[DEVIEW 2023] 값비싼 Diffusion Model을 받드는 저비용 MLOps (Symbiote AI) 정리
발표 자료 및 영상: https://deview.kr/2023/sessions/533
1. Diffusion Model
Multimodal image generation model with diffusion process
- image generation - BigGAN → StyleGAN2 → DALL-E 2
- multimodal - pair data가 필요하다.
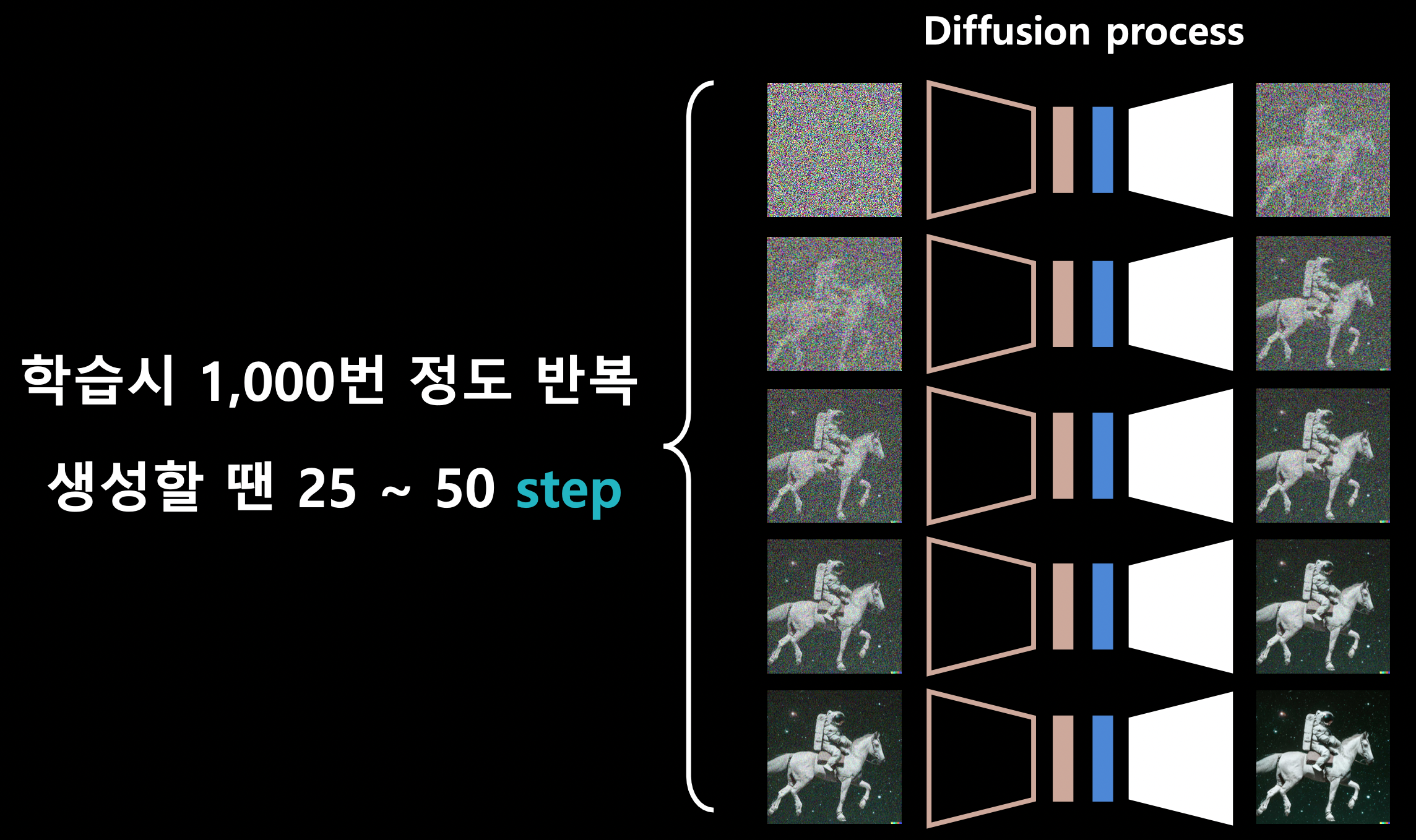
diffusion process = denoising (clearer image 만드는 과정)
단점
생성이 느리다. (= GPU 비용이 많이 든다.)
생성 시 50회 정도 반복하므로 GAN보다 느리다.
학습이 느리고 리소스가 많이 든다. (= GPU 비용이 많이 든다.)
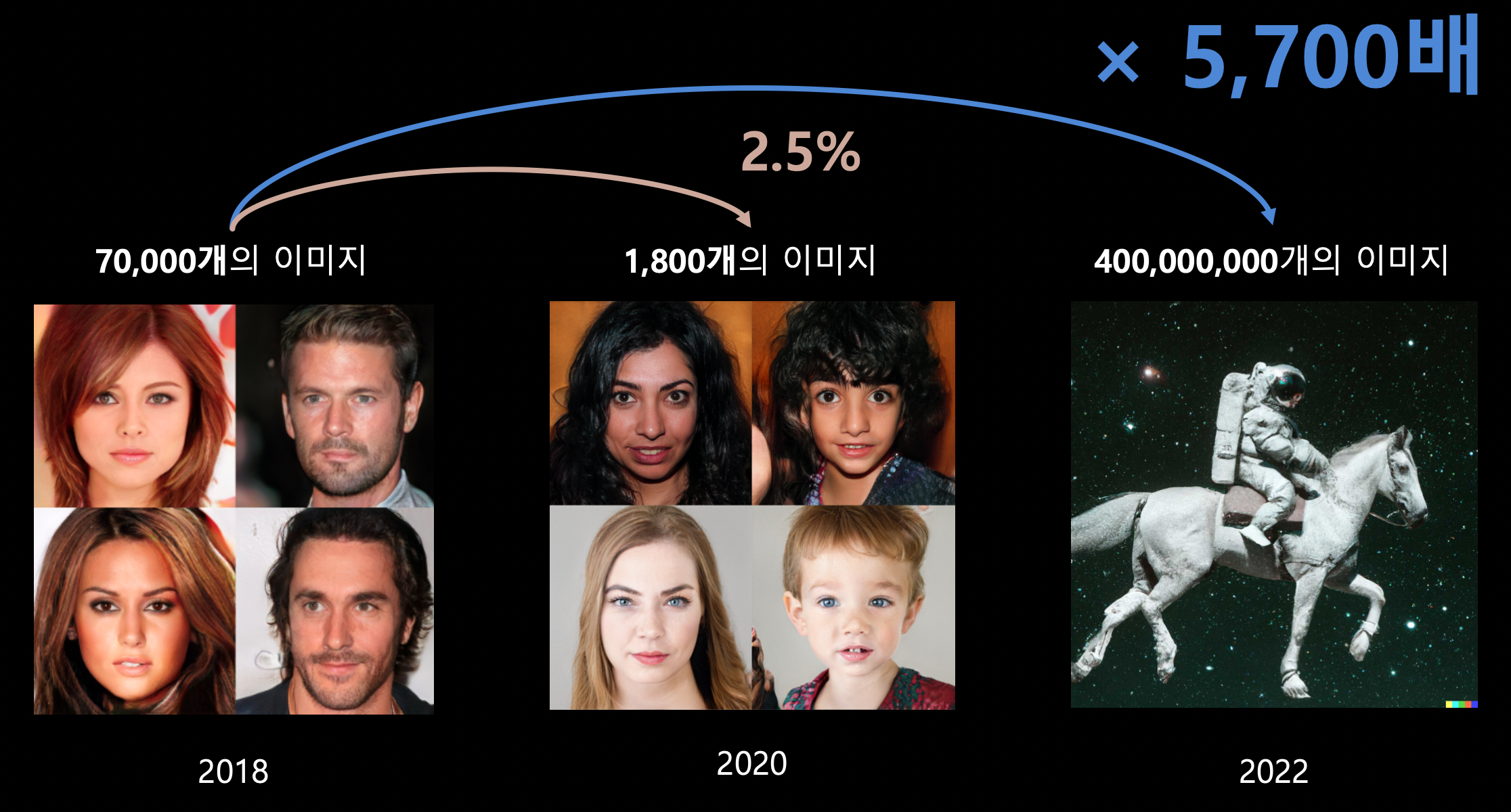
최근 6개월 간 Diffusion Model의 발전 과정

- Stable Diffusion
- 150,000 A100 GPU Hours = $600,000
- 생성 시 50 step = V100 기준 10초
- DreamBooth & LoRA
- 4억 개의 이미지 없이도 새로운 모델을 학습할 수 있을까?
- LENSA
- xformers
FlashAttention - GPU 계산에 사용되는 메모리(SRAM) ↔ 크지만 I/O가 느린 메모리(HBM) 간의 다수의 I/O 과정을 없애는 방법이다.
