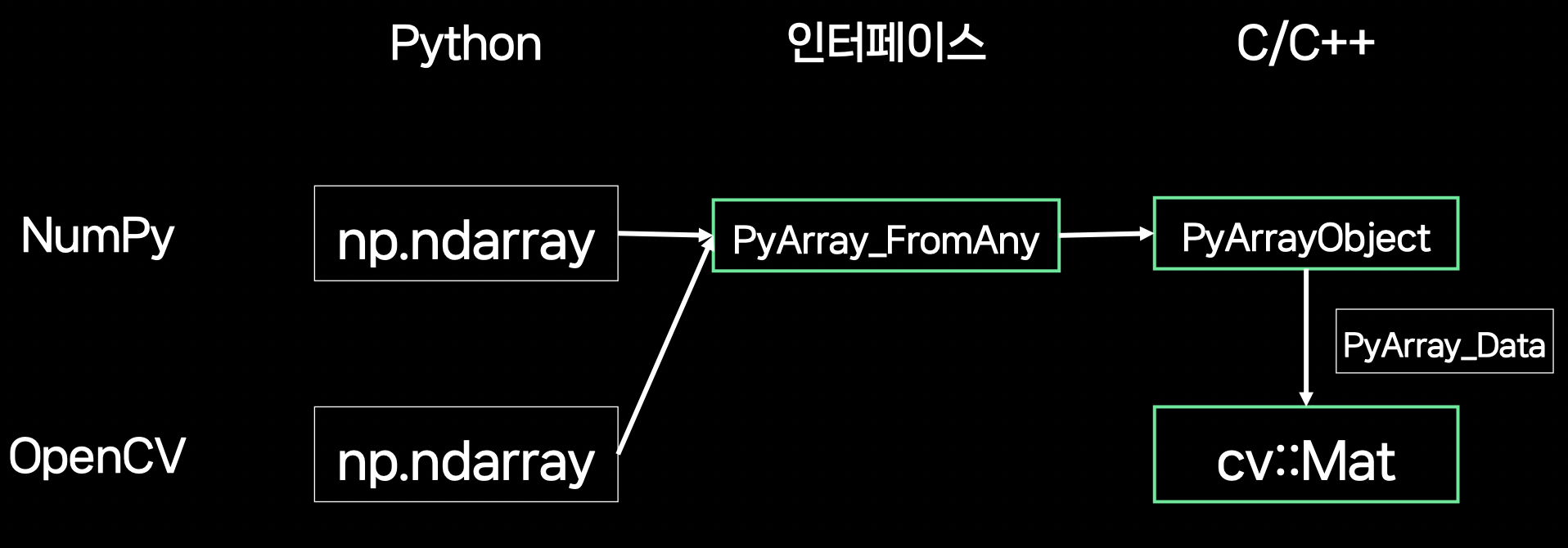
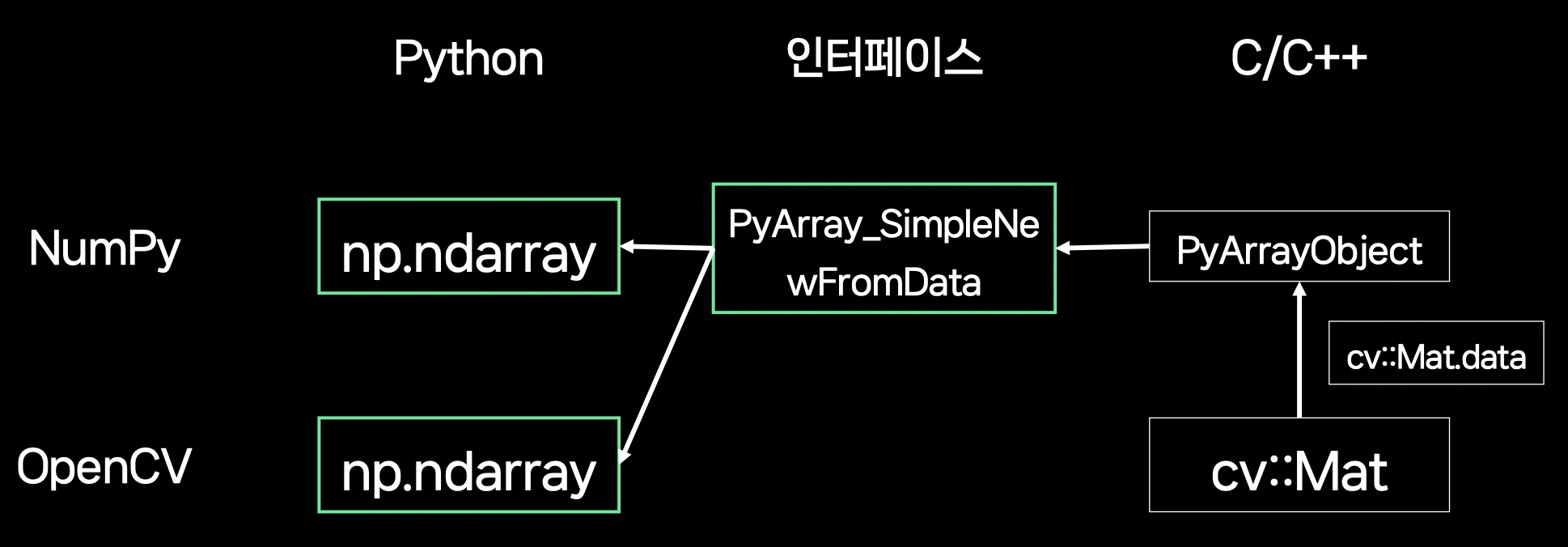
= Python ↔ C/C++ 데이터 인터페이스
- 데이터 타입
- document의 내용은 Python 기본 타입에 충실하다.
NumPy, OpenCV 등에서 사용되는 타입에 대해서는 다음과 같이 하면 된다. (ex.
np.ndarray↔cv::Mat)
OCR 적용 예시
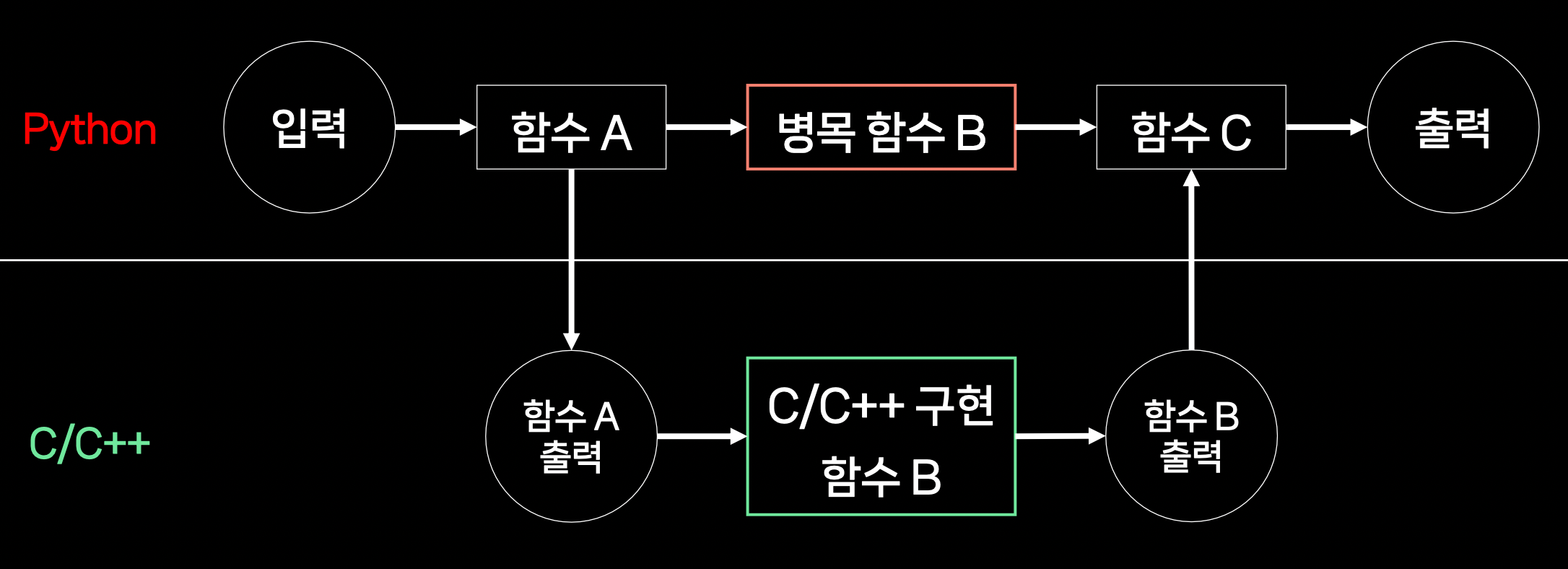
