[Network] 5. 애플리케이션 계층
본문은 “그림으로 공부하는 TCP/IP 구조” 및 각종 자료를 읽고 재구성한 글임을 밝힙니다.
웹브라우저에서 웹서버에 연결하는 경우, 패킷은 물리 계층 → 데이터링크 계층 → 네트워크 계층 프로토콜을 통해 웹서버까지 전송되며, 트랜스포트 계층 프로토콜에서 HTTP 애플리케이션에 선별되고, 애플리케이션 계층 프로토콜에서 HTTP 서버 애플리케이션을 통해 처리된다.
애플리케이션 계층의 프로토콜은 세션 계층(L5), 프레젠테이션 계층(L6), 애플리케이션 계층(L7)을 모아서 하나의 애플리케이션 프로토콜로 표준화되었다. 여기에서는 대표적인 프로토콜인 HTTP, HTTPS, DNS에 대해 다뤄본다.
1. HTTP (Hypertext Transfer Protocol)
웹브라우저는 URL 앞 부분의 http를 보고 “HTTP로 액세스한다”라고 웹서버에게 선언하면서 요청을 송신한다.
1-1. HTTP 버전
- HTTP/0.9
- HTML로 기술된 텍스트 파일을 서버에서 다운로드하기 위한 단순한 것이었다.
- HTTP/1.0
- 텍스트 파일 이외에도 다양한 파일을 다룰 수 있게 되었고, 다운로드뿐만 아니라 업로드, 삭제도 가능해졌다.
- 메시지(데이터)의 포맷, 요정, 응답의 기본적인 사용이 확립되었다.
(HTTP/0.9 & HTTP/1.0) 리퀘스트마다 TCP 커넥션을 만들고 닫았기 때문에 서버에 부하가 많이 갔다.
웹브라우저는 하나의 서버에 대해 동시에 오픈할 수 있는 TCP 커넥션 수가 결정되어 있으며, 최근의 기본값은
6이다.
- HTTP/1.1: TCP 레벨에서 퍼포먼스 향상을 목표로 하는 기능이 추가되었다.
- 킵얼라이브(keep-alive)
- 한 번 만들어진 TCP 커넥션에서 여러 HTTP 요청을 송신함으로써 재사용하는 기능이다.
- HTTP/1.0까지는 콘텐츠별로 TCP 커넥션 처리가 수행되었지만 이를 제거할 수 있게 되었다.
- 장점
- 신규 커넥션 수가 줄어든다.
- 시스템 전체의 처리 부하가 크게 줄어든다.
- TCP 핸드셰이크의 패킷 왕복 시간(RTT)이 짧아지므로 처리량이 증가한다.
- 파이프라인(pipeline)
- 요청에 대한 응답을 기다리지 않고 다음 요청을 송신하는 기능이다.
- HoL 블로킹(Head of Lock) 문제로 거의 사용되지 않는다.
- HTTP/1.1은 같은 TCP 커넥션 안에서 요청과 응답의 교환을 병렬 처리할 수 없는 사양이었기 때문에 서버는 요청을 받은 순서대로 응답을 반환해야만 했다.
- 클라이언트가 파이프라인으로 2개의 요청을 연속해서 송신했을 때, 서버가 첫 번째 요청을 처리하는 데에 시간이 걸리면 그 동안 이어진 요청에 대한 응답도 반환하지 않는다.
- 리퀘스트 순서에 맞게 리스폰스를 반환해야 하기 때문이다.
- 킵얼라이브(keep-alive)
- HTTP/2
- 애플리케이션 데이터를 텍스트 형식의 메시지 단위가 아닌 프레임(frame)이라는 바이너리 형식 단위로 교환한다. (오버헤드 감소 & 성능 향상)
- 애플리케이션 레벨에서도 성능 향상을 목표로 하는 기능들이 추가되었다.
- 멀티플렉싱(multiplexing)
- HoL 블록킹 문제를 가지고 있었던 HTTP/1.1의 파이프라인을 대신하여 추가된 기능이다.
- 1개의 TCP 커넥션 안에 스트림(stream)이라는 가상 채널을 만들고, 스트림별로 요청과 응답을 교환하게 함으로써 HoL 문제를 해결한다.
- 1개의 TCP 커넥션으로 파이프라인과 같은 병렬 처리를 구현할 수 있다. (최소한의 TCP 처리 부하, 최대한의 성능)
- HPACK
- 메시지 헤더를 압축하는 기능으로, 헤더의 전송량을 줄이는 것이 목표이다.