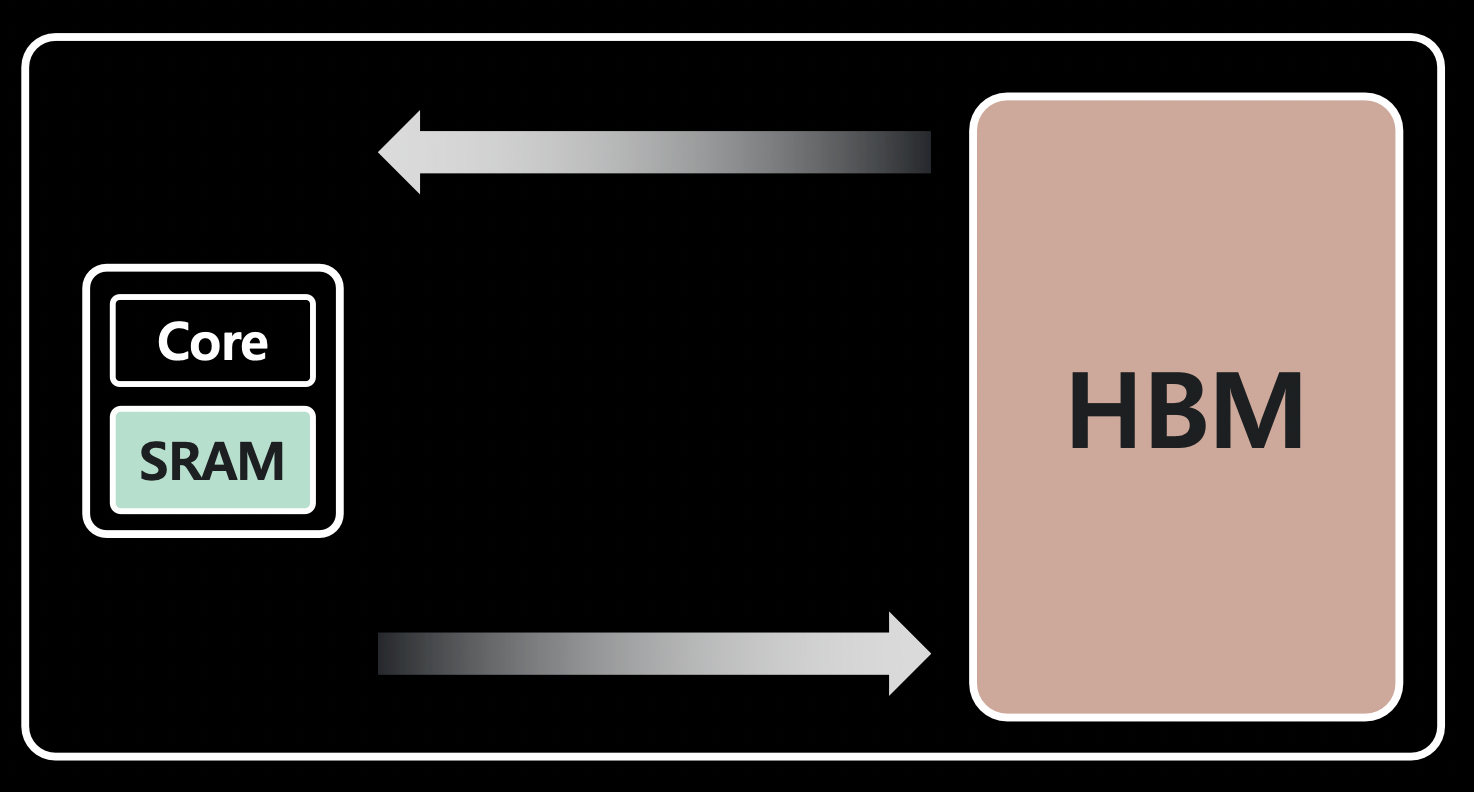 GPU 구조
GPU 구조
- Prompt-to-Prompt
slight한 수정 사항을 적용할 수 있다.
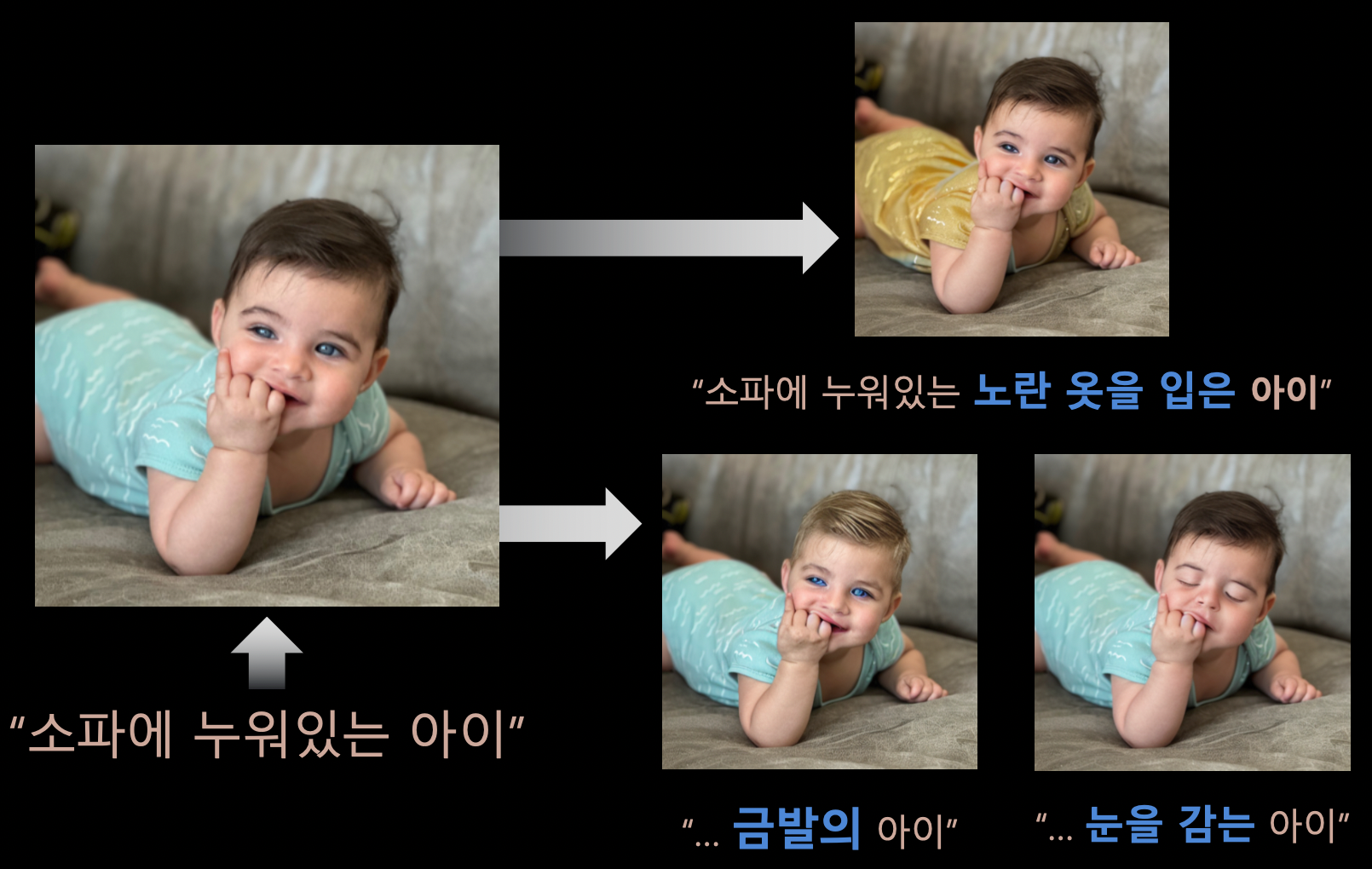
기존의 diffusion model로 학습 데이터를 만들어서 새로운 모델을 학습하는 데에 사용할 수 있다.
- InstructPix2Pix
- Prompt-to-Prompt로 만든 데이터와 GPT-3로 만든 데이터를 통해 기존의 diffusion model을 재학습한다.
다음과 같은 대화형 수정 AI를 만들 수 있다.

- ControlNet
- 기존의 방식과는 다르게 텍스트가 아닌 이미지로 생성과 수정을 할 수 있는 방식이다.
reference image를 입력으로 넣는다.

