[Paper] Face, Body, Voice: Video Person-Clustering with Multiple Modalities
📎 Paper: https://arxiv.org/abs/2105.09939
0. Abstract
- person-clustering in videos (grouping characters according to their identity)
- previous methods
- narrower task of face-clustering
- ignore other cues such as voice, appearance, and the editing structure of the videos
- contributions
- Multi-Modal High-Precision Clustering algorithm for person-clustering in videos using cues from several modalities (face, body, voice)
- Video Person-Clustering dataset
- body-tracks, face-tracks when visible, voice-tracks when speaking
- effectiveness of using multiple modalities for person-clustering
1. Introduction

- 기존의 identity clustering 방법의 대부분은 face-level 정보를 이용하는 것으로 한계가 있다.
많은 informative cues(voice, appearance, editing structure)를 무시한다.
editing structure - neighboring shots를 생각하면 된다.
story understanding과 같은 downstream application에서의 사용성을 제한한다.
보이지 않는 모든 등장인물에 대해 알아야 story-line을 이해할 수 있다.
⇒ 따라서 multi-modal 형태의 person-level 정보를 사용하는 person-clustering 방법을 제안한다.
- 한 사람에 대한 multiple modalities가 사용될 수 있는 곳은 다음과 같다.
- how to obtain pure clusters
how to merge clusters w/o violating their purity
multiple modalities는 unmergeable clusters에 대해 bridge 역할을 한다.
- Multi-Modal High-Precision Clustering (MuHPC)
- multiple modalities를 사용한다. (face, voice, body appearance)
- first nearest neighbour clustering algorithms를 기반으로 설계했다.
- cannot-link constraints와 video editing structure도 이용한다.
- Video Person-Clustering Dataset (VPCD)
- 기존 face-clustering dataset의 경우, skin color가 다양하지 않다.
- 기존 face dataset 대비 개선한 사항은 다음과 같다.
- person-level multi-modal annotations를 추가했다. (person-tracks, voice utterances)
- 다른 TV show와 films를 추가했다. (→ program sets라고 명명한다.)
- 모든 annotated characters에 대해 포함하는 정보는 다음과 같다.
- body-tracks
- face-tracks (when visible)
- voice utterances (when speaking)
- 새로운 architecture를 제안하거나 새로운 network를 학습시키는 것이 아니다.
- face / speaker recognition은 pre-trained networks에서 얻은 feature를 사용한다.
- body Re-ID에 대해서만 network를 학습시킨다.
2. Comparison to Related Work
- Face-Clustering
- [previous] “face” clustering에 국한되어 있다.
- [our work] multi-modal person-clustering을 통해 face가 visible 한지와는 상관 없이 clustering이 가능하다.
- Face-Labelling
- [previous] label 정보나 external sources가 필요했다.
- [our work] label이 아닌 cluster 작업이므로, character-classifiers, ID supervision, 혹은 extra annotation이 필요하지 않다. 그 대신 editing structure나 multi-modality 등의 이용 가능한 모든 cue를 사용한다.
- Person Re-ID
- [our work] video에서 track-level에서의 모든 charater를 cluster하므로 search queries가 필요하지 않다.
- Related Datsets
- [preivous] demographic groups를 under-represent하며, face annotation 만을 포함한다.
- [our work] 6개의 다른 TV show와 movie에 대해 다양한 characters의 multi-modal annotations를 포함한다.
- Story Understanding
- [our work] scene 안에 누가 존재하는지에 대해 집중한다.
3. Multi-Modal High-Precision Clustering (MuHPC)
3-1. Features
- single hierarchical agglomerative clustering (HAC) approach이다.
- similarities of modality features와 constraints from the video structure를 이용하여 person-tracks를 묶는다.
- pre-computed features를 사용하므로, optimal hyper-parameter를 학습시킬 때 외에는 training이 필요하지 않다.
- 여기에서는 face, voice, body appearance 총 3개의 modalities를 사용하지만, 쉽게 더 추가할 수 있다.
3-2. Notation
dataset은 person-tracks \(x_i\)와 \(C\)개의 characters로 이루어져 있다.
모든 \(x_i\)를 identity로 묶어 \(C\)개의 cluster로 만드는 것이 목표! (\(C\)는 unknown)
각 person-track \(x_i\)는 multi-modality를 포함하는 하나의 feature vector로 나타낼 수 있다.
\[x=\{x_f, x_v, x_b\}\]- 각각 face, voice, body에 관한 feature이다.
