[DEVIEW 2023] SNOW AI Filter (SNOW) 정리
발표 자료 및 영상: https://deview.kr/2023/sessions/556
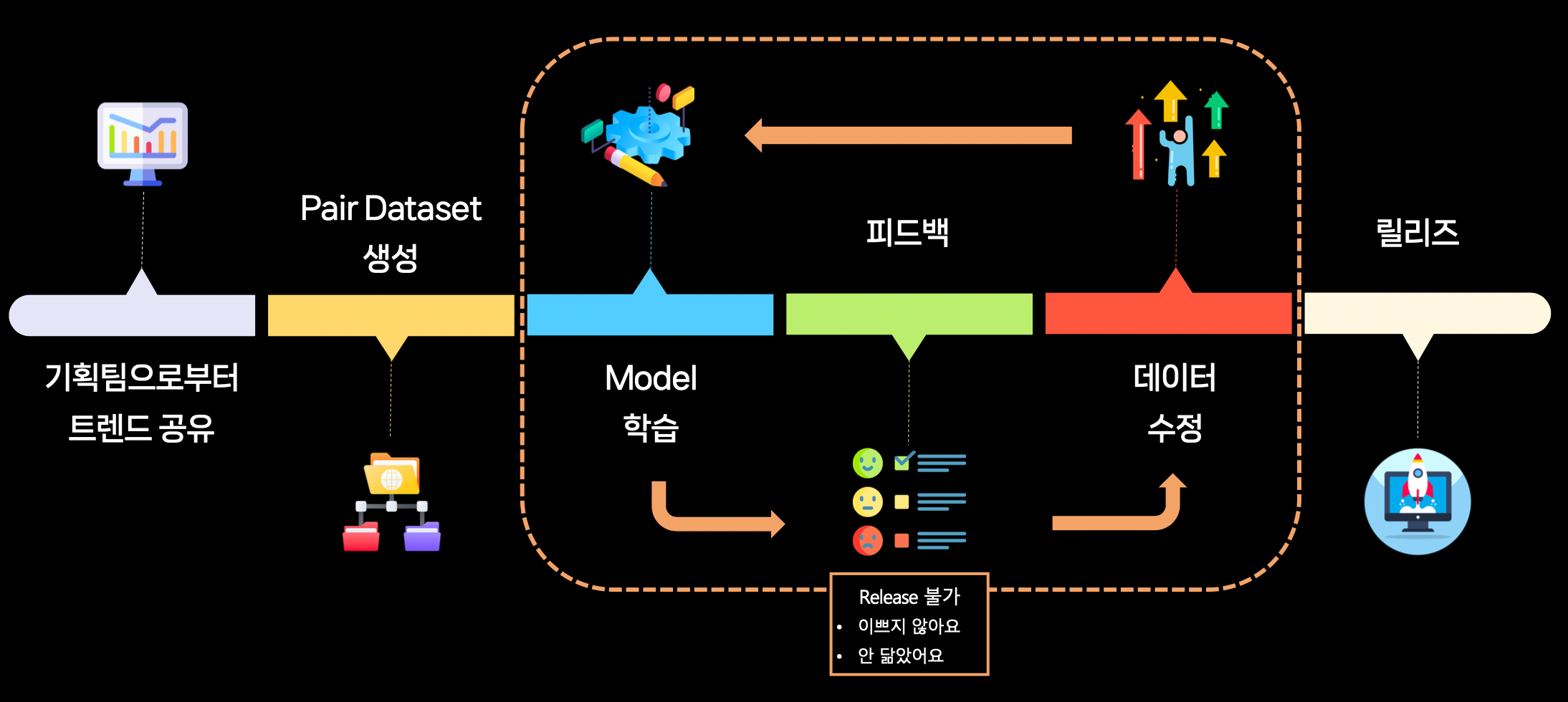 SNOW AI FILTER 개발 과정
SNOW AI FILTER 개발 과정
- 데이터를 어떻게 생성해서, 어떤 모델로, 어떻게 학습해서 AI FILTER를 개발하는지
- 반복되는 기획의 피드백을 어떻게 받아 어떻게 반영하여 서비스를 만드는지
1. Dataset
- unpair dataset: unsupervised 방법으로, 서비스 하기에는 너무 낮은 quality이다.