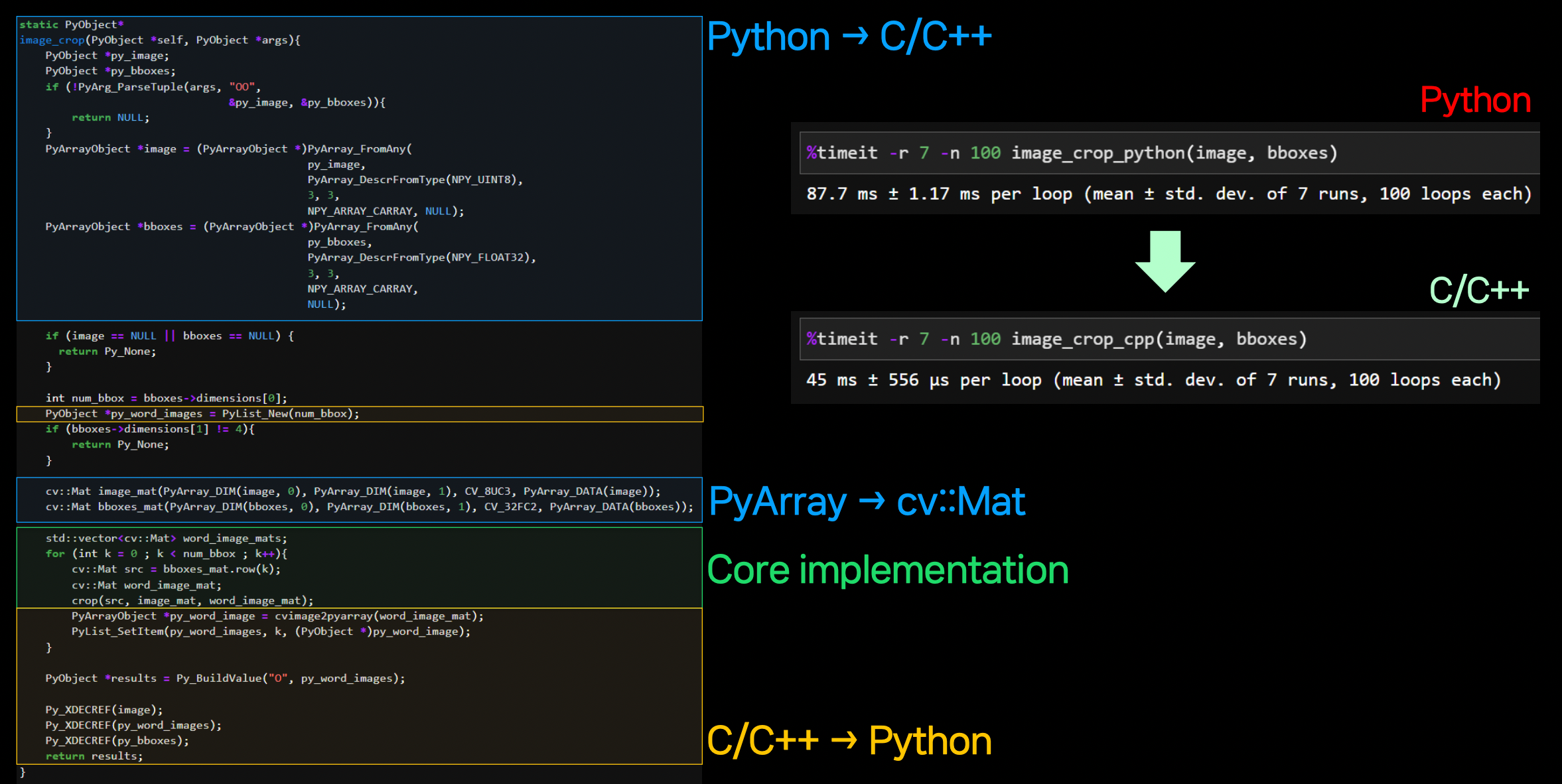
OCR은 보통 검출기 / 인식기의 2-stage로 구성된다. 정방향 글자의 인식이 더 쉽기 때문에, 검출 시 bbox가 기울어지지 않도록 warp를 이용하여 crop하게 된다.
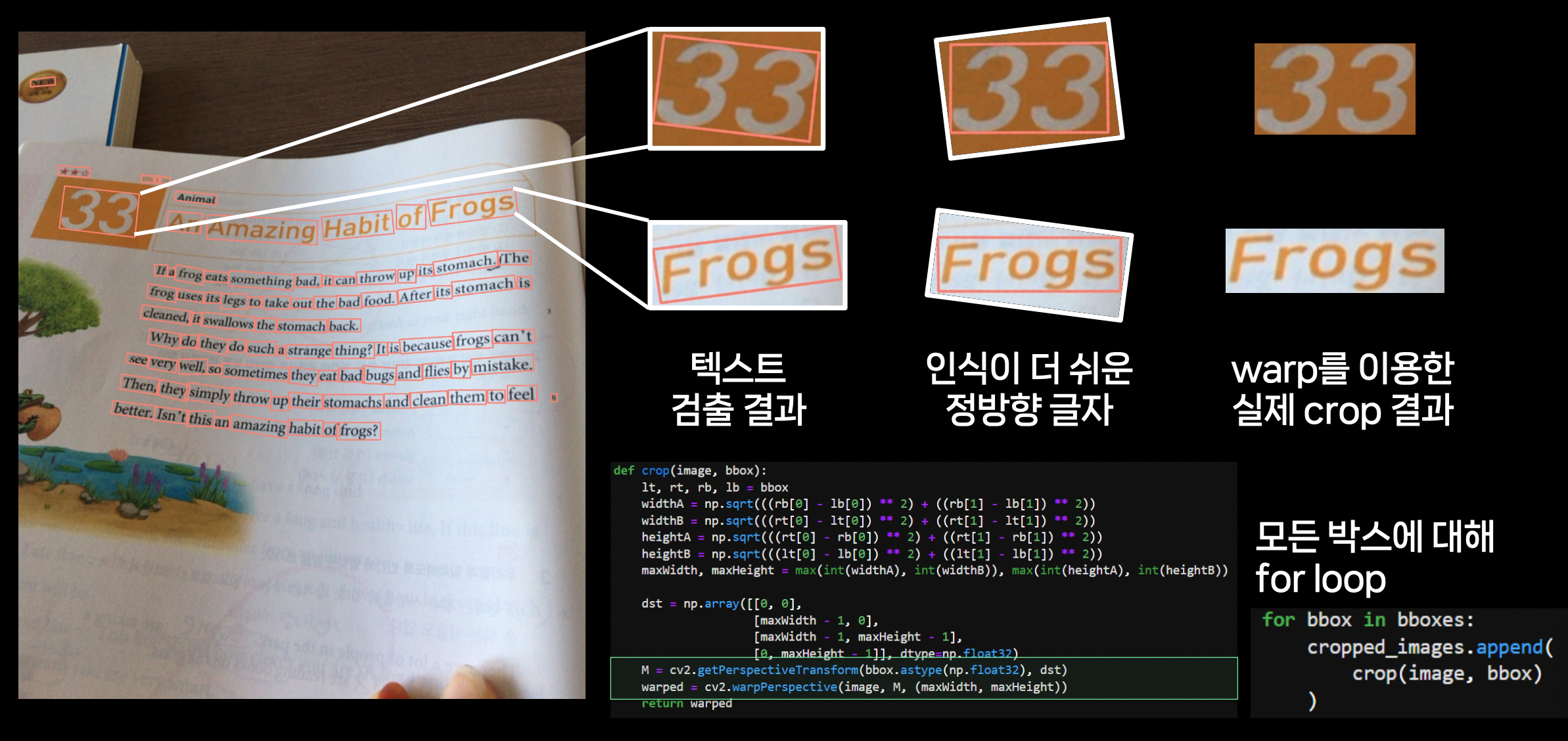
해당 과정을 모든 bbox에 대해 for loop으로 돌게 되는데, 각각의 crop이 독립적이므로 병렬처리를 하고 싶지만, Python을 사용하기 때문에 원본 이미지가 GIL에 묶여있어 동시에 접근이 불가능하다.