- HTTP/1.1은 같은 내용의 헤더를 수차례 교환하므로 낭비가 많았으며, 압축하는 기능이 메시지 바디에만 적용되었다.
- 서버 푸시
- HTTP/1.1까지는 하나의 요청에 대해 하나의 응답을 반환하는 풀 타입 프로토콜이었다.
- HTTP/2에서는 하나의 요청에 대해 여러 응답을 반환하는 푸시 타입 기능을 추가했으며, 이를 서버 푸시라 한다.
서버는 클라이언트가 최초로 요청한 컨텐츠를 해석하고, 다음에 올 요청에 대한 응답을 요청이 오기 전에 보낸다. 웹 브라우저는 그 응답을 캐시하고, 요청에 대한 응답을 캐시 영역에서 호출한다.
ex)
index.html이script.js와style.css를 로딩한다면,index.html에 대한 요청 뒤에 나머지 파일에 대한 요청이 올 것을 예상할 수 있으므로 서버는 그 요청이 오기 전에 미리 응답한다. 웹 브라우저는 그 응답을 캐시해두고, 두 파일의 요청에 대한 응답을 캐시 영역에서 호출한다.
- 멀티플렉싱(multiplexing)
1-2. HTTP 메시지 포맷
HTTP에서 교환하는 정보를 HTTP 메시지라하며, 웹브라우저가 서버에 처리를 요청하는 리퀘스트 메시지, 서버가 웹브라우저에 처리 결과를 반환하는 리스폰스 메시지의 두 가지가 있다.
두 메시지 모두 다음과 같은 구조로 구성된다.
스타트 라인: 메시지 종류를 나타낸다.
리퀘스트 메시지의 경우 리퀘스트 라인이라고 하며, 리스폰스 메시지의 경우 스테이터스 라인이라 한다.
- 리퀘스트 라인: 임의의 HTTP 버전에서 URI로 나타나는 웹서버 상의 리소스에 대해 메서드를 사용해 처리를 요청한다.
메서드: 클라이언트가 서버에 대해 요청하는 리퀘스트의 종류
GET, POST, PUT, DELETE, …
- 리퀘스트 URI: 서버의 장소, 파일 이름, 파라미터 등 다양한 리소스를 식별하기 위해 사용하는 문자열
- 절대 URI, 상대 URL
- URI 중에는 URL(Uniform Resource Locator)이 있으며, 웹사이트에 접속할 때 입력하는 주소로 네트워크에서 서버의 위치를 나타낸다.
- HTTP 버전
- 스테이터스 라인: 웹서버가 웹브라우저에 대해 처리 결과의 개요를 반환하는 행이다.
- HTTP 버전
- 스테이터스 코드 (status code)
- 리즌 프레이즈 (스테이터스 코드와 1:1 mapping)
- 리퀘스트 라인: 임의의 HTTP 버전에서 URI로 나타나는 웹서버 상의 리소스에 대해 메서드를 사용해 처리를 요청한다.
- 메시지 헤더: 각종 제어 정보를 여러 행에 걸쳐 저장한다.
- 웹브라우저에 따라 다음의 4개 헤더 중 어떤 헤더로 구성되는지가 다르다.
- 리퀘스트 헤더/리스폰스 헤더
- 일반 헤더
- 엔티티 헤더
- 기타 헤더
- 각 헤더 필드는
<헤더 이름>:<필드 값>으로 구성된다.
- 웹브라우저에 따라 다음의 4개 헤더 중 어떤 헤더로 구성되는지가 다르다.
- 빈 줄 (
\r\n): 메시지 바디와 메시지 헤더를 구분한다. - 메시지 바디: 애플리케이션 데이터 본문이다. (HTTP 페이로드)
1-3. HTTP 헤더
다섯 종류가 있다. 웹브라우저는 필요한 헤더를 몇 가지 선택하고 줄 바꿈(\r\n)으로 구분하여 여러 행으로 구성한다.
- 리퀘스트 헤더
Accept헤더: 웹브라우저가 처리할 수 있는 파일의 종류와 그 상대적인 우선도를 웹서버에 전달하기 위해 사용된다. 웹서버는 이 정보를 기반으로 웹브라우저가 처리할 수 있는 파일을 반환한다.Host헤더: HTTP/1.1에서 유일한 필수 항목 헤더로, 웹 서버의 도메인 이름(FQDN)과 포트 번호가 설정된다.Referer헤더: 직전의 연결 소스의 URI를 나타낸다. 이를 통해 웹사이트에 대한 액세스의 출처를 알 수 있다.User-Agent헤더: 사용자 환경(웹브라우저, OS 등)을 나타낸다.