- pair dataset: quality는 높으나 img-label pair dataset을 필요로 한다.
Pair Dataset 생성 과정
모델 학습에 충분한 이미지는 약 5000여 장
수작업으로 dataset 생성 (3500장): 많은 인력과 시간적 비용이 소모된다.
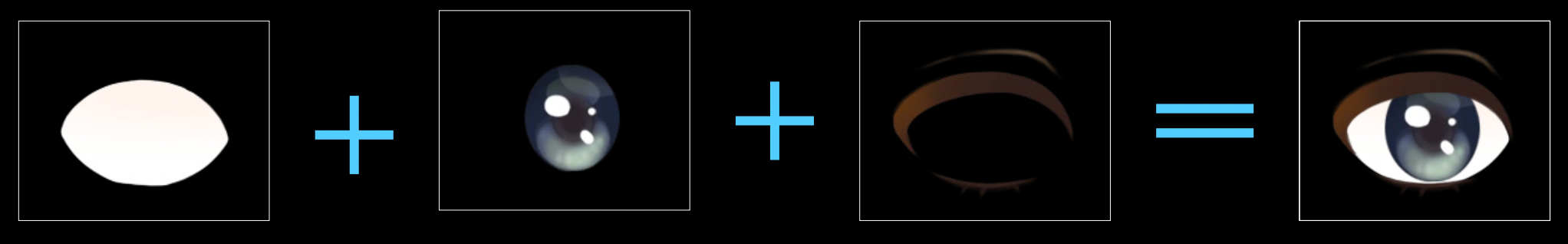
- StyleGAN2를 이용한 layer swapping 방식
수백 장의 target style 이미지 만으로 pair dataset을 생성할 수 있다.
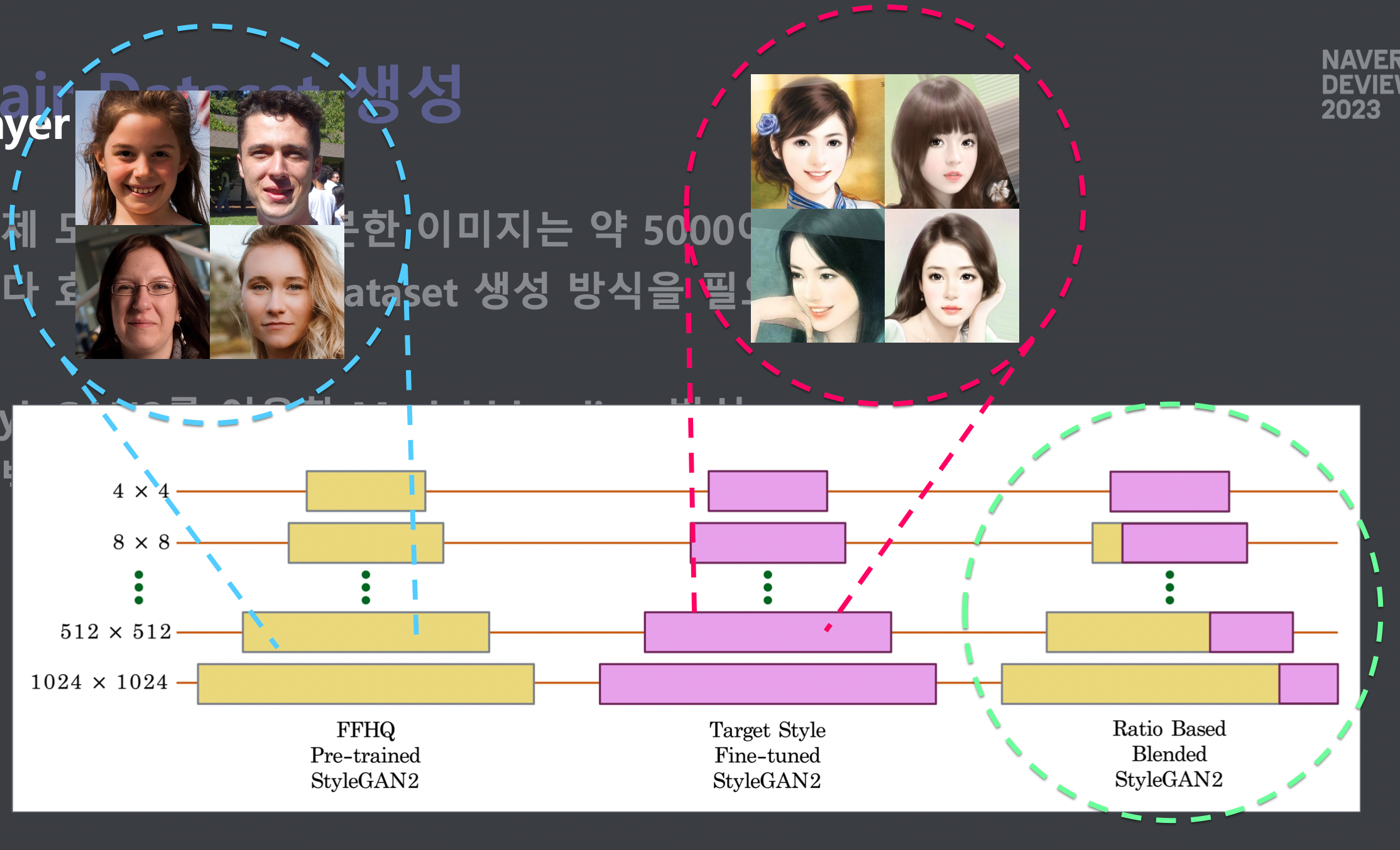
학습 결과

- 최근에는 다양한 방식의 pair dataset 생성 방식 시도 중
- target style image 수를 획기적으로 줄일 수 있는 방식
- 더 좋은 quality의 pair dataset 생성
Data Engineering