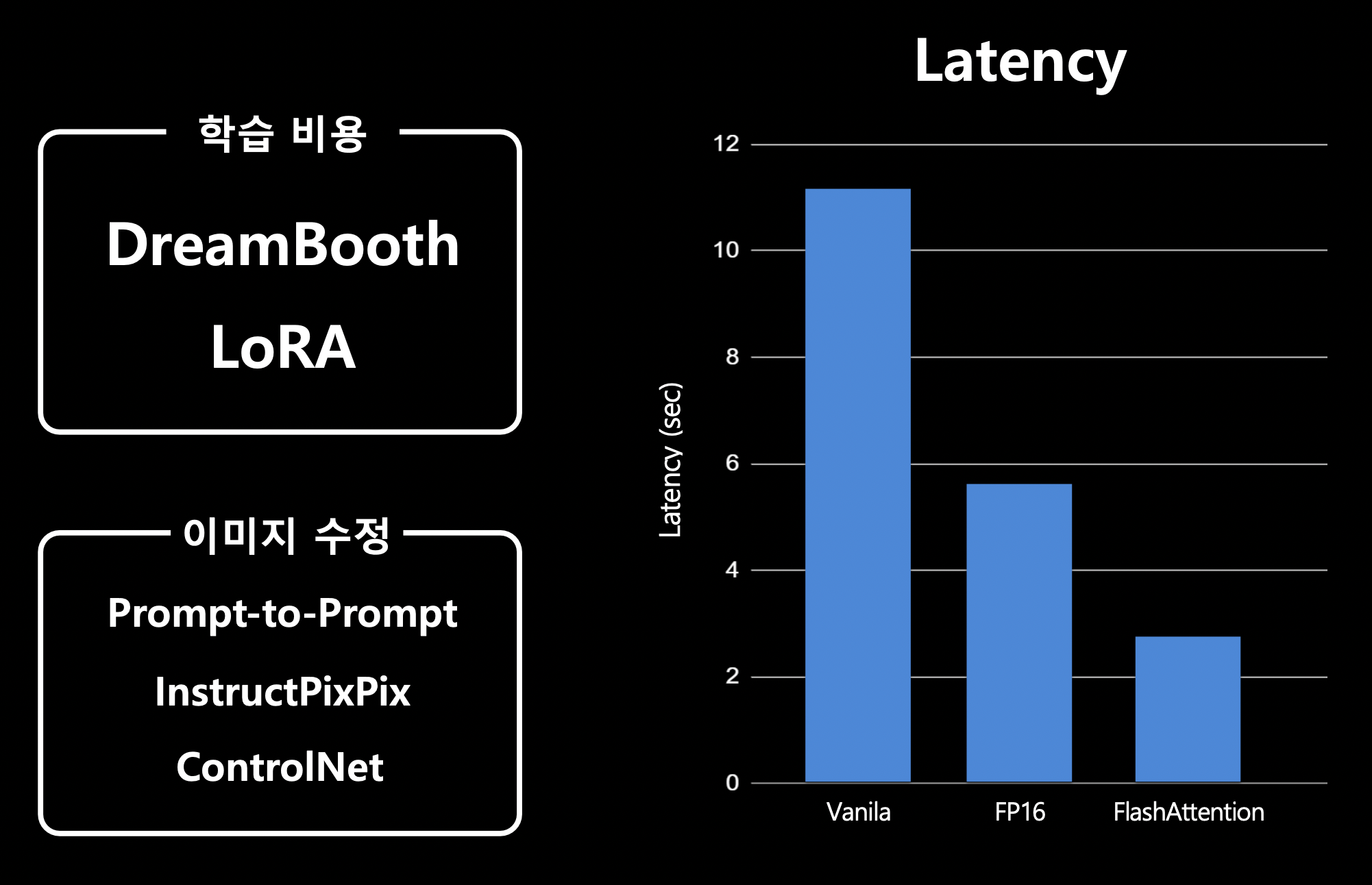 전체 정리
전체 정리
2. 저비용: 어떻게 최적화 했는지
generation이 메인인 서비스 ⇒ latency와 scalability가 중요하다.
Distillation
생성 시, 50 step에 V100 기준으로 10초가 걸린다. 추론 횟수를 줄이려면?
knowledge distillation
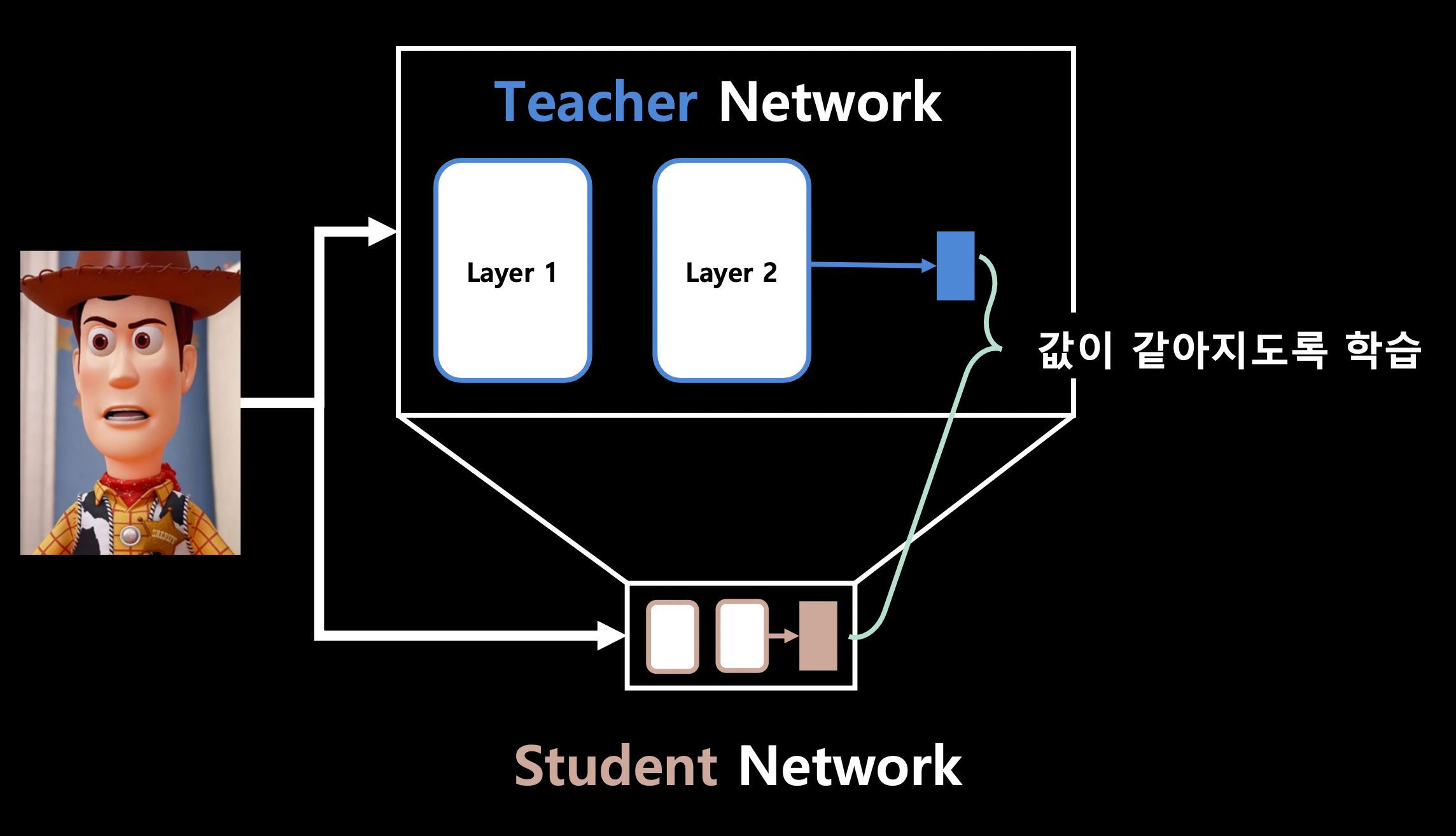
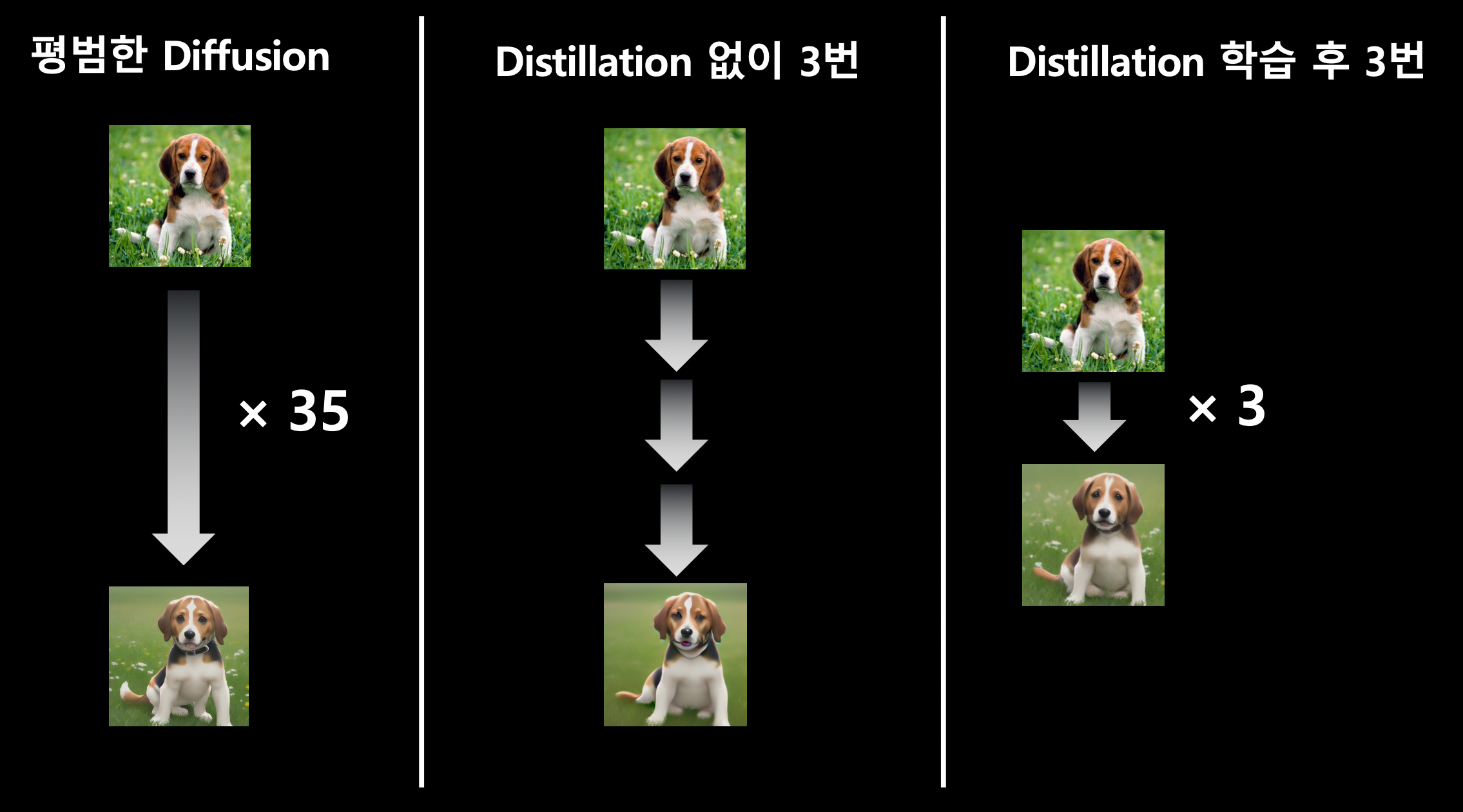
distillation으로 모델 크기도 줄일 수 있으나, 추론 step 수를 절반씩 줄일 수 있다. (\(2^n\)씩)