- 리스폰스 헤더
- 일반 헤더: 리퀘스트 메시지, 리스폰스 메시지 모두에서 범용으로 사용하는 헤더이다.
Cache-Control헤더: 웹브라우저나 서버의 캐시를 제어하기 위해 사용한다.- 캐시란 한 번 액세스한 웹페이지의 데이터를 지정한 디렉토리에 저장하는 기능이다.
- 프라이빗 캐시: 주로 웹브라우저에 저장된다.
- 공유 캐시: 주로 프록시 서버나 CDN의 에지 서버에 저장된다.
Connection헤더 /Keep-Alive헤더: 킵얼라이브를 제어한다.- 웹브라우저는
Connection: keep-alive설정하여 웹서버에 전달한다. - 웹서버는
Connection: keep-alive설정과 함께Keep-Alive: timeout=XX, max=YY등의 관련 정보를 전달한다. Connection: close로 설정되면 TCP 커넥션을 닫는다.
- 웹브라우저는
- 엔티티 헤더: 메시지 바디에 관련된 제어 정보를 포함한다.
Content-Encoding헤더 /Accept-Encoding헤더: 웹브라우저가 처리할 수 있는 메시지 바디의 압축 방식을 지정한다.- 웹서버는
Accept-Encoding헤더 안에서 선택한 형식으로 HTTP 메시지를 압축하고, 그 방식을Content-Encoding헤더에 설정한 뒤 웹브라우저에 리스폰스한다.
- 웹서버는
Content-Length헤더: HTTP/1.1에서는 킵얼라이브에 따라 하나의 커넥션을 재활용하는 경우가 있기 때문에 반드시 TCP 커넥션이 클로즈된다고 단언할 수 없다. 따라서 이 헤더를 통해 메시지의 경계를 TCP에 전달하고, 적절하게 TCP 커넥션이 클로즈되도록 한다.
- 기타 헤더
Set-Cookie헤더 /Cookie헤더:- 쿠키란, HTTP 헤더와의 통신에서 특정한 정보를 브라우저에 저장하는 구조 및 저장한 파일이다.
- 쿠키는 웹브라우저 상에서 FQDN(Fully Qualified Domain Name) 별로 관리된다.
- ex) 쿠키를 사용한 자동 로그인
- 웹브라우저에서 사용자 이름과 비밀번호를 입력한다.
- 서버는 세션 ID를 발행하고,
Set-Cookie헤더에 설정해서 리스폰스한다. - 웹브라우저는 쿠키를 메모리 저장소에 저장하고, 그 뒤의 리퀘스트의
Cookie헤더에 세션 ID를 설정한다. - 서버는
Cookie값을 보고 사용자를 인식한다.
X-Forwarded-For헤더: 부하 분산 장치에서 송신지 IP 주소가 변환되는 환경에서, 변환 전의 송신지 IP 주소를 저장하는 헤더이다.X-Forwarded-Proto헤더:X-Forwarded-For의 프로토콜 버전이다. 부하 분산 장치에서 프로토콜이 변화되는 환경에서, 변환 전 원래의 프로토콜을 저장한다.- SSL 오프로드(부하 분산 장치에 처리 부하가 되기 쉬운 SSL 처리를 서버에서 대신하여 부하 분산 장치가 HTTPS를 복호화하여 HTTP로 변환)하면 서버 측에서 웹브라우저가 리퀘스트에 사용한 원 프로토콜을 알 수 없다.
2. 부하 분산 장치(Loadbalancer)
부하 분산 장치는 네트워크 계층(IP 주소)이나 트랜스포트 계층(포트 번호), 애플리케이션 계층(메시지)의 정보를 이용해 여러 서버에 커넥션을 할당한다.
2-1. 수신지 NAT
수신지 NAT란 패킷의 수신지 IP 주소를 변환하는 기술이다. 부하 분산 장치는 클라이언트로부터 패킷을 받으면 서버의 살아있는 상태, 커넥션의 상태 등을 확인하고, 최적 서버의 IP 주소로 수신지 IP를 변환한다.
이러한 NAT는 커넥션 테이블의 정보를 기반으로 수행하며, 어느 커넥션을 어느 IP 주소에 수신지 NAT 할 것인지 판단한다.
커넥션 테이블의 정보
송신지 IP 주소:포트 번호가상 IP 주소(변환 전 수신지 IP 주소):포트 번호서버 IP 주소(변환 후 수신지 IP 주소):포트 번호프로토콜
- 부하 분산 장치는 가상 서버로 클라이언트의 커넥션을 받는다.