image processing, graphics 등의 다양한 기술을 종합적으로 활용하여 quality를 증대시킨다. (ex. 홍채 빛 반사 추가)

딥러닝 기반 방법만 사용하지는 않는다. (ex. selective search)

다양성(ex. 눈을 감고 있는 사람, 웃는 사람에 대한 변환) 관련 이슈를 해결하였다.
- 초기 - landmark 기반으로 눈을 감거나 웃는 데이터를 생성하였다.
- 최근 - GAN inversion 기법을 활용하여 데이터를 보강하였다.
- seed data로 몇 장만 넣어주어도 다양성이 증대된다.

2. Model
실시간 Model
- 얼굴만 변환하는 것을 목표로 한다. (for mobile 실시간 preview)
- SE-Block을 통해 개량한 U-Net 형태의 generator를 이용한다.
- activation function으로 hard swish를 이용하였고, mobile 최적화와 성능 개선을 위해 여러 변경 요소를 적용하였다.
후편집 Model
배경 및 전경을 포함하는 전체 이미지 영역에 대해 변환하는 것을 목표로 한다.

- 시간이 오래 걸리더라도 좋은 quality를 보장해야 한다.
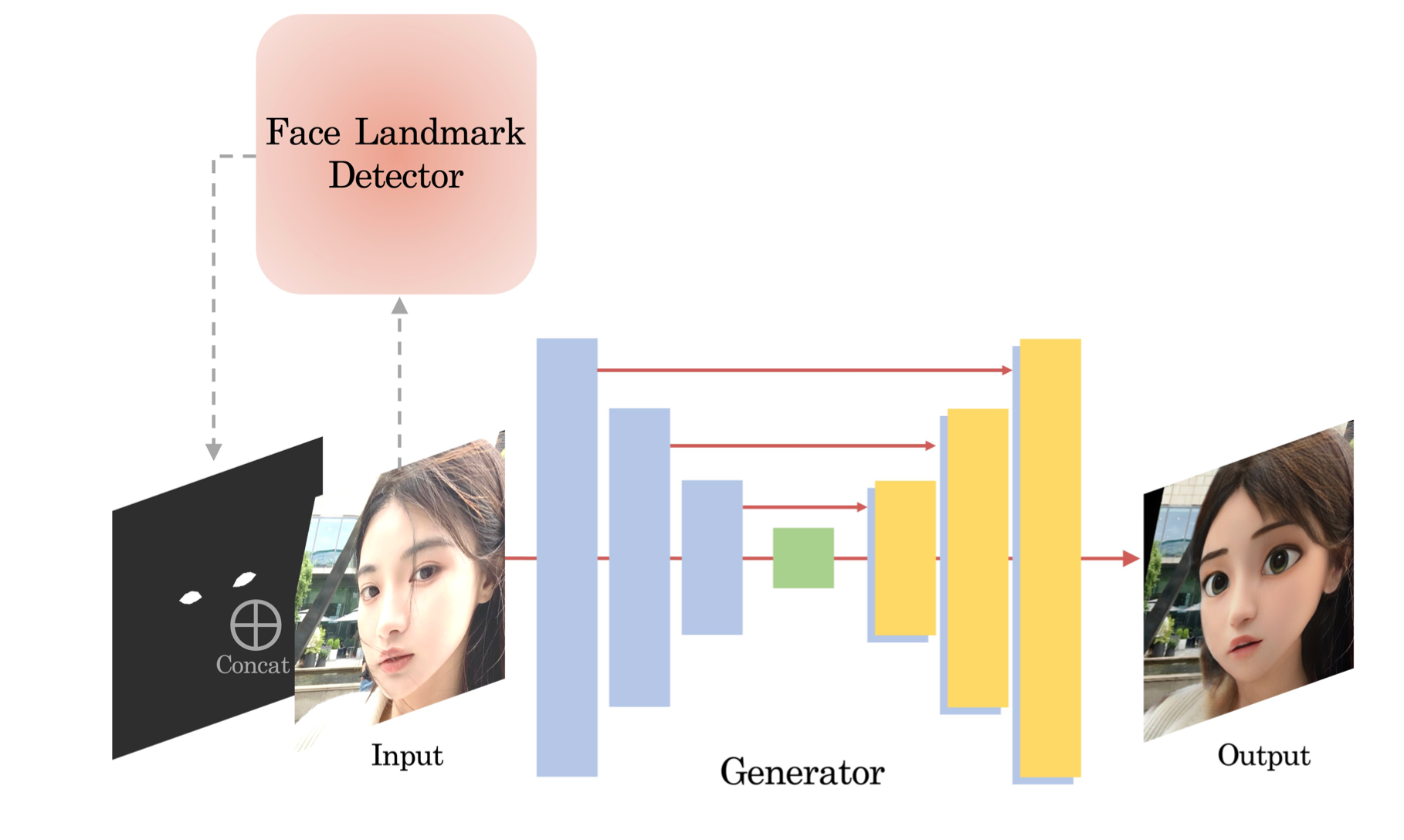
모델 구조
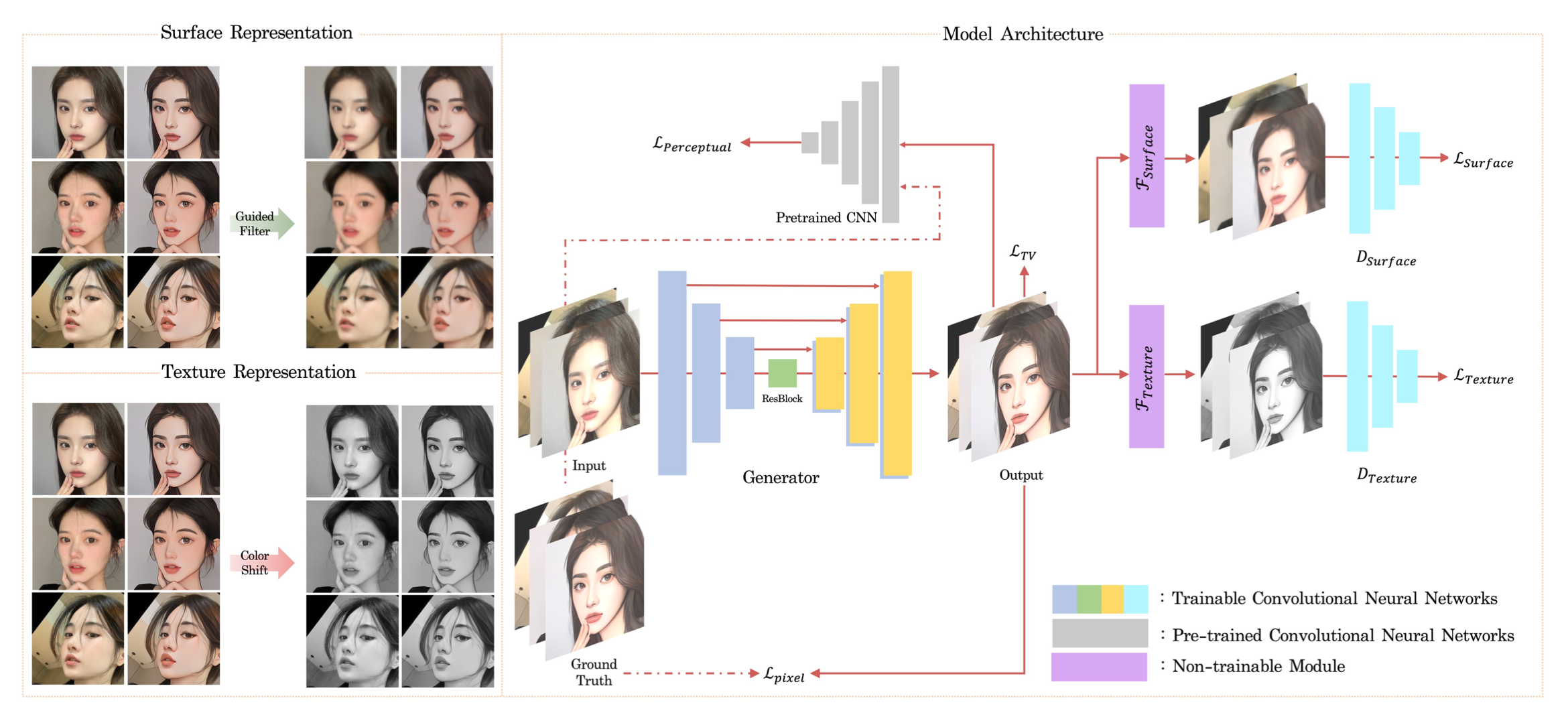
Issue
적합하지 않은 위치에 눈을 생성하는 이슈를 해결하기 위해 face landmark 기준으로 생성한 eye mask를 입력 이미지의 추가 채널(alpha 채널에)로 제공하여, 얼굴 내에서 눈 위치에 대한 geometry 정보를 모델이 알 수 있도록 하였다.
Analysis
더 나은 결과가 있다면 더 나은 결과가 나오는 이유에 대해 분석했다.
perceptual loss로 학습한 pretrained CNN features와 discriminator features를 GradCAM 등을 활용하여 비교했다.
distance(pixel, feature), FID, IS, …
사용자 만족도를 얻어야 하는 서비스에서는 정성적인 평가가 더 좋은 것이 중요하다.

3. AI Service
모델 수정 과정에서의 커뮤니케이션 비용 줄이기

- Needs
- 누구나, 언제나 볼 수 있는 시스템
- 관리/공유되는 샘플 사진
- 모델 버전 관리
- 쉽고 빠르고 편리한 버전별 결과 비교 페이지
GAN STUDIO - Flask로 직접 만든 웹 페이지 (요즘은 FastAPI가 더 좋음)
AI 개발자가 web을 해야 하는 이유
- 필요한 업무이지만 해 줄 수 있는 사람도, 해주는 사람도 없다.
- 결과를 wiki에 정리할 필요도, 매번 샘플 코드를 고칠 필요도 없어진다.
- 모델의 버전 관리를 할 수 있게 된다.