- face/body가 visible 한지, 혹은 speaking 인지에 따라 종속적이다.
- 하나의 modality에 대해 두 track features 간의 distance는 \(d(x_i, x_j)\)라고 한다.
- NN은 nearest neighbor로, \(n_{x_i}^1\)은 track \(x_i\)의 첫 번째 NN track이다.
- \(x_i\)가 존재하는 video frame의 집합을 \(T_i\)라고 한다.
- 각 cluster partition은 \(\Gamma\)라고 한다.
3-3. Three stages
- single modality(= face)를 이용해 high-precision clusters를 \(K_1\)개 생성한다.
- HAC을 여러 번 iterate 하여 first nearest neighbour(NN)를 공유하는 person-tracks 끼리 묶는다.
- 다음의 두 additional constaints에 종속적이다. (= 다음을 만족해야 NN이 valid 하다.)
spatio-temporal cannot-link constraint for concurrent tracks
일시적으로 겹치는 track은 같은 group으로 묶이면 안된다. 한 사람은 하나의 frame에서 단 한 번 등장하기 때문이다.
NN distance constraint (= conservative threshold in the maximum NN distances)
\(d_f<\tau_f^{tight}\)
⇒ track과 첫번째 NN 간의 distance \(d_f(x_i, n_{x_i}^1)\)는 \(\tau_f^{tight}\) 보다 작아야 한다.
- 각 cluster parition \(\Gamma\)에서, 다음의 조건 중 하나를 만족하는 tracks를 merge하여 \(K_\Gamma\) 개의 clusters를 생성한다. 이는 adjancency matrix로 나타낸다.
- 서로, 혹은 일방적으로 first NN인 경우
공통의 NN \(n_{x_i}^1\)을 가지는 경우
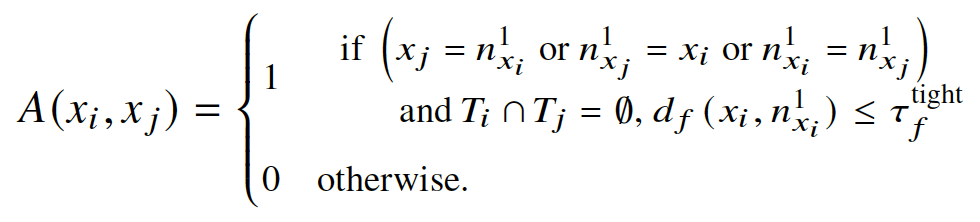
- stopping criteria는 다음과 같다. (둘 중 하나 만족 시 stop)
- 모든 clusters 간의 distance가 \(\tau_f^{tight}\) 보다 큰 경우
- 모든 clusters가 cannot-link constraint로 분리된 경우
- \(K_1\) 개의 high-precision clusters(\(K_1 \ge C\))가 생성된다.
- multi-modality(= face and voice)를 이용해 single face modality로는 unmergeable 했던 cluster들을 합쳐준다.
- bridge 역할을 하는 것이다.
face와 voice distance에 대한 새로운 threshold를 지정한다.
\(d_f<\tau_f^{loose}\) 이고 \(d_v<\tau_v^{loose}\) 일 때 merge clusters!
\(K_2\) 개의 high-precision clusters(\(K_2 \le K_1\))가 생성된다.