- 패킷의 수신지 IP 주소는 가상 서버의 IP 주소이다.
- 받은 커넥션은 커넥션 테이블로 관리된다.
- 부하 분산 장치는 가상 IP 주소로 된 수신지 IP 주소를, 그에 관련한 부하 분산 대상 서버의 IP 주소로 변환한다.
- 서버의 상태, 커넥션 상태 등 다양한 상태에 따라 동적으로 바꿈으로써 커넥션이 분산되게 된다.
- 변환된 IP 주소도 커넥션 테이블에 기록 및 관리된다.
- 커넥션을 받은 서버는 애플리케이션 처리를 한 뒤, 기본 게이트웨이로 되어 있는 부하 분산 장치에 반환 통신을 보낸다. 부하 분산 장치는 커넥션 테이블 정보를 이용하여, 수신지 NAT와 반대로 송신지 IP 주소를 NAT 한다.
2-2. 헬스 체크
헬스 체크란, 부하 분산 대상 서버의 상태를 감시하는 기능이다. 부하 분산 장치는 서버에 대해 정기적으로 감시 패킷을 보내어 가동 여부를 감시하고, 중단이라고 판단되면 해당 서버를 부하 분산 대상에서 제외한다.
크게 세 가지로 구분할 수 있다.
- L3 체크: IP 주소 레벨의 상태를 확인한다. (
ICMP) - L4 체크: 서비스 레벨의 상태를 확인한다. (
TCP) - L7 체크: 애플리케이션 레벨의 상태를 확인한다. (
HTTP)
실무 현장에서는 헬스 체크 시, L3 체크 + L4 체크 또는 L3 체크 + L7 체크의 조합을 자주 사용한다. 계층이 다른 두 종류의 헬스 체크를 사용함으로써, 장애가 발생했을 때 어느 계층까지 발생하는지 구분하기 쉽기 때문이다.
어떤 조합 기법을 사용하는지는 서버의 부하 상황에 따라 다르다. L3 체크는 큰 부하가 되지 않지만, L7 체크는 애플리케이션 레벨의 정보를 확인하기 때문에 상대적으로 서버에 부하가 되기 때문이다. 헬스 체크가 서비스에 영향을 미쳐서는 안 되므로, 서버의 리소스에 여유가 있다면 L3 체크 + L7 체크, 그렇지 않다면 L3 체크 + L4 체크를 선택한다.
2-3. 부하 분산 방식
“어느 정보”를 사용해 “어느 서버”로 분배하는지를 결정하는 것이다.
- 정적 부하 분산
- 서버의 상황과 관계 없이, 미리 정의된 설정에 따라 분배할 서버를 정한다.
- ex) 라운드 로빈, 비율 방식 등
- 동적 부하 분산
- 서버 상황에 맞춰 할당할 서버를 결정한다.
- ex) 최소 커넥션 수, 최단 응답 시간 방식 등
3. SSL/TLS
SSL(Secure Socket Layer)/TLS(Transport Layer Security)는 애플리케이션을 암호화하는 프로토콜이다. 데이터를 암호화하거나 통신 상대를 인증하는 등으로 중요한 데이터를 보호한다.
TLS는 SSL의 버전을 업데이트한 것으로, 앞으로는 SSL/TLS를 SSL로 표기하도록 하겠다.
웹브라우저를 사용할 때, URL이 https://~로 바뀌고 주소에 자물쇠 마크가 표시되는 것을 본 적이 있을 것이다. 이것은 통신이 SSL로 암호화되어 데이터가 보호되고 있음을 나타내며, 최근 대규모 웹사이트는 HTTP로 연결해도 HTTPS 사이트로 강제 리다이렉트된다.
HTTPS는 HyperText Transfer Protocol Secure의 약자로, HTTP를 SSL로 암호화한 것이다.
3-1. SSL로 방지할 수 있는 위협
- 암호화 → 도청 방지
- 도청이란, 제3자가 데이터를 엿보는 것이다.
- 암호화란, 정해진 규칙에 기반해 데이터를 변환하는 기술이며, 설령 도청되더라도 그 내용을 알 수 없도록 한다.
- 해시화 → 변조 방지
- 변조란, 제3자가 데이터를 바꾸는 것이다.
해시화란, 애플리케이션 데이터로부터 정해진 계산(= 해시 함수)에 기반해 고정된 길이의 데이터(= 해시값)를 추출하는 기술이다.