Image2Image 모델로 기존 모델이 학습한 데이터셋에서 학습한 결과, 1번의 distillation은 평균 1.5일 정도 소요되었으며 전체 학습 기간은 6일이었다.
Free 버전에서는 distillation 모델을 사용하여 latency를 크게 줄여 사용자 경험을 향상시킬 수 있고, Pro 버전에서는 기존의 diffusion 모델을 사용하여 완성도를 향상시킬 수 있다.

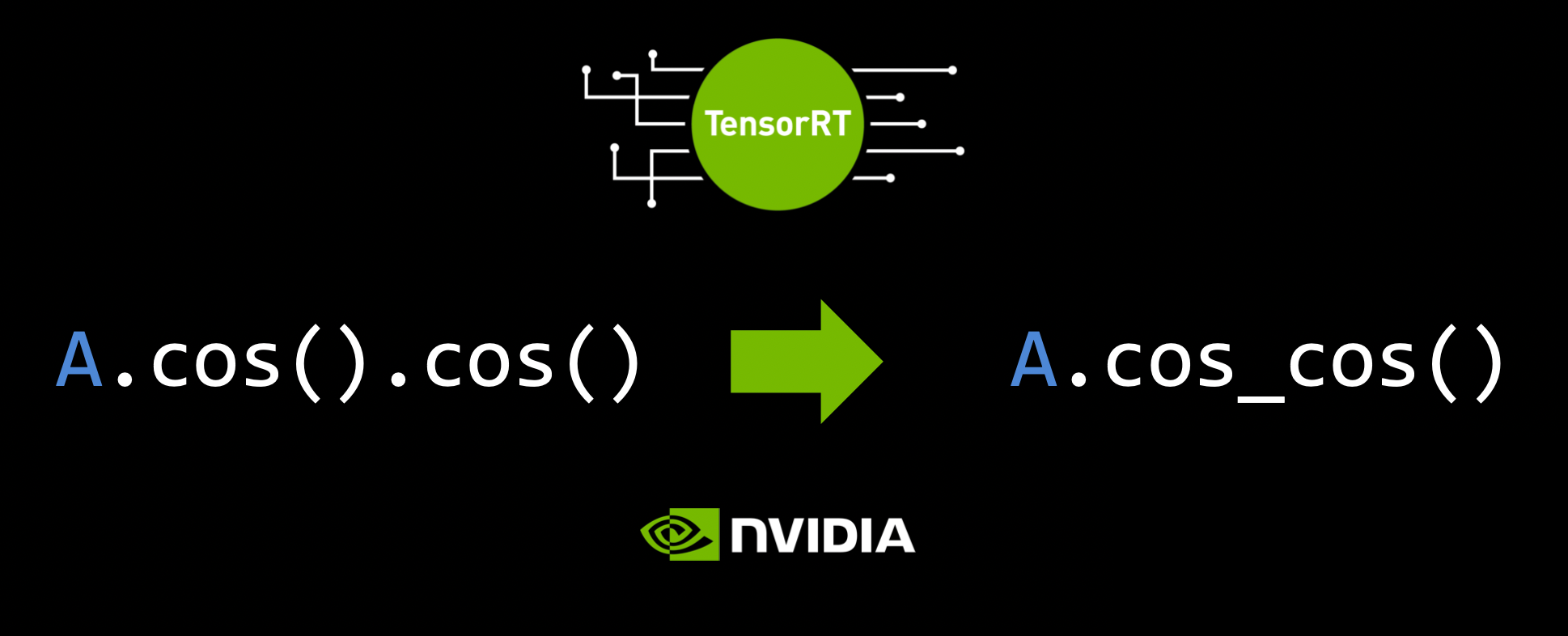
TensorRT
- GPU 하드웨어 구조
- SRAM과 HBM 간 I/O는 느리다.