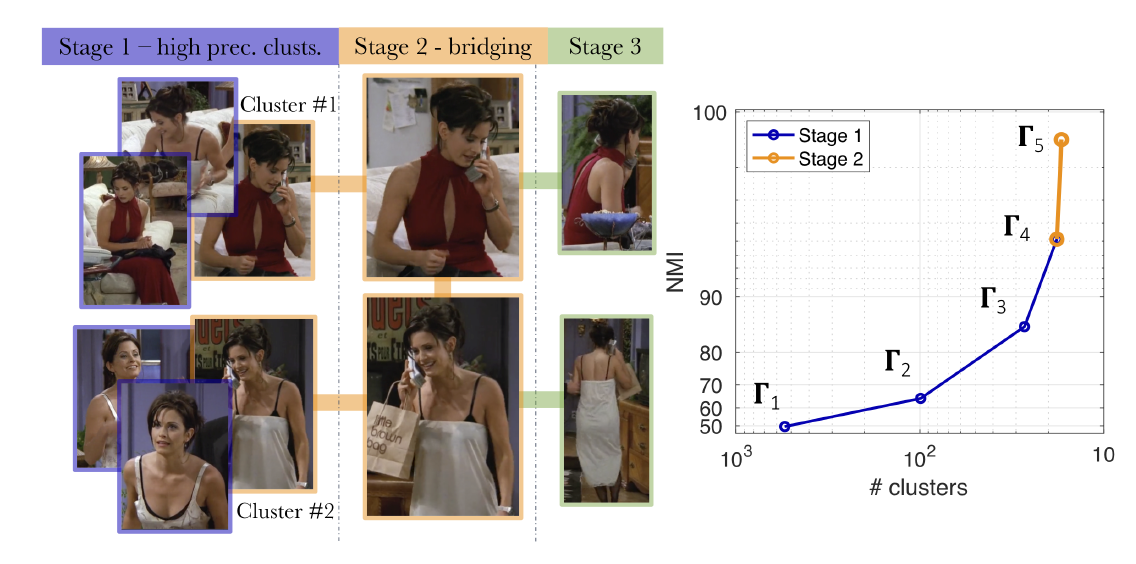
- visible faces가 없어 앞 단계에서 clustered 되지 못한 tracks를 기존의 clusters와 연결해준다.
- body-appearance를 이용하여 face-less person-tracks를 앞 단계의 high-precision clusters에 이어준다.
- 다음의 두 constraints를 사용한다.
- editing structure (neighboring shots인지)
- conservative threshold on body features (same person w/ same clothing)
- ratio-test를 수행한다.
- 각 body-track에 대해 first & second NN distance를 구한다.
\(d_{b,x_i}^2/d_{b, x_i}^1 > \rho\) 인 body-track은 ignore 한다. (\(\rho\) = threshold)
back(뒷모습)의 경우, cluster 되기 어려운 경우가 많다. 따라서 새로운 threshold를 설정해 \(d_b>\tau_b^{back}\)인 것들은 ignore 하는 방법을 사용한다.
- Stage 3에서는 cluster의 개수가 \(K_2\)에서 변하지 않는다!
 Buffy
Buffy
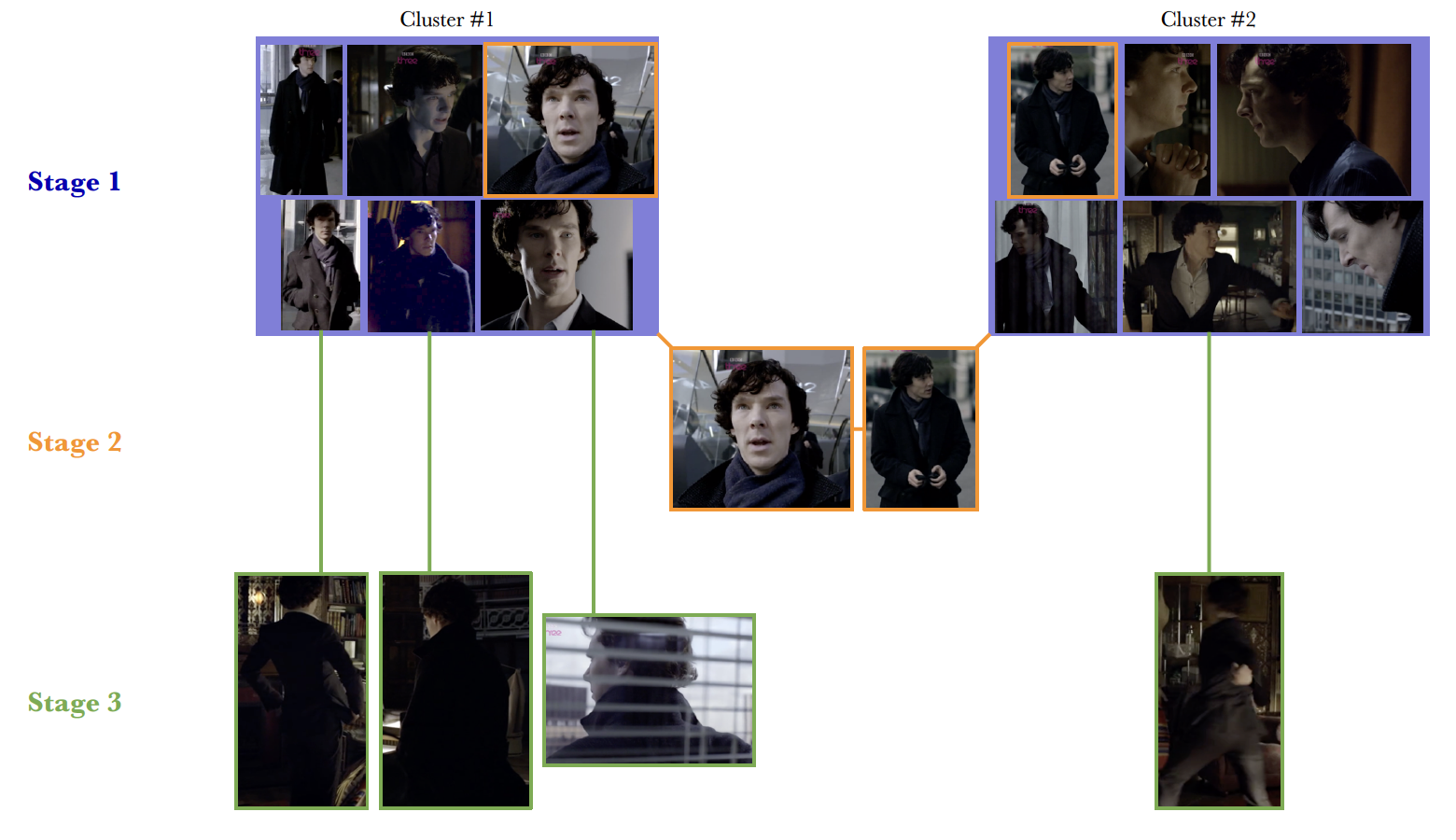 Sherlock
Sherlock
3-4. Number of Clusters
- 최종 cluster 개수인 \(K_2\)를 \(C\)에 가깝게 만드는 것이 목표이다.
- [Idea] largest cluster 간에는 identity overlap이 잘 발생하지 않는다. 하지만 small cluster와 large cluster 간에는 overlap이 존재하기 쉽다.
- large cluster는 해당 identity에 대해 충분한 정보를 담고 있다.
- 만약 두 large clusters가 같은 identity를 포함한다면, merge 되었을 것이다.