애플리케이션 데이터가 바뀌면 해시값도 바뀌게 된다.
- SSL은 데이터의 변조 여부를 확인하기 위해 데이터와 해시값을 함께 전송한다. 이를 받은 단말에서는 데이터로부터 해시값을 계산해서 얻은 후, 함께 전송된 해시값과 비교한다. 이때, 그 값이 같으면 데이터가 변조되지 않았음을 의미한다.
- 디지털 인증서 → 신분 위조 방지
- 디지털 인증서란, 그 단말이 진짜임을 증명하는 파일이다. 이를 통해 통신 상대가 진짜인지 아닌지를 확인한다.
- SSL에서는 데이터 송신 전 디지털 인증서를 전송받아 그것을 기반으로 올바른 상대인지를 확인한다.
- 디지털 인증서의 진위 여부는 인증 기관(CA, Certification Authority)의 디지털 서명으로 판단한다.
3-2. 암호화 방식 (for 도청 방지)
SSL의 암호화 처리에는 데이터를 암호화하기 위한 암호화키, 암호화를 풀기 위한 복호화키가 필요하다. 네트워크에서의 암호화 방식은 클라이언트와 서버의 암호화키, 복호화키를 갖는 방식에 따라 크게 공통키 암호화 방식과 공개키 암호화 방식의 2가지로 나뉜다.
- 공통키 암호화 방식
- 암호화키와 복호화키로 동일한 키(공통키)를 사용하는 암호화 방식이다. 같은 키를 대칭적으로 사용하므로 대칭키 암호화 방식이라고도 한다.
- 클라이언트와 서버는 미리 같은 키를 공유한다.
- 장점: 처리 속도가 빠르며 처리 부하가 크지 않다.
- 단점: 키를 어떻게 공유해야 할지 다른 구조로 해결해야 한다. (암호화키와 복호화키가 같기 때문에 그 키가 유출되면 안 된다!)
- 공개키 암호화 방식
- 암호화키와 복호화키로 다른 키를 사용하는 암호화 방식이며, 비대칭키 암호화 방식이라고도 한다.
- 공개키는 누구에게나 공개해도 괜찮은 키이며, 비밀키는 모두에게 비밀로 해야하는 키이다.
- 이 키 페어는 수학적인 관계로 성립하며, 한쪽 키에서 다른 한쪽 키를 도출할 수 없다. 또한, 한쪽 키에서 암호화한 데이터는 다른 한쪽 키로만 복호화할 수 있다.
- 흐름
- 웹서버는 공개키와 비밀키를 만든다.
- 웹서버는 공개키를 모두에게 공개/배포하고, 비밀키만 보관한다.