GPU가 더 빠른 연산: ex)
torch.matmul(A, B)(병렬 처리 가능)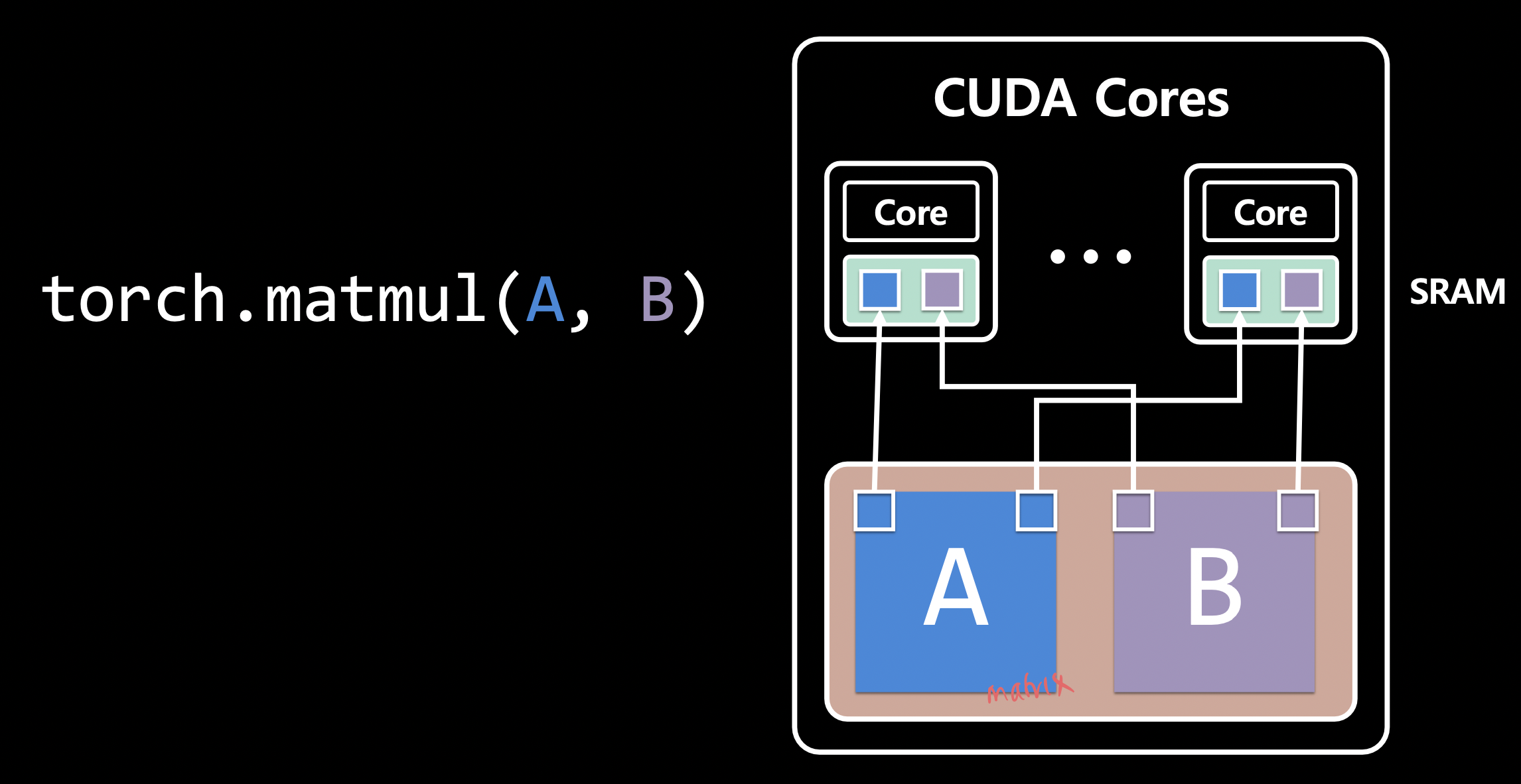
CPU가 더 빠른 연산: ex)
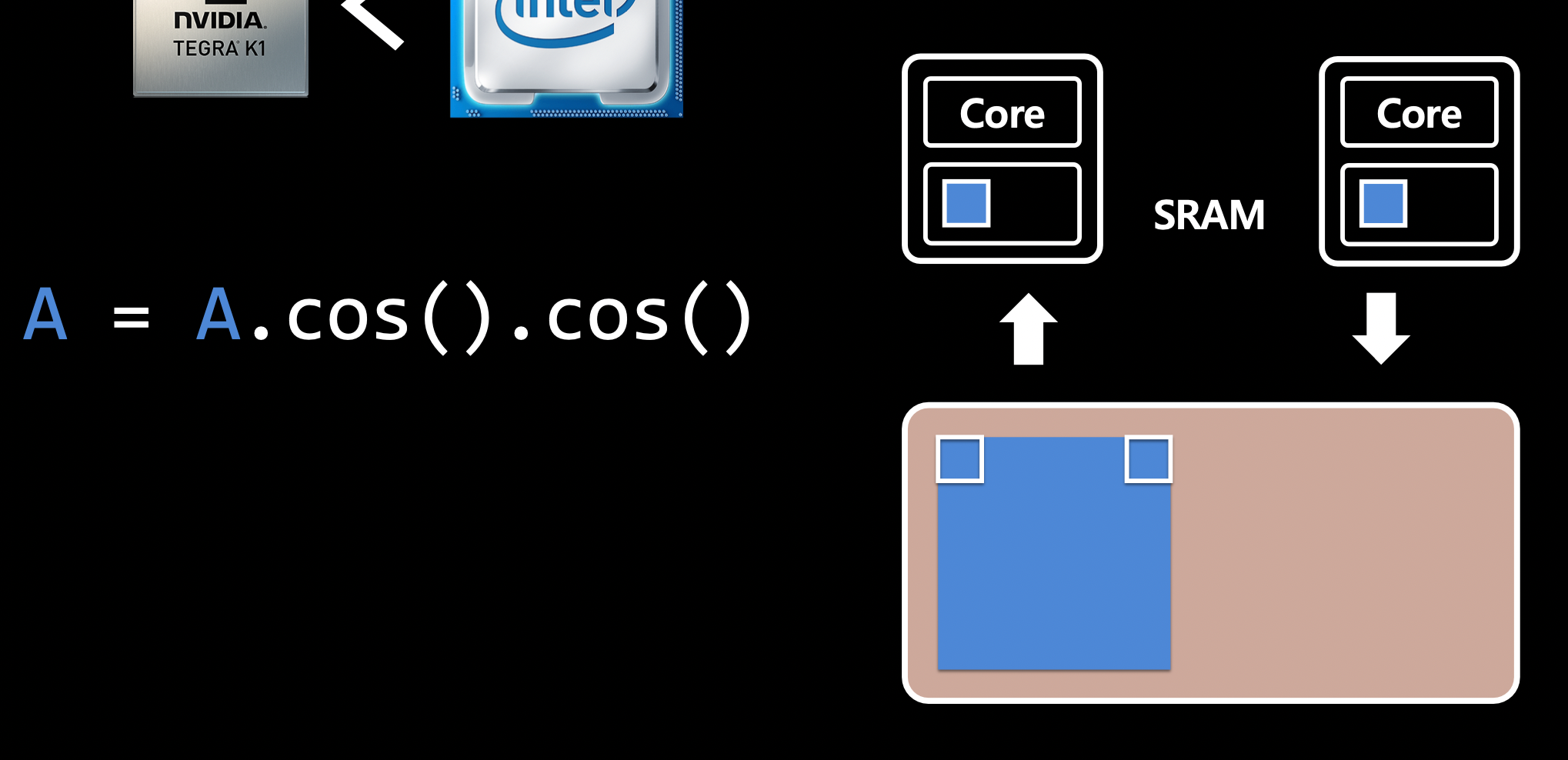
A.cos()→A.cos()(두 번의 연산을 한 번에 처리하면 I/O가 줄어듦)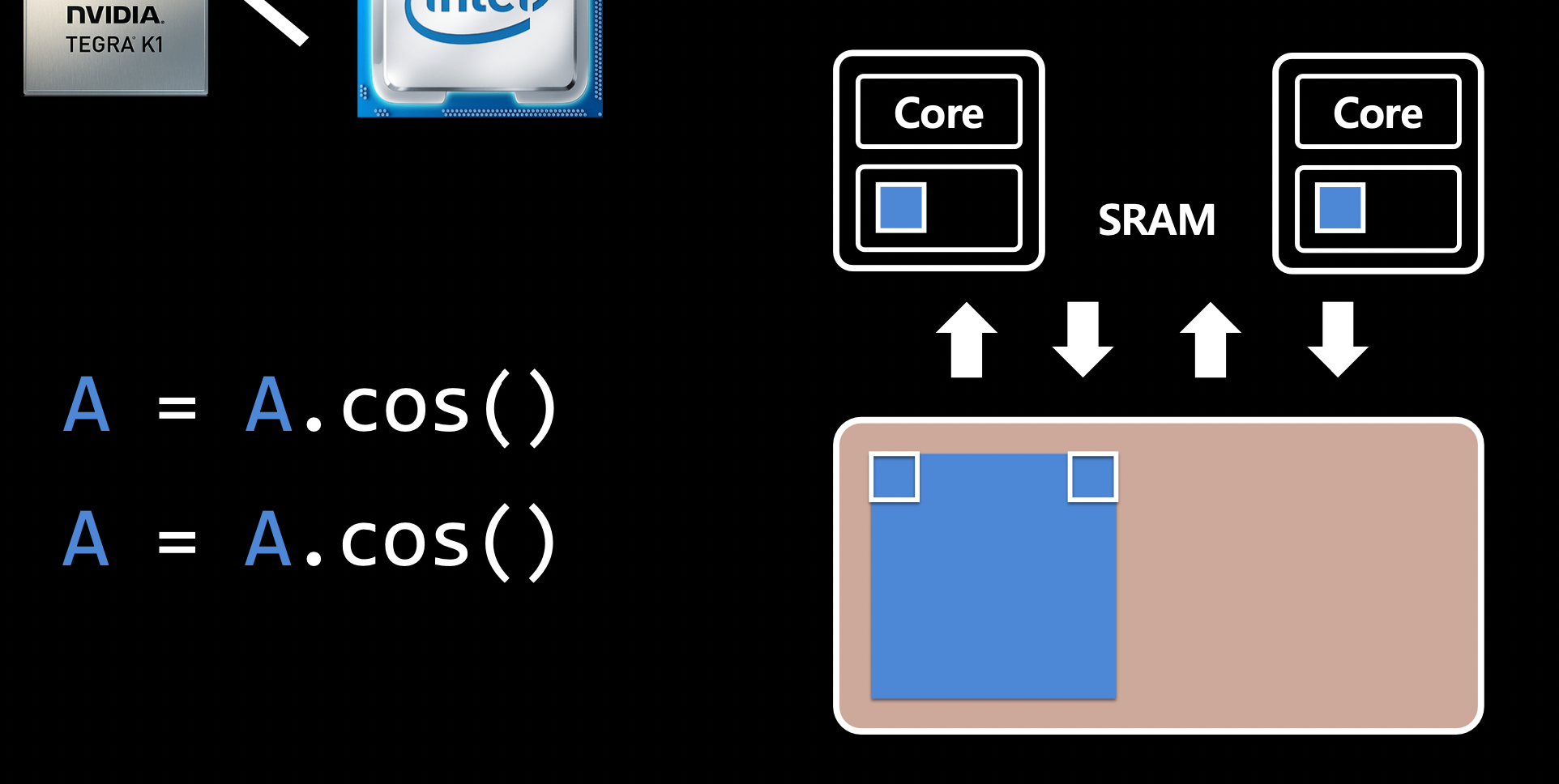
TensorRT의 역할은 다음과 같다.