- 즉, 반복적으로 smallest와 largest cluster를 merge 하여 \(K_2\)가 \(C\)에 가까워지도록 하자!
3-5. Pre-trained
- [previous] video dataset에 대해 character features를 fine-tune 한다.
- [our work] pre-trained features를 사용하므로 다음의 장점이 있다.
- reducing the computational burden
- leading to incread generalisation capabilities
3-6. Hyper-parameters
VPCD의 validation parition을 통해 학습한다. 여기에서는 constant 값으로 사용한다.
\(\tau_f^{loose}\) (face modality와 관련)
face feature가 대용량의 dataset에서 이미 학습되어 있기 때문에 discriminative 하고 universal 하다.
일반화 good!
\(\tau_v^{loose}\) (voice modality와 관련)
less universal 하므로, 하나의 값이 다른 program sets에 대해 잘 generalise 되지 않는다.
따라서 각 program set에 대해 automatically 하게 학습한다.
\(\tau_v^{loose}\) 가 다른 사람의 voices 간의 minimum distance보다 작은 값을 가지도록 한다.
cannot-link speaking face-tracks와 Stage1의 clusters를 사용하여 example을 더 만들어서 distances를 구하고, 이 분포를 이용하여 \(\tau_v^{loose}\)를 구한다. 2개의 face-tracks가 same shot에서 말하는 경우는 거의 없기 때문이다.
비슷한 목소리를 가진 character가 많은 program set의 경우, \(\tau_v^{loose}\)는 낮은 값을 가질 것이다.