- 웹브라우저는 공개키를 암호화키로 사용해서 데이터를 암호화한 뒤 전송한다.
- 웹서버는 비밀키를 복호화키로 사용해서 데이터를 복호화한다.
- 장점: 키를 전송할 필요가 없다.
- 단점: 처리가 복잡하므로 처리에 시간이 소요되며 처리 부하도 크다.
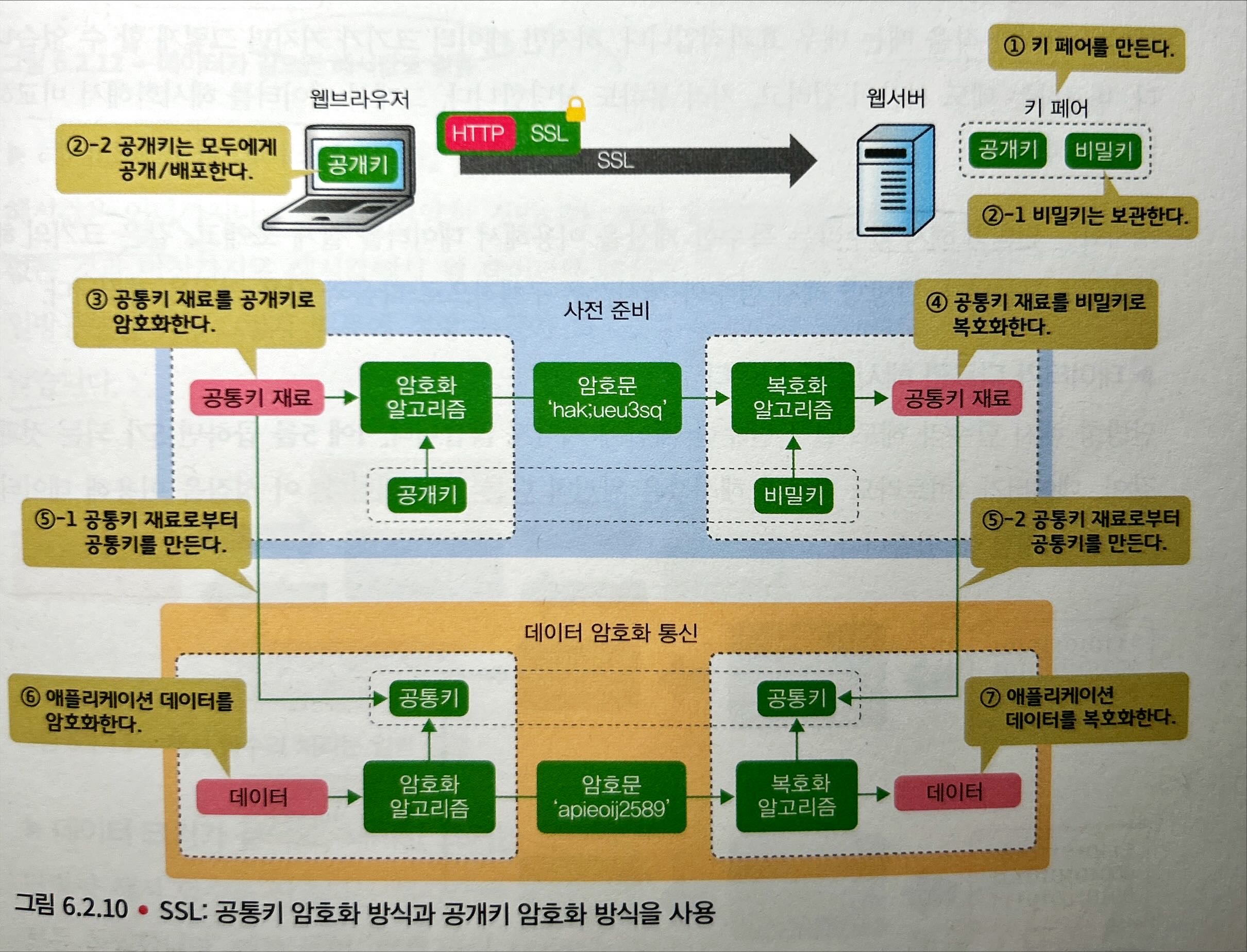
SSL은 이러한 두 방식을 조합해서 사용한다. 즉, 데이터 암호화에 효율이 좋은 공통키를 사용하기 위해 공통키를 직접 전송하는 대신 공통키의 재료를 전송하여 각자 공통키를 생성한다.
- 웹서버는 공개키와 비밀키를 만든다.
- 웹서버는 공개키를 모두에게 공개/배포하고, 비밀키만 보관한다.
- 웹브라우저는 공통키의 재료를 공개키로 암호화하여 보낸다.
- 웹서버는 공통키의 재료를 비밀키로 복호화한다.
- 웹서버와 웹브라우저는 공통키의 재료로부터 공통키를 생성한다.
- 웹브라우저는 애플리케이션 데이터를 공통키로 암호화한다.
- 웹서버는 애플리케이션 데이터를 공통키로 복호화한다.
3-3. 해시 함수 (for 변조 방지)
해시화란, 애플리케이션 데이터를 잘게 쪼개서 같은 크기의 데이터로 모으는 기술이다. 메시지 다이제스트, 핑거프린트 등으로 부르기도 한다.
데이터의 변조 여부를 확인하기 위해서 데이터 자체를 비교하는 것보다 해시값을 비교하는 편이 보다 효율적이다. 왜냐하면 데이터의 크기가 커지면 데이터 자체를 비교하기 어렵기 때문이다. 따라서 해시화는 단방향 해시 함수를 이용하여 데이터를 잘게 쪼개고, 같은 크기의 해시값으로 모은다.
단방향 해시 함수와 해시값의 특징으로는 다음과 같은 것들이 있다.
- 데이터가 다르면 해시값도 다르다.
- 데이터가 같으면 해시값도 같다.
- 해시값에서 원 데이터를 복원할 수 없다.
- 데이터 크기가 달라도, 해시값 크기는 고정된다. (속도 & 부하)
보통, 송신자는 애플리케이션 데이터와 해시값을 전송하며, 수신자는 애플리케이션 데이터로부터 해시값을 계산하고 전송된 해시값과 계산한 값을 비교한다. 그리고 그 결과가 일치하면 변조되지 않았고, 일치하지 않으면 변조되었다고 판단한다.