GIL로 인해 한 번에 한 thread 밖에 처리할 수 없다. thread 마다 원본 이미지를 복사하면 가능은 하지만 시간 소요가 커지게 된다.
해당 동작을 C/C++로 구현하여 병렬처리를 가능하게 한다. 같은
opencv라이브러리를 사용하므로 구현 내용이 크게 달라지지 않는다.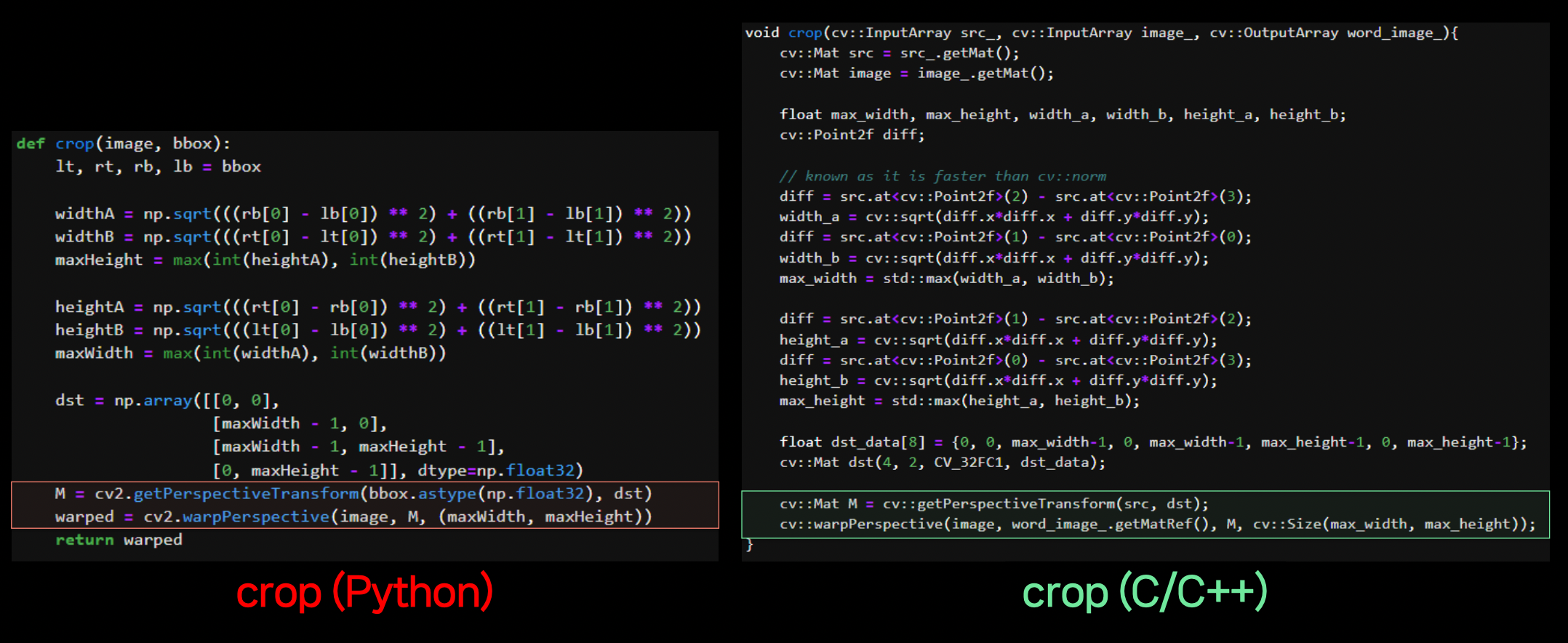
Python ↔ C/C++ 간 data를 주고 받는 interfacing 부분을 구현한다. (처음에만 어렵고 한 번 작성해두면 편하다.)