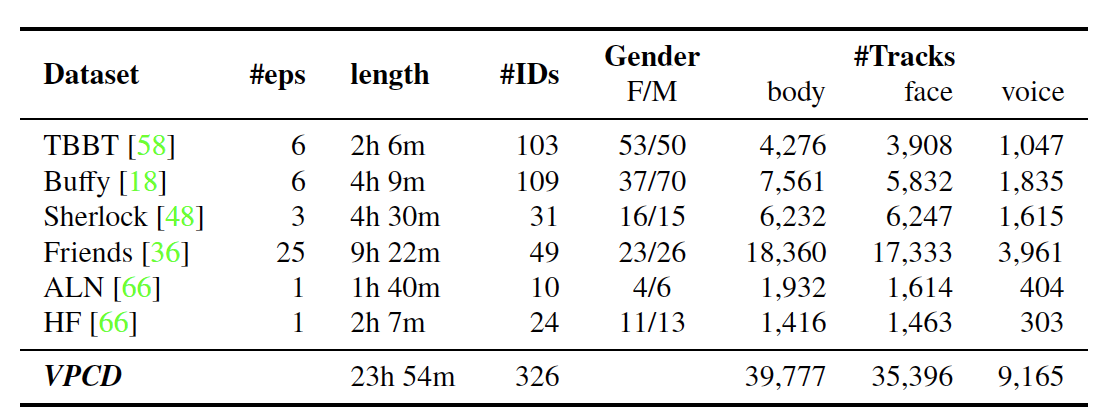
4. Video Person-Clustering Dataset (VPCD)
4-1. Contents
- 다양한 TV show와 movie 속의 다양한 등장인물들에 대해서 full multi-modal annotations을 담고 있다.
- val. set과 test set을 포함한다.
- voice-track의 특징
- laughter도 포함한다. (ex. TBBT/Friends의 live studio audience, character의 laughter)
- 여러 개의 voice-track이 겹치는 경우나, 너무 짧은 경우는 ignore 한다.

4-2. Annotation Process
automatic & manual annotation methods를 모두 사용한다.
- Face
- previous works에서 제공하고 있는 original datasets의 face bbox, track annotations, ID labels를 이용하므로 automatic 이다.
- Body
- annotation 방법
- MovieNet 데이터셋으로 train 된 Cascade R-CNN을 이용하여 body를 detect 한다.
- IoU tracker를 사용하여 tracks를 생성한다.
- 두 가지 경우
- body-track이 face-track과 명확하게 대응되는 경우 (ex. 다른 face-track과 유의미한 IoU 값을 가지지 않는 경우)
- 해당 face-track의 정보로 automatically annotated 된다.
- Hungarian Algorithm을 사용한다.
- 그 외의 경우 (ex. face-less)
- manually annotate 한다.
- 평균적으로 전체 body-track의 10~15% 정도에 해당했다.
- body-track이 face-track과 명확하게 대응되는 경우 (ex. 다른 face-track과 유의미한 IoU 값을 가지지 않는 경우)
- annotation 방법
- Voice
- 모든 character에 대해 speaking parts를 manually segment 한다.
4-3. Feature Extraction

5. Experiments
5-1. Detail Settings
- feature distance \(d_f, d_b, d_v\)는 모두
1 - cosine similarity로 계산한다. VPCD val. set에서 학습한 hyperparameters는 다음과 같다.
\[\tau_f^{tight}=0.48, \text{ }\delta=0.025, \text{ }\rho=0.9, \text{ }\tau_b^{back}=0.4\]⇒ features가 바뀔 때에만 재학습하면 된다.
[Appendix] 학습된 parameter는 different program sets에서 잘 generalise 한다.
- face features가 universal 하며, VPCD 내의 program sets가 visually disparate 하기 때문이다.
- MuHPC는 VPCD에 없는 다양한 program sets에서도 잘 동작할 것이다!
5-2. Metrics
- Weighted Cluster Purity (WCP)
- 해당 cluster 내부의 track 개수를 통해 해당 cluster의 purity를 나타낸다.
- 해당 cluster의 WCP = 1일 때, 모든 sample이 같은 class에서 왔다는 뜻이다.
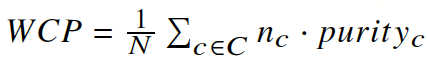
- Normalized Mutual Information (NMI)
- clustering quality와 cluster 개수 간의 trade-off를 측정한다.
- Character Precision & Recall (CP, CR)
- WCP, NMI와 다르게 ground truth identities의 개수를 사용한다.
- CP - 각 character에 assign 된 cluster 내에서의 tracks의 비율을 나타낸다.
- CR - 해당 character의 total tracks 중 cluster에 나타나는 track의 비율을 나타낸다.
- 모든 character에 대해 평균으로 구한다.