사용 방법

Triton (OpenAI)
Triton이란 OpenAI가 만든 언어/컴파일러로, I/O 최적화된 CUDA 코드를 최적화한다. (ex. swish, gelu, groupnorm, layernorm, cast 등)
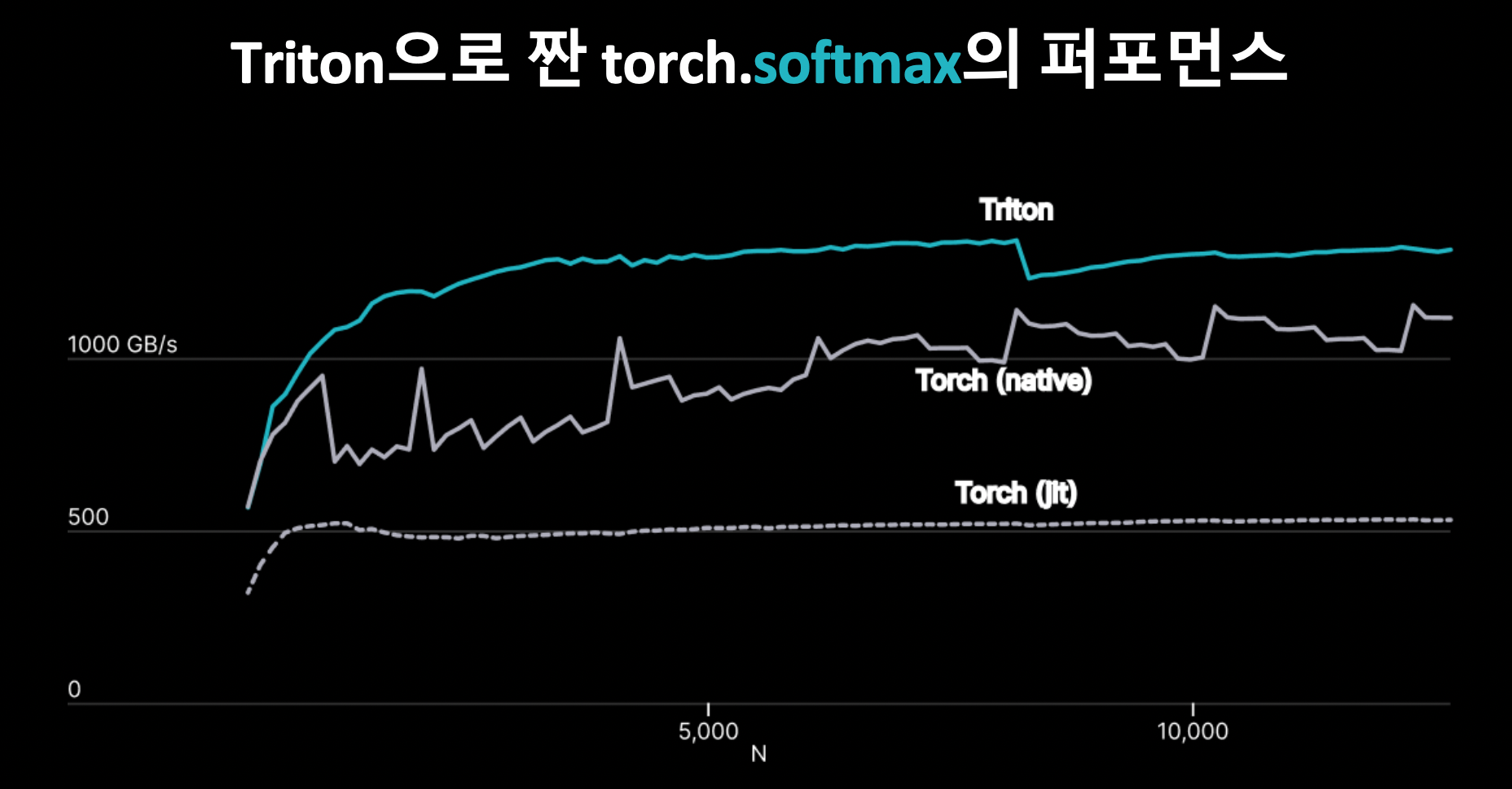
TensorRT를 통해 static graph를 최적화할 수는 있으나, static graph만으로는 모든 것을 알 수 없다.
- TensorRT가 최적화 하지 못하는 코드를 Triton으로 최적화 할 수 있다.
ex)
gelu- 7번의 I/O를 1번으로 줄일 수 있다.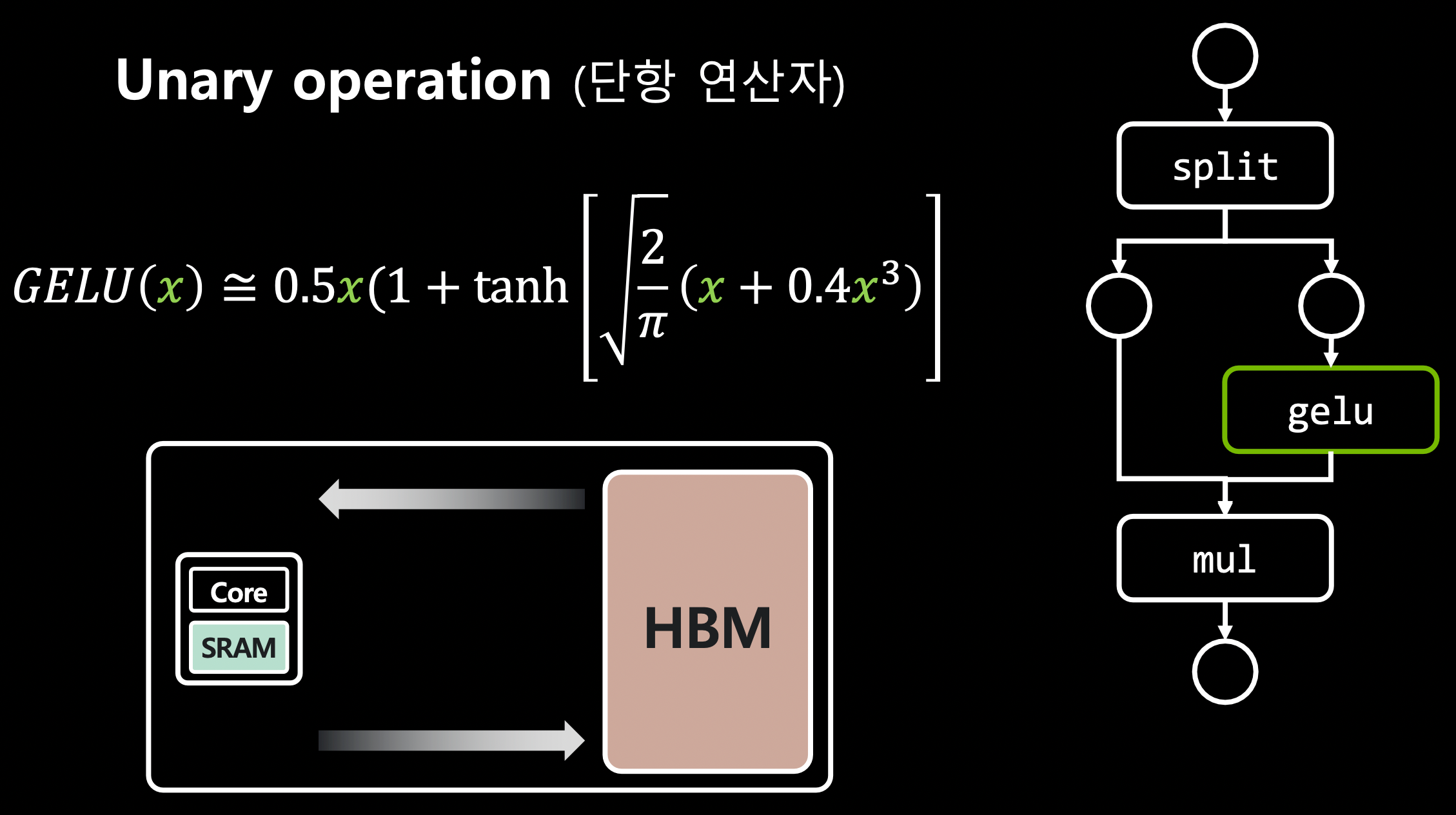
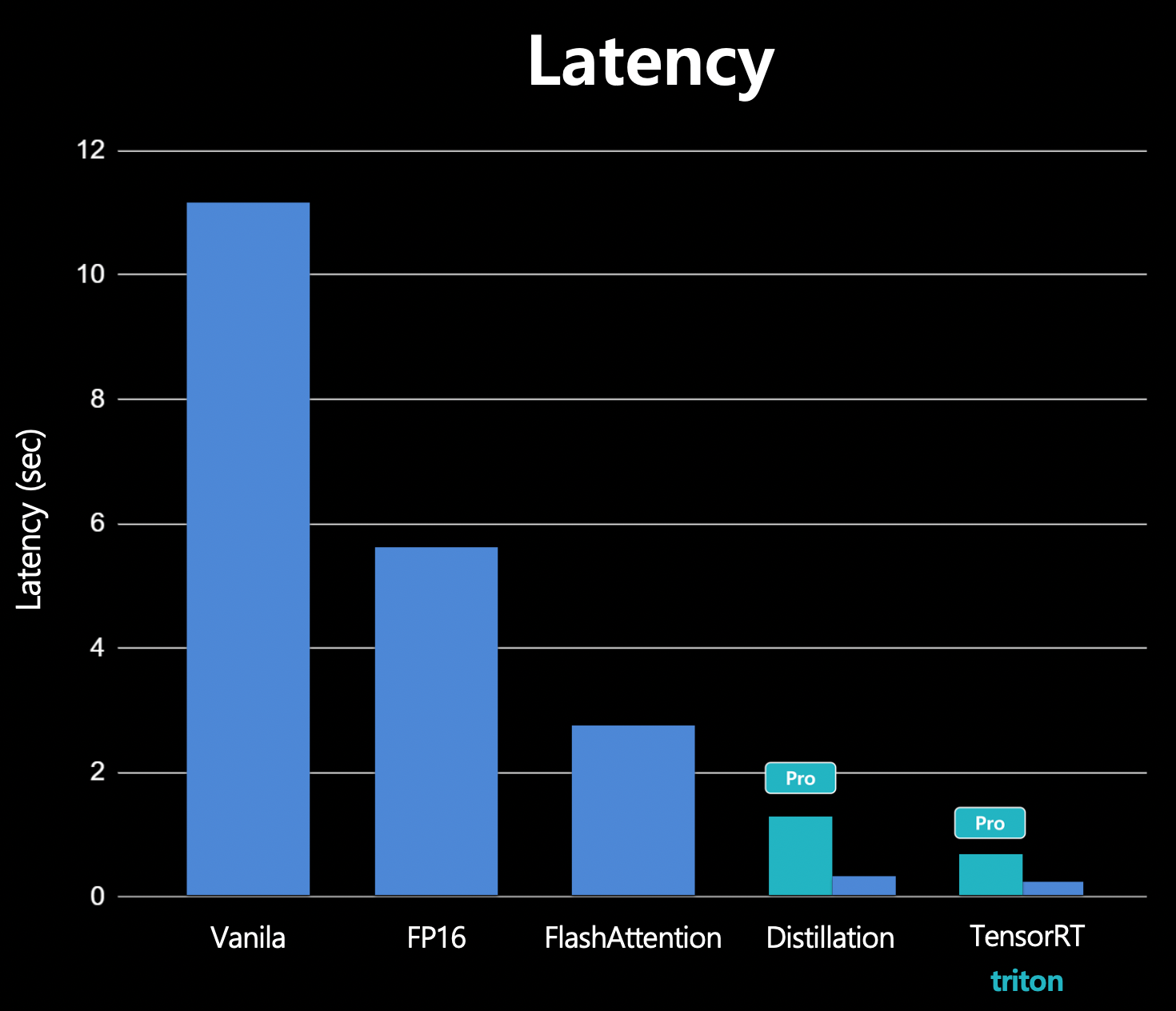
최종 Latency 개선 결과