core implementation 위아래로
OpenMP구문을 추가한다. (병렬처리)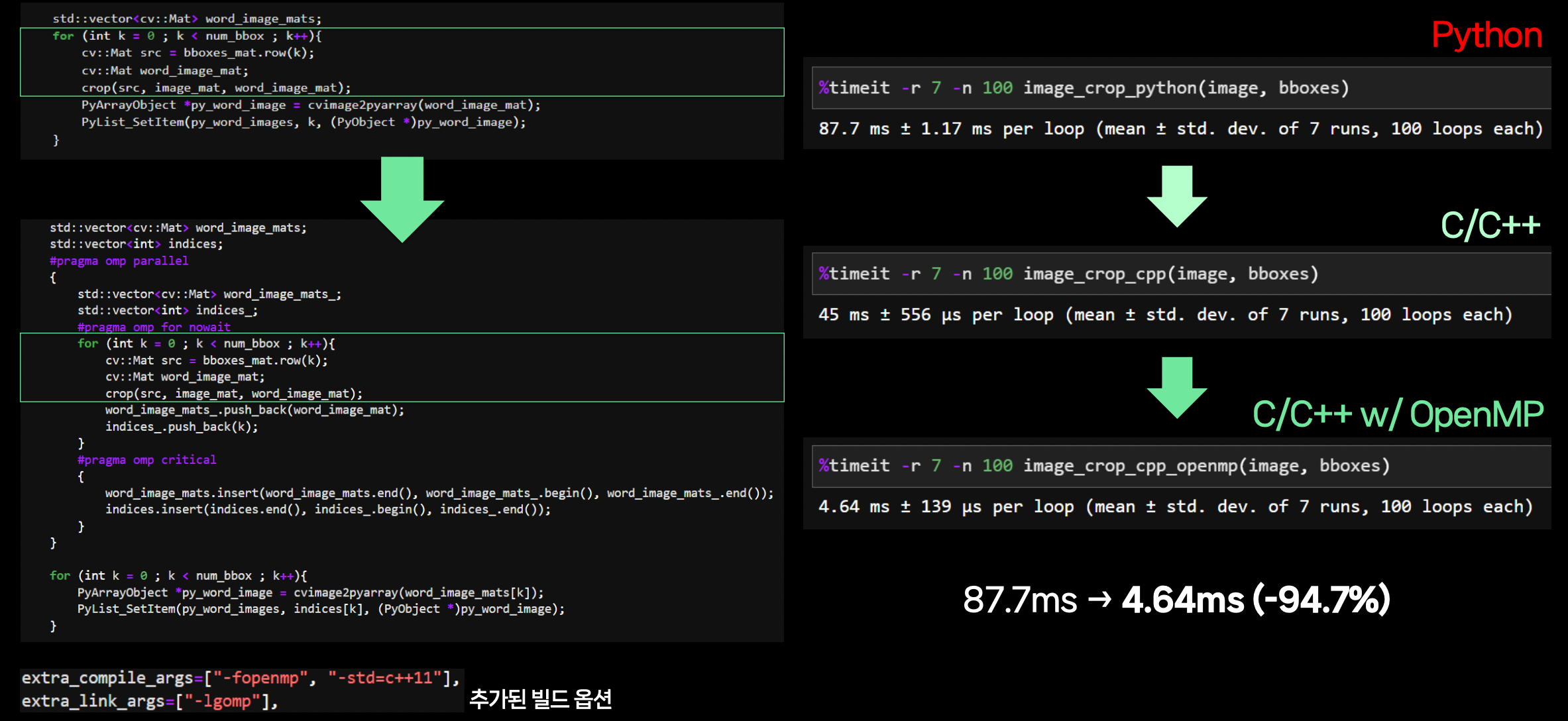
5. 코드 외적인 요소 최적화
- container 환경에서 CPU가 제한되어 있다면
omp_num_threads환경변수를 CPU 제한량에 맞추어 설정한다.- docker의 경우
--cpus옵션 omp_num_threads는 NumPy, PyTorch 등 내가 OpenMP를 직접 사용하지 않은 곳에서도 영향을 미친다.