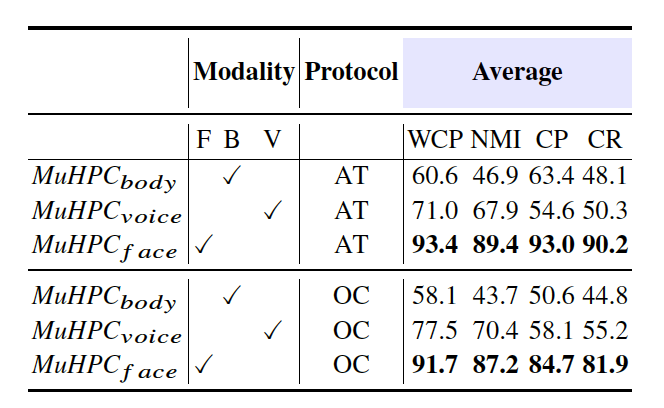 Stage 1에서의 결과 → Stage 1에서는 face를 이용한다.
Stage 1에서의 결과 → Stage 1에서는 face를 이용한다.
5-3. Test Protocol
- Automatic Termination (AT) - cluster 개수가 알려지지 않은 realistic 한 상황
- Oracle Cluster (OC) - cluster 개수가 알려진 상황 (SOTA와의 비교를 위해서)
5-4. Person-Clustering
realistic 한 상황에서의 비교를 위해 AT protocol 하에서 실험하였다.
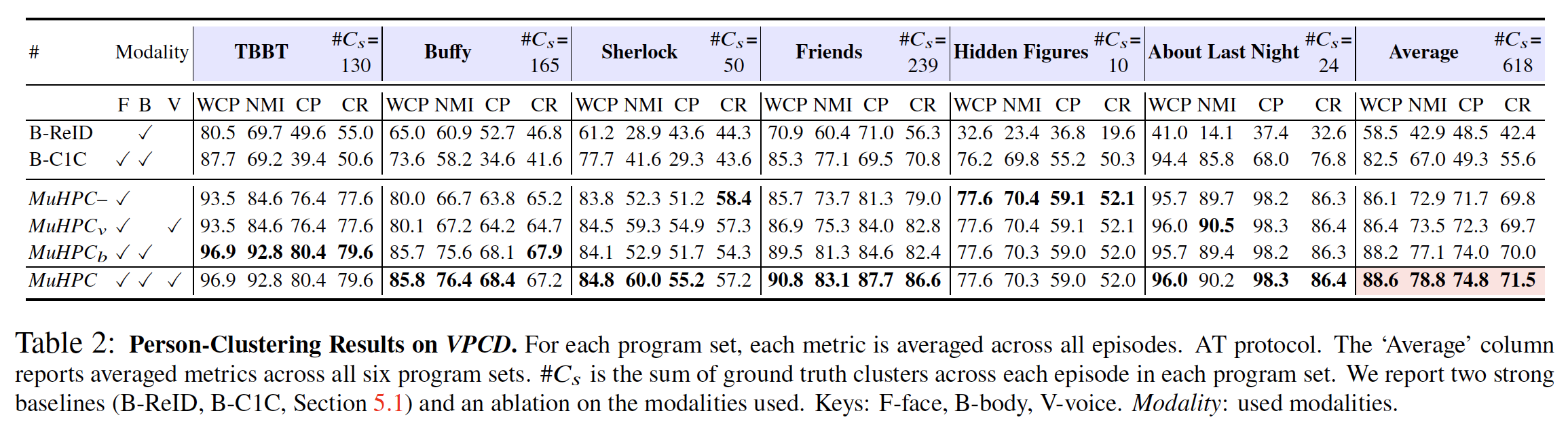
- MuHPC가 기존의 가장 성능이 좋은 face-clustering algorithms보다 significantly outperform 하였다.
- MuHPC에 voice, body를 추가하는 경우, 대부분의 program set에서 성능이 향상되었다.
- 하지만 Hidden Figures의 경우, body를 추가한다고 해서 성능이 향상되지 않았다.
- 많은 dark scenes와 non-distinctive clothing이 나오기 때문이다.
- 이런 경우에는 face-less bodies를 cluster 하기 위해서 temporal-NN 등의 방법을 사용해 볼 수 있다.