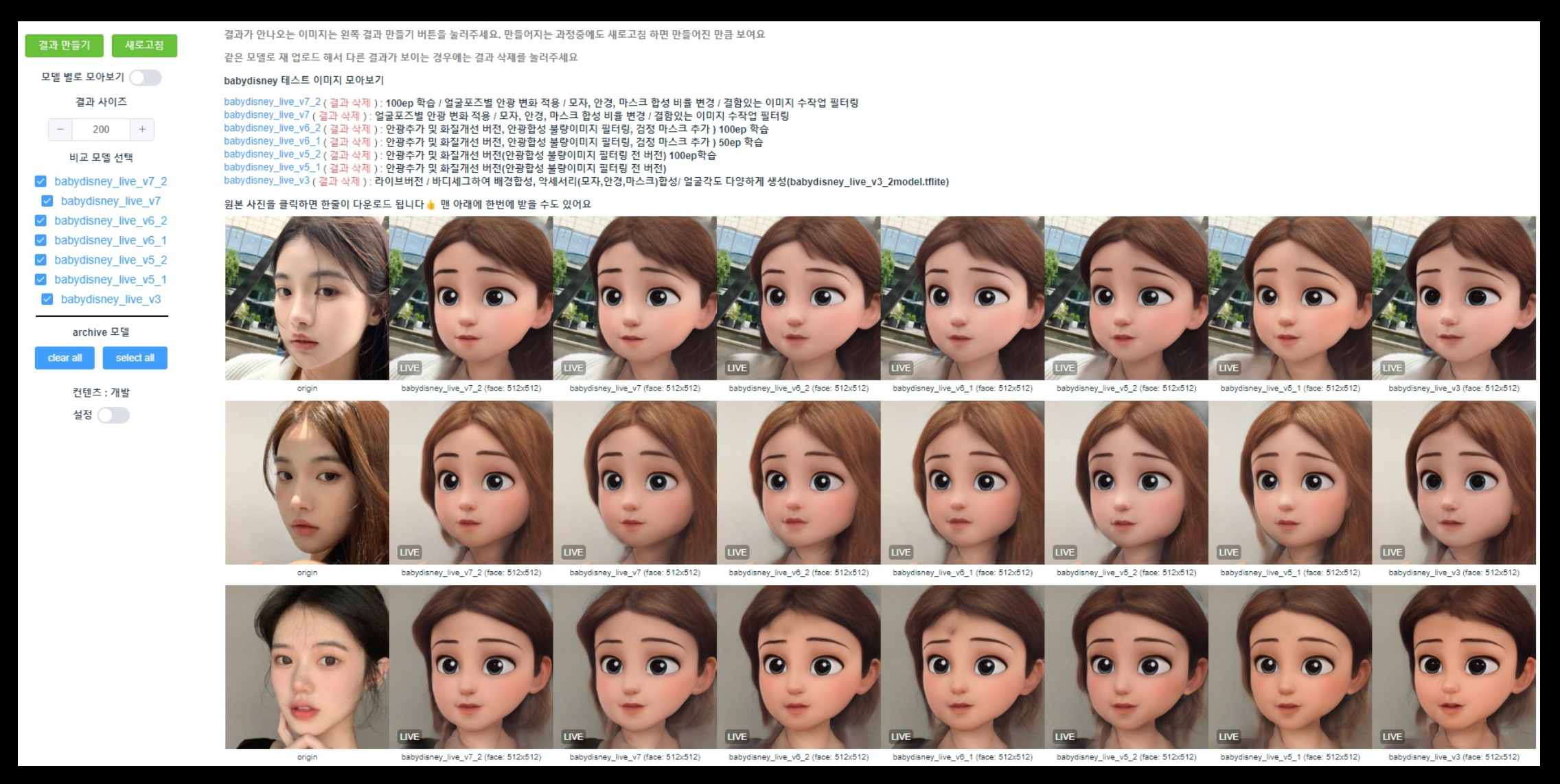
GAN STUDIO
테스트 이미지 샘플 관리
컨텐츠 모델 관리 (모델 group, 버전 분기)
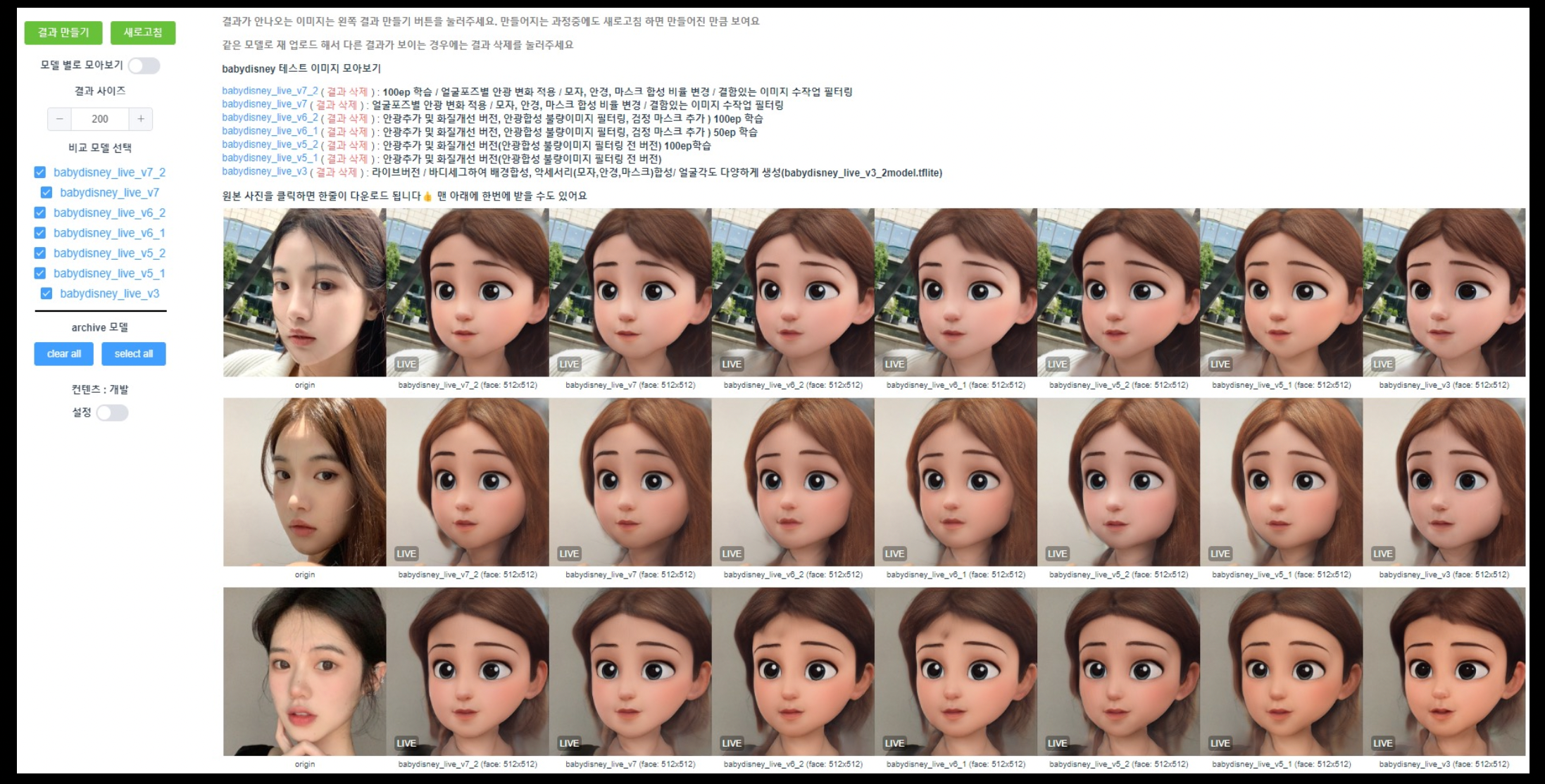
웹 테스트
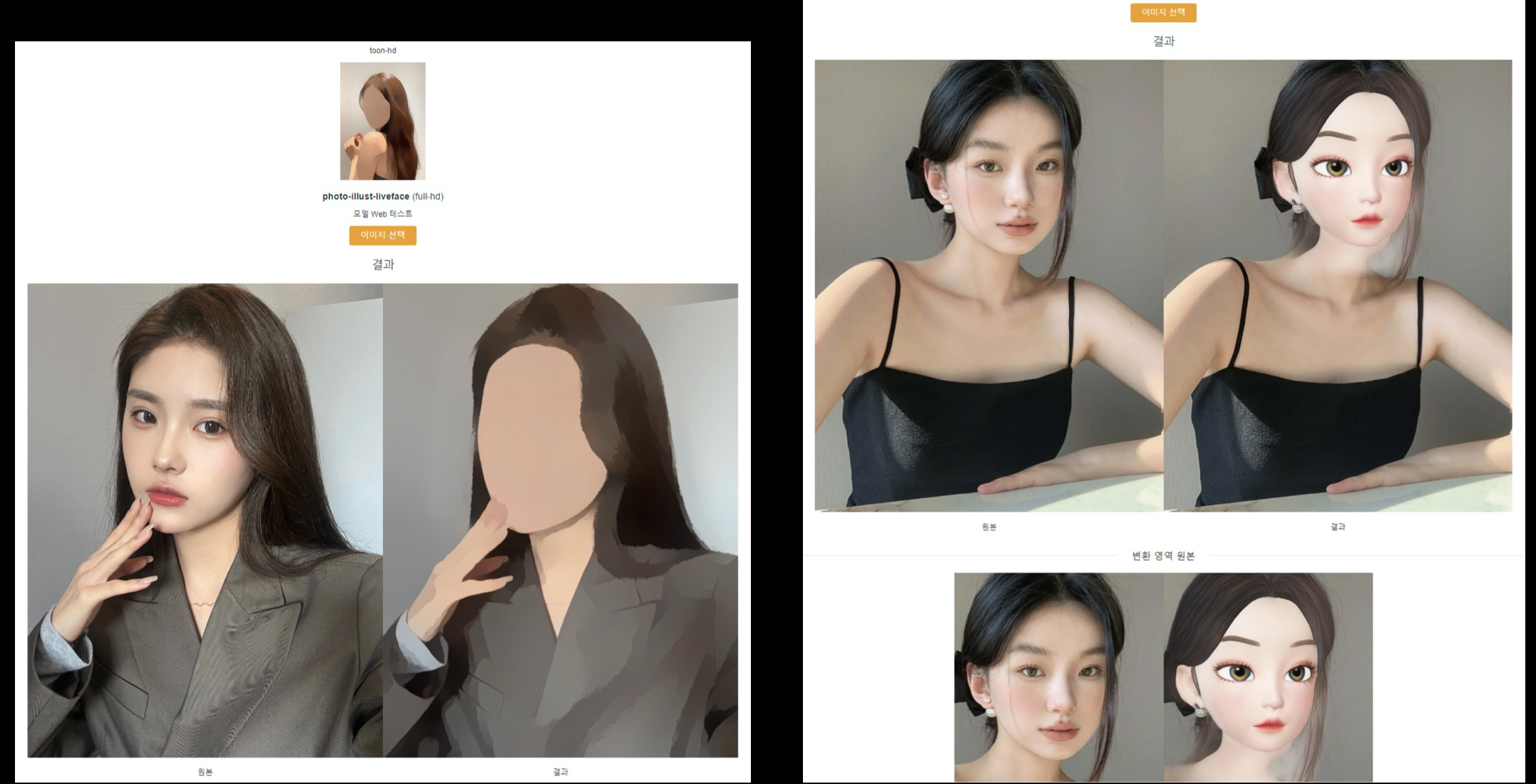
AI + Web + Service의 효과
- 반복 작업 자동화
- 기획 팀이 AI 작동 방식을 학습
- 모아서 볼 수 있음
- 모델 버전 관리
- 데이터 가시화
- human error 감소
4. Q&A
- 아쉬운 점
- 전체 영역에 대한 변환 모델은 아직 실시간 실행이 어렵다.
- 없는 데이터를 만드는 것이 어렵다. (→ SD)
- 모델 분석
- 중간 feature map을 뽑아 Grad CAM을 찍어본다.
- ex) 눈 변환이 어려운 경우, Grad CAM을 통해 눈 쪽을 잘 보는 모델을 알아본다.
- 2가지 layer을 사용한 부분
- StyleGAN model blending → block 일부를 교체하는 방식이다.
- 실시간 model과 후편집 model의 차이
- discriminator가 가장 큰 차이이다. (SE-block 유무 차이)
- fine-tuning 여부
- pair dataset 만들어서 scratch 부터 학습했다. (fine-tuning X)
- 모바일
- 서버에서 API 형식으로 serving 하였다. (torch로 가능)
메모
- AI 서비스 개발 과정에 있어서 조직 내 / 조직 간 커뮤니케이션을 위한 사내 서비스의 필요성
- 공유된 데이터셋 → 모델 버전 관리 용이
- 실시간 / 후편집 모델
- 우리도 사내에서 쓸 웹 서비스 하나 만들면 좋겠다…