3. MLOps: 어떻게 Serving 했는지
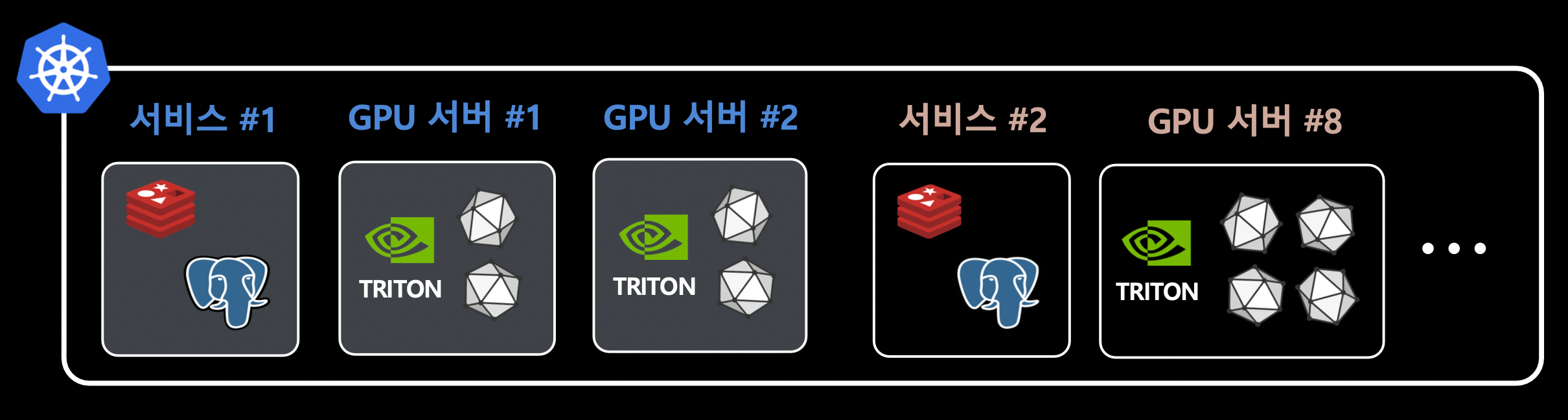
인프라 구조
- 클라우드가 아닌 bare metal 서버를 사용했다.
- kubespray로 self-hosted 클러스터를 운영했다.
- 2개의 서비스와 8개의 GPU 서버로 구성했다.
Triton Inference Server (NVIDIA)
OpenAI의 컴파일러인 Triton과는 다른 것이다.
- 장점
- ensemble model, scheduler, dlpack 지원
- TensorRT
- gRPC
- dynamic batching
전체 과정을 간단히 나타내면 다음과 같다.
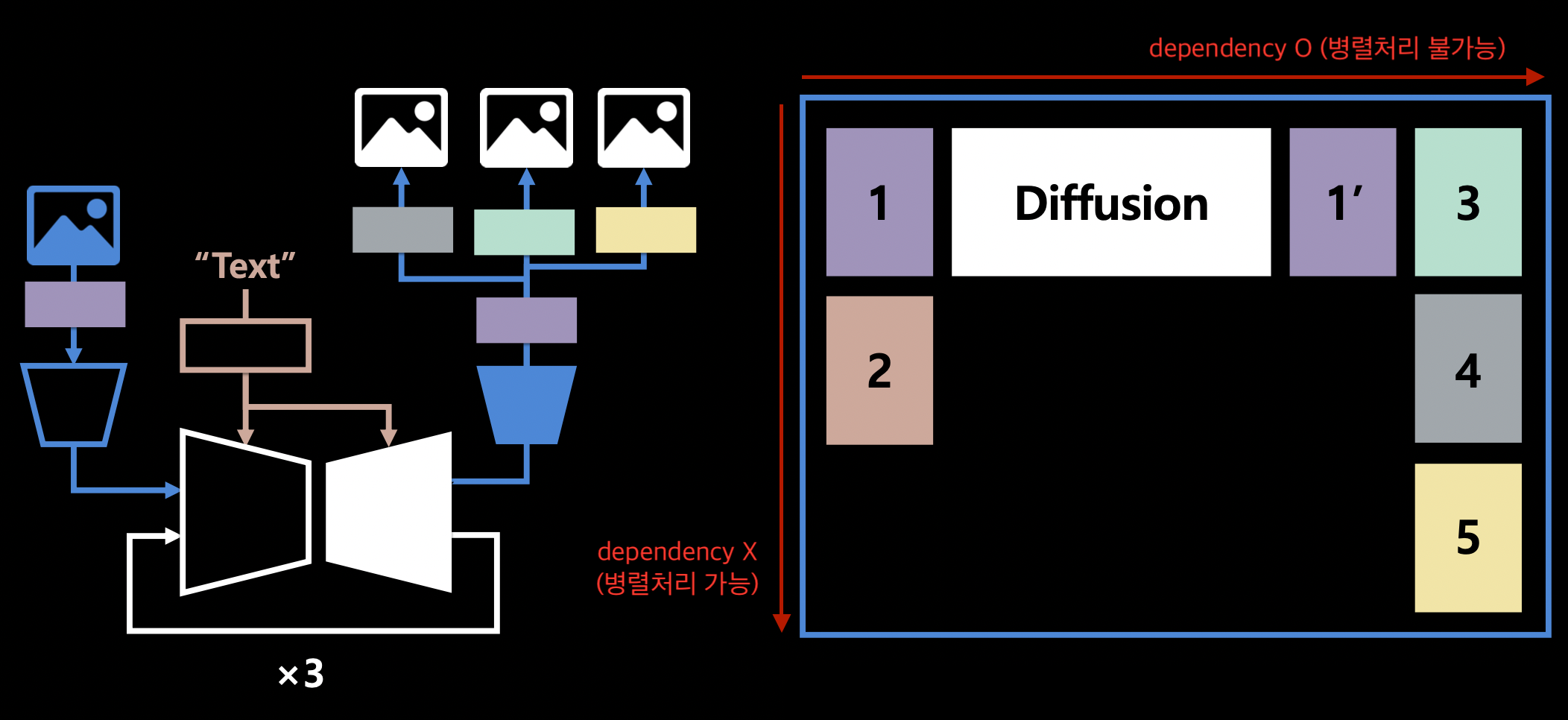
- Triton을 활용하면 inference time을 다음과 같이 최적화 할 수 있다.