5-5. Face-Clustering
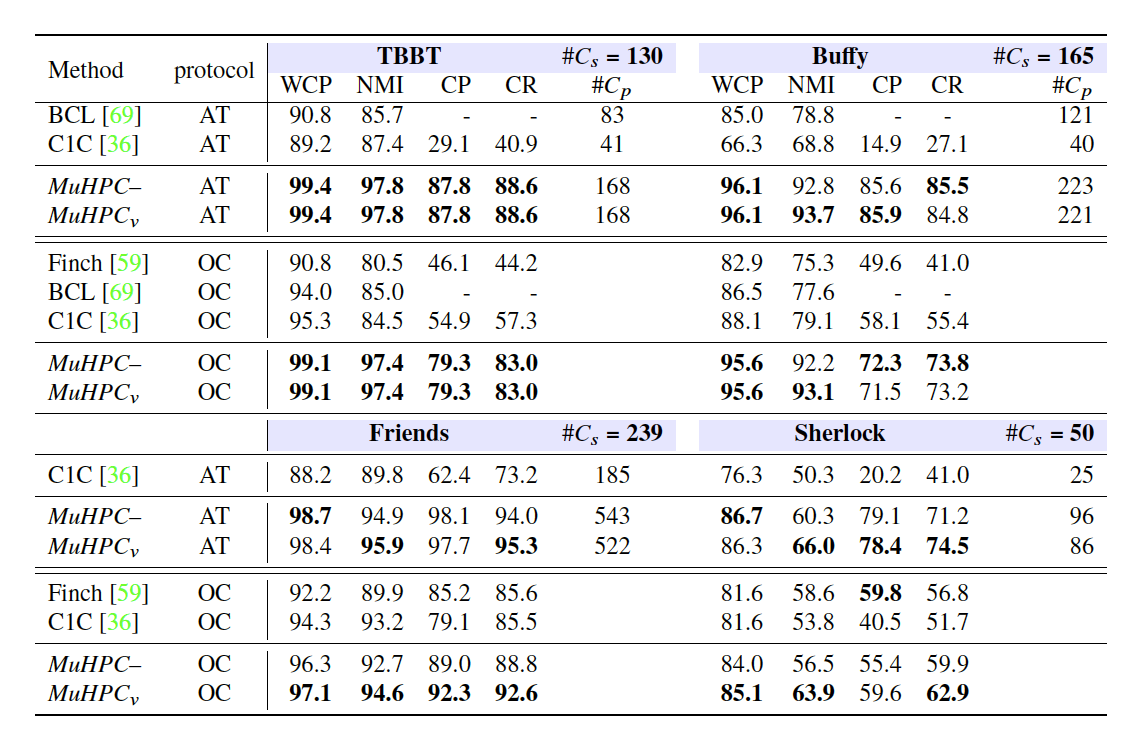
- 오직 face-tracks만 사용하여 previous works와 비교하였다.
- AT와 OC protocol 모두에서 MuHPC가 기존의 face-clustering algorithms보다 significantly outperform 하였다.
- dataset의 난이도가 더 어려울수록, multi-modality의 효과가 더 크게 나타났다.
5-6. Enabling Story Understanding
- story understanding을 위해서는 누가 해당 scene에 존재하는지를 알아야 하는데, 이는 person-clustering으로 해결 된다.
- 이를 통해 character co-occurrences를 예측할 수 있다. 이는 곧 character 간의 interaction 정도라고 할 수 있다.
 TBBT의 character co-occurrences
TBBT의 character co-occurrences
- person-level GT를 보면, Sheldon과 Leonard는 전체 frame의 24%에서, 연인 관계인 Penny와 Leonard는 전체 frame의 9%에서 함께 등장한다는 것을 알 수 있다.
- face-level GT의 경우, GT 임에도 불구하고 Penny와 Leonard의 관계가 3%로, 다른 관계와 다를 바 없이 나타난다.
- MuHPC의 결과, person-level GT와 매우 비슷하게 나온다.
- 본 방법을 통해 co-occurrence, 즉 interaction을 자동으로 정확하게 찾을 수 있다.
6. Conclusion
- 새로운 multi-modal person-clustering 방법인 MuHPC를 제안하였다.
- 해당 분야에서 가장 크고 다양한 dataset인 VPCD를 제작하였다.
- MuHPC와 VPCD를 통해 큰 성능 향상을 이끌어냈다.
- 각 character의 appearance와 co-occurrence를 자동으로 정확하게 예측할 수 있다.