- docker의 경우
- PyTorch에서 GPU 변수 생성 시 CPU 변수를 거치고 있지는 않은지 확인한다.
PyList_Setitemvs.PyList_SET_ITEM등 유사하지만 레퍼런스 관리를 달리하는 API를 꼼꼼히 살펴봐야 memory leak를 피할 수 있다.- Intel Memory Latency Checker를 이용하여 메모리 속도에는 문제가 없는지 확인한다.
nvidia-smi에서Persistence-Mode가on으로 설정되어 있는지 확인한다.- GPU에 부하가 결렸을 때,
nvidia-smi에서Perf가P0인지 확인한다. - …
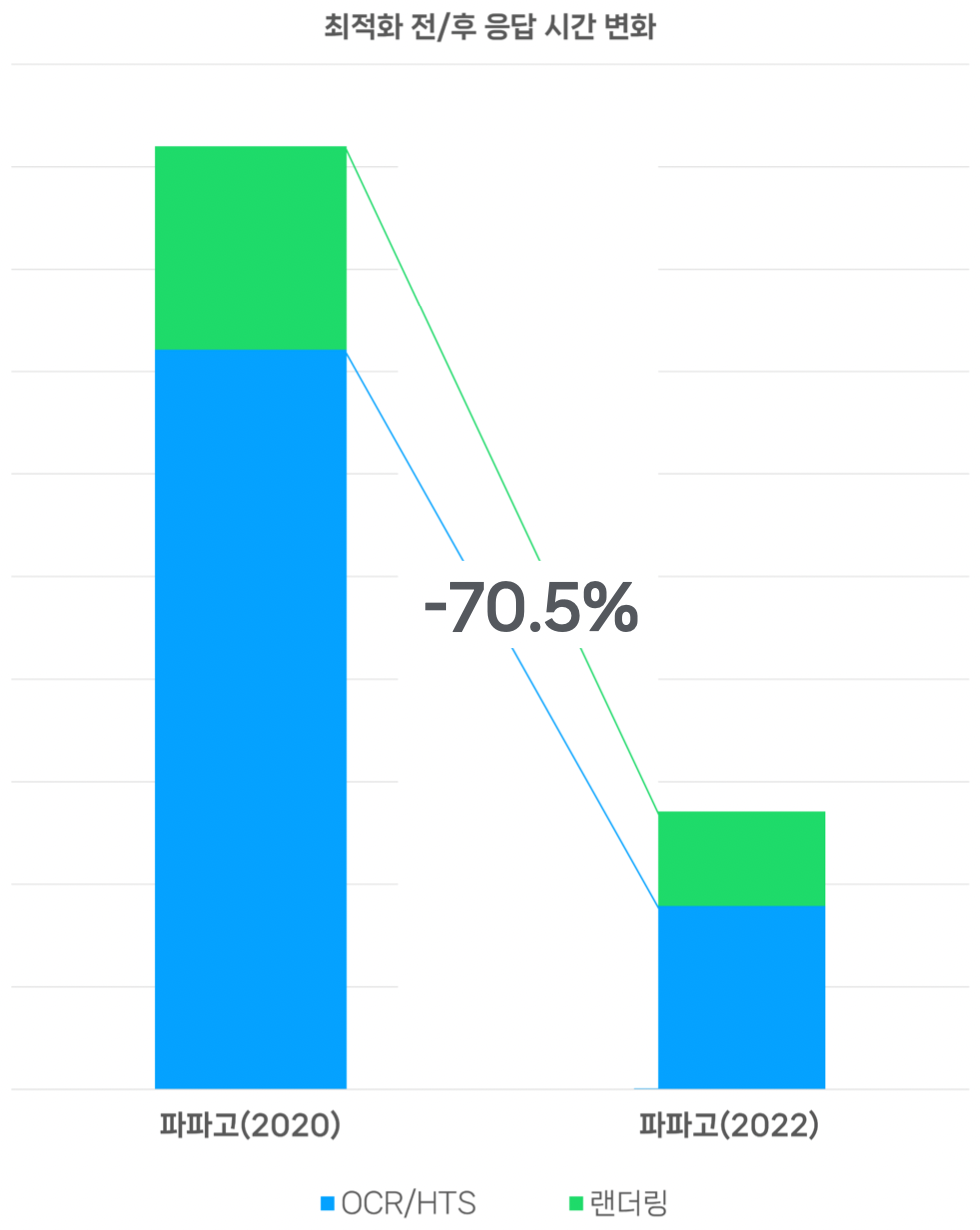
6. 요약
- 프로파일링 - 쉬운 프로파일링 툴을 사용하더라도 병목 구간을 찾아보자.
- Python 최적화: Python 패키지 - 같은 출력을 내는 여러 문법을 비교하여 병목 구간을 더 빠르게 바꿔보자.
- Semi-C 최적화: Cython/Numba - pure Python의 비중이 큰 경우에만 유용하다.
- C/C++ 최적화: Python/C API - 자유로운 병렬처리가 가능해진다. C/C++에 입문해보자.
7. Q&A
- profiler 자체의 overhead?
- 속도가 느려져서 overhead가 걸리긴 하지만, 모든 line에 동일하게 걸린다.
- 병목 부분을 찾는 데에 유용하다.
- 최종 실제 걸리는 시간은
time모듈로 측정하면 된다.
- C 포팅 → 메모리 관리는?
- 어려운 부분이므로 공부해야 한다.
- Python ↔ C 데이터 주고 받을 때 병목?
- overhead가 미미하다. (deep copy 하지 않는 이상)
- 멀티 프로세싱을 통한 최적화를 자주 하는지?
- 웬만하면 사용하려고 하나 GIL 때문에 복사해야하는 경우만 아니면, 외부 API & text 데이터 정도는 괜찮다.
- PyTorch에서도 line profiler를 사용하려면?
async관련 연산에 주의한다. pytorchsynchronize를 걸어서 확인해야 한다.
메모
- CPU 최적화에 대한 관심
- 지금까지 나는 프로파일러를 시간 측정 정도로만 사용했지, 병목 지점을 찾아 개선해보지는 않음
- Python의 GIL, 병렬 처리를 위한 C/C++