SSL에서는 해시화를 다음의 두 용도로 사용한다.
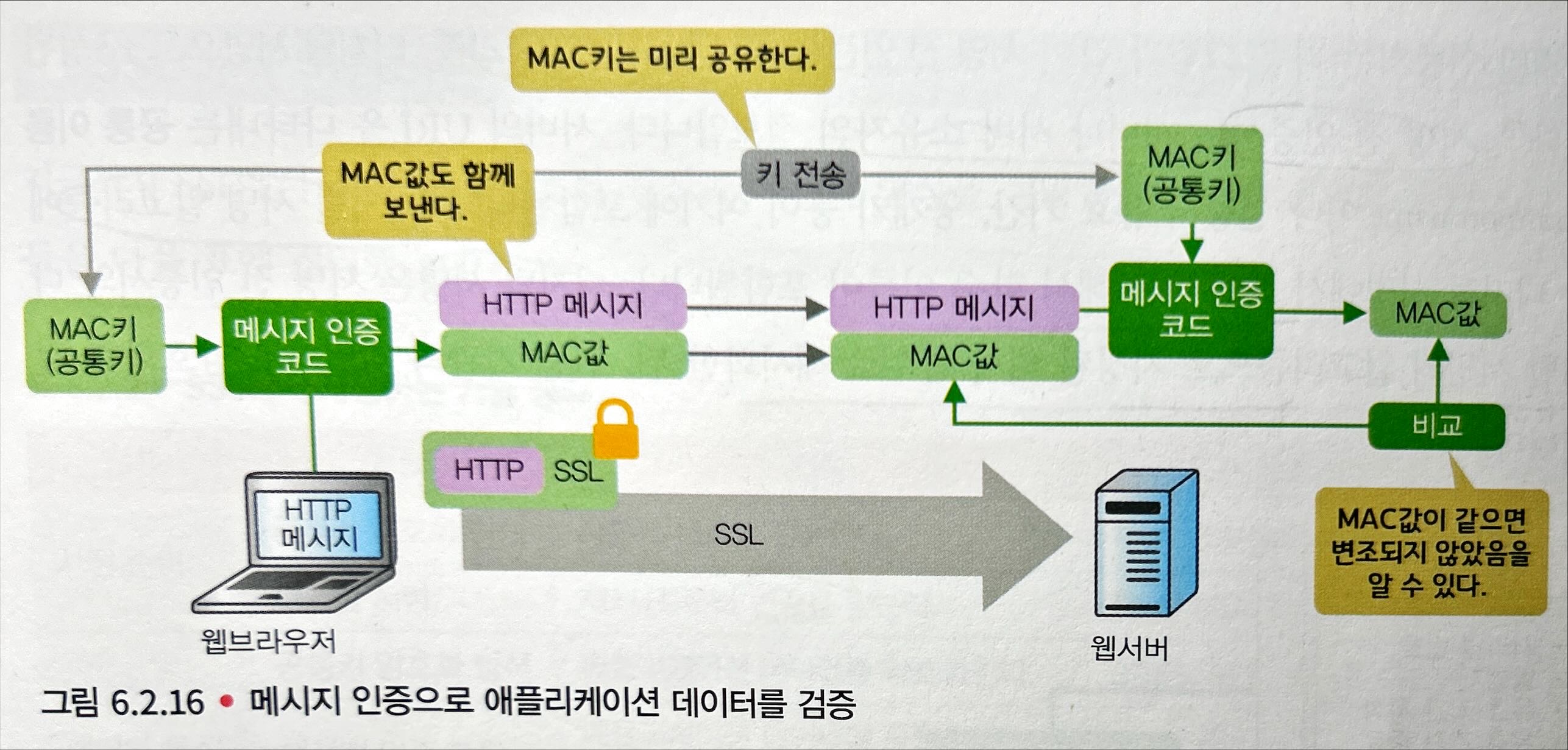
- 애플리케이션 데이터 검증
단방향 해시 함수가 아닌, 메시지 인증 코드(MAC)라는 기술을 사용한다. 이는 애플리케이션 데이터와 MAC키(공통키)를 섞어서 MAC값(해시값)을 계산하는 기술이다.
단방향 해시 함수에 공통키의 요소가 추가되므로 변조 감지뿐만 아니라 상대를 인증할 수도 있다.
MAC키는 공통키이므로 키 전송 문제가 존재한다.