- 하나의 request를 처리할 때에도 다른 request와 함께 동시에 처리할 수 있다.
- ensemble 시 유리하다.
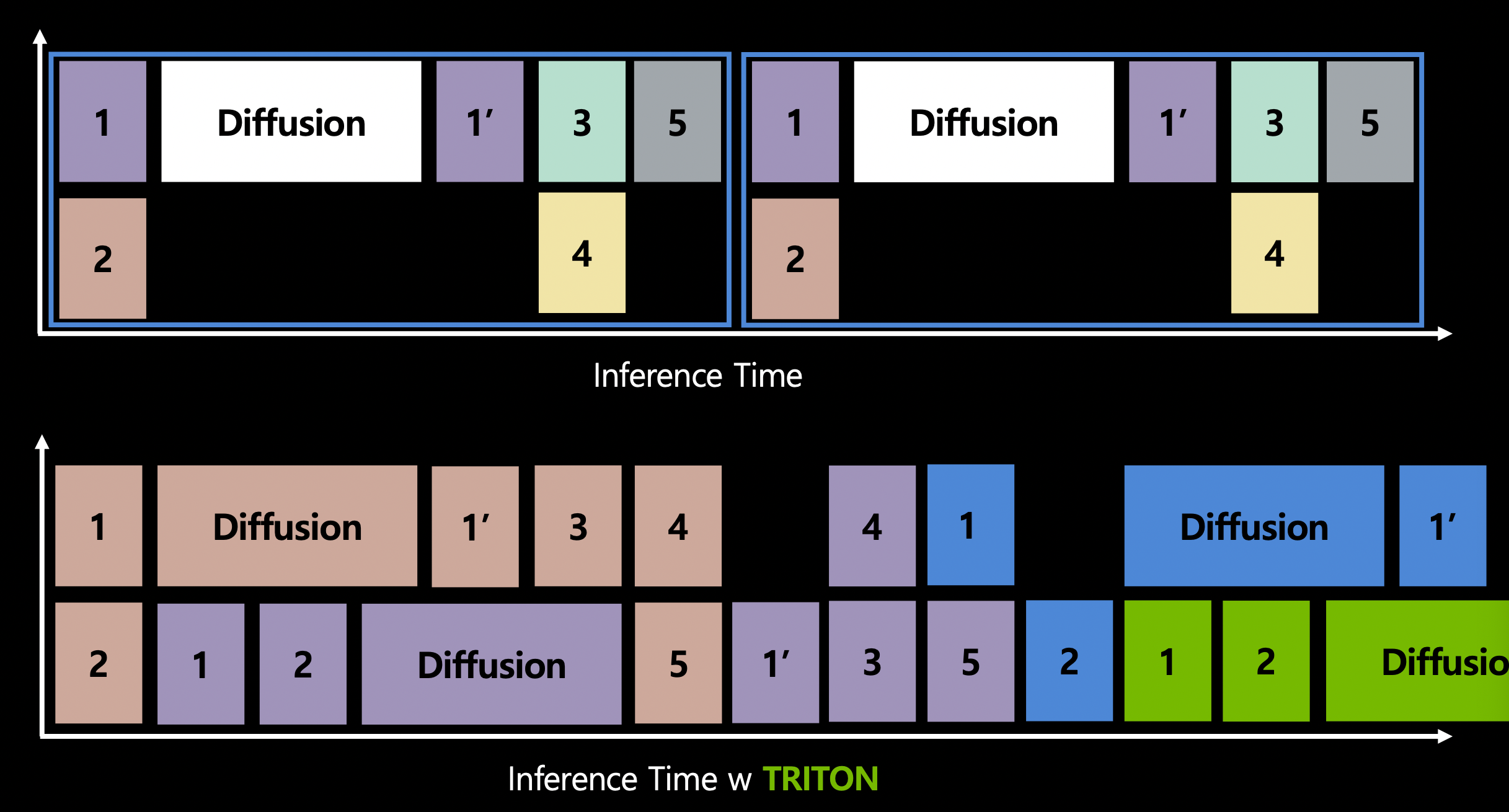
- diffusion model의 앞 뒤로 한 두 개의 pipeline만 있다면 필요하지는 않다.
- 참고: https://openai.com/research/techniques-for-training-large-neural-networks
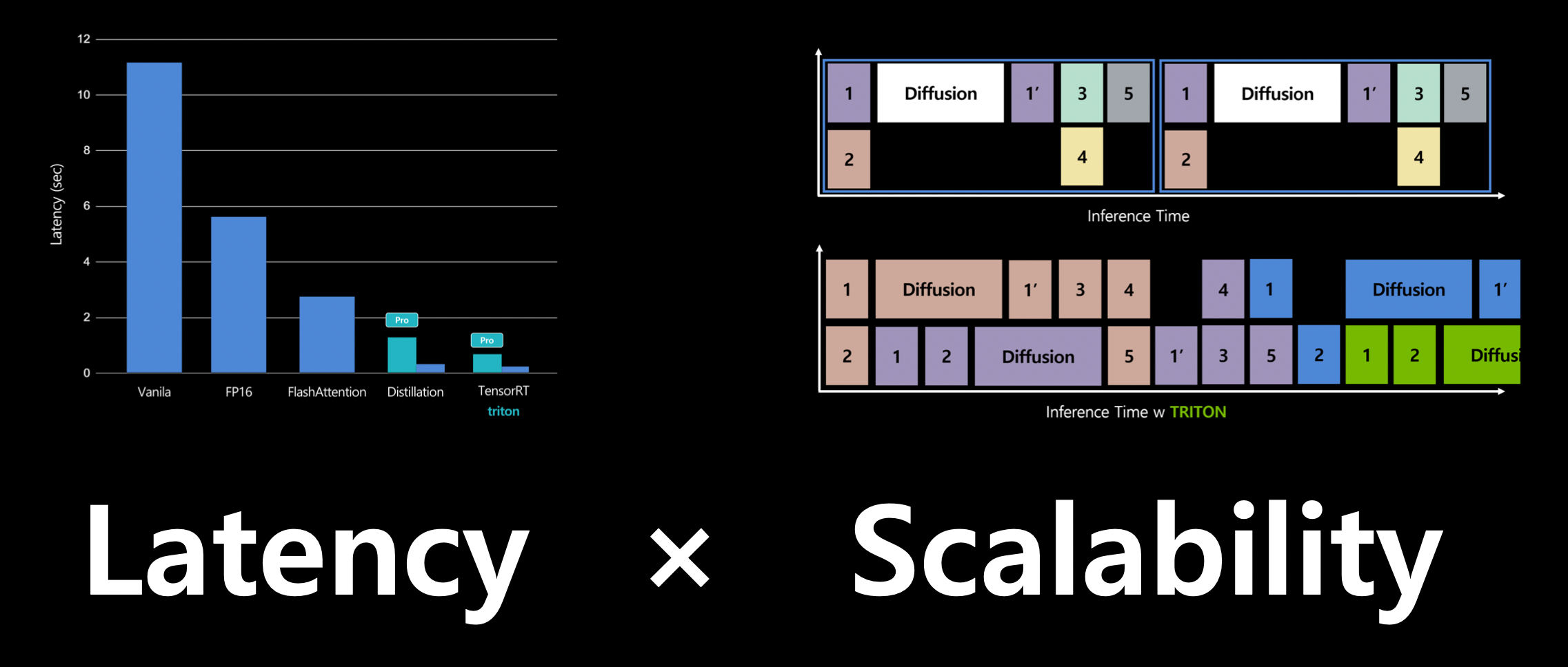 latency와 scalability를 모두 잡았다!
latency와 scalability를 모두 잡았다!
메모
- 학습 데이터를 만들 때 diffusion model을 사용하는 방법?
- GPU 구조에 대한 이해
- TensorRT, Triton
- free / pro 버전