7. Additional Materials
네이버 부스트캠프 AI Tech 최종 프로젝트에 적용하기 위해 찾아봤었던 여러 자료들
저자의 설명 영상: Face, Body, Voice: Video Person-Clustering with Multiple Modalities - Spotlight
ICCV 2021 open access: ICCV 2021 Open Access Repository
Video Person-Clustering Dataset: VPCD
GitHub: Video_Person_Clustering (코드는 커밍쑨이라 한다…)
-
VPCD README.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62
This README details the contents of the VPCD dataset tar.gz For any questions, email Andrew Brown: abrown@robots.ox.ac.uk If you find this dataset useful, please consider citing: @misc{Brown21c, author = "Andrew Brown and Vicky Kalogeiton and Andrew Zisserman ", title = "Face, Body, Voice: Video Person-Clustering with Multiple Modalities", year={2021}, archivePrefix={arXiv}, primaryClass={cs.CV} } VPCD consists of person-tracks, and voice-tracks. Each person-track consists of either a face-track, or a body-track, or both. A face-track consists of linked face-detections in time. A body-track consists of linked body-detections in time. The entire audio-track of each program set is manually diarised into individual voice-tracks, which are all identity labelled. Assigning voice-tracks to person-tracks: Voice-tracks can be linked to person-tracks by looking at temporal intersection between voice-tracks and person-tracks that are labelled with the same identity. Most of the time, for each voice-track there will be a co-occuring person-track with the same-ground truth label. Occasionally a voice-track corresponds to someone who is off camera. In these cases there will be no co-occurring person-track. VPCD.zip contains a pickle file for each of the program sets included in VPCD. Each pickle file stores a python dictionary data structure. Each key corresponds to each episode of the program set. Each value stores another dictionary with the following keys: 1) ‘face’ This is a python dictionary, where each key is a person-track identifier, and the values are the face-track coordinates of the face-track for this person-track. The face-track coordinates are a numpy array where each row details a face detection in the track and is structured as [frame number, x1, y1, x2, y2]. 2) ‘face_feats’ This is a python dictionary, where each key is a person-track identifier, and the values are the 256D identity-discriminating features for the face-tracks, extracted from a SE-NET50 trained on VGGFace2 and MS1M (https://arxiv.org/abs/1710.08092). The features are stored in a numpy array where each row corresponds to the feature for that given face-detection in the face-track. 3) ‘GT’ This is a python dictionary, where each key is a person-track identifier, and the values are the ground-truth labels. 4) 'body' This is a python dictionary, where each key is a person-track identifier, and the values are the body-track coordinates of the body-track for this person-track. The body-track coordinates are a numpy array where each row details a body detection in the track and is structured as [frame number, x1, y1, x2, y2]. 5) 'body_feats' This is a python dictionary, where each key is a person-track identifier, and the values are the 256D identity-discriminating features for the body-tracks, extracted from a ResNet50 trained on Cast-Search in Movies (https://arxiv.org/abs/1807.10510). The features are stored in a numpy array where each row corresponds to the feature for that given body-detection in the body-track. 6) 'back' This is a python dictionary, where each key is a person-track identifier, and the values are the body-track coordinates of the body-track for this person-track. The person-tracks here are those where the face is not visible, hence there is no matching face-track, and hence the 'back' label. The body-track coordinates are a numpy array where each row details a body detection in the track and is structured as [frame number, x1, y1, x2, y2]. 7) 'back_feats' Same as 'body_feats', but for the person-tracks with no matching faces. 8) 'back_GT' same as 'GT', but for the person-tracks with no matching faces. 9) 'Voice' This is a python dictionary containing the annotations for the audio track diarisation. Each key is a ground truth label (the same as those in ‘GT’). Each value is a dictionary which details all of the voice-tracks in the episode that are labelled as being spoken by this ground truth label (identity), with the following keys: 9i) 'starts' - This is a list, detailing the start times (in seconds) of each of the voice-tracks. 9ii) 'ends' - This is a list, detailing the end times (in seconds) of each of the voice-tracks. 9iii) 'frames' - This is a list, detailing the frames that (in seconds) each of the voice-tracks are spoken in. 9iv) 'features' - The 512D identity-discriminating features extracted from a Thick-ResNet34 trained on VoxCeleb2 (https://arxiv.org/pdf/1806.05622.pdf). In some program sets, there is a key in the 'voice' dictionary labelled as “laughter”. This label is given to voice-tracks corresponding to laughter (either live studio audience, or a character’s laughter).