- 디지털 인증서 검증
SSL에서는 디지털 인증서를 이용하여 자신과 상대를 증명한다. 이때, 제3자 인증 기관(CA)에 누가 누구인지를 디지털 서명의 형태로 승인 받으며, 이 디지털 서명에 해시화를 사용한다.
디지털 인증서의 구성
- 서명 전 인증서 (서버나 서버 소유자의 정보)
- 디지털 서명 알고리즘 (디지털 서명에서 사용하는 해시 함수 이름)
- 디지털 서명 (서명 전 인증서 & 디지털 서명 알고리즘으로 해시화 → 인증 기관의 비밀키로 암호화)
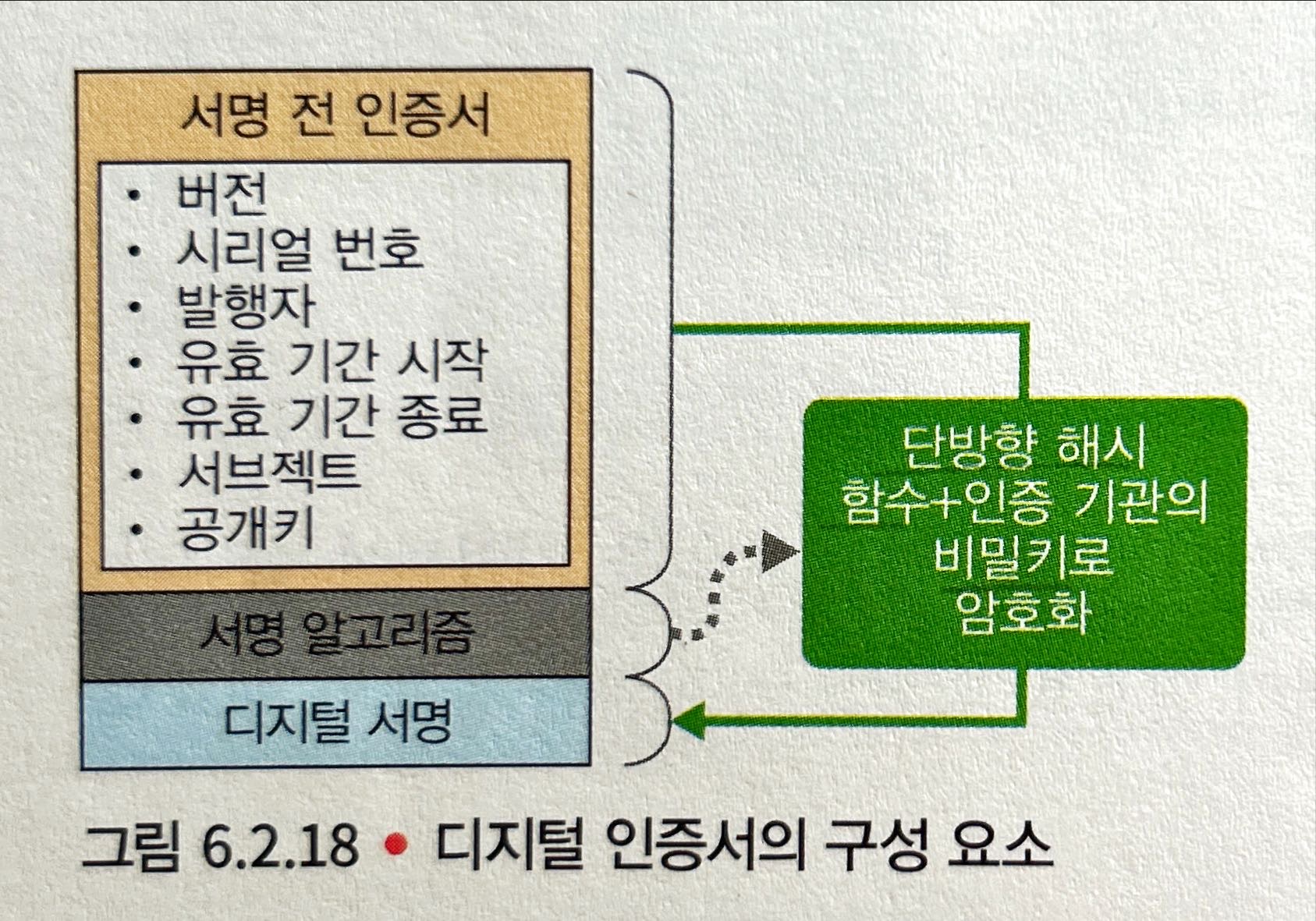
디지털 인증서를 받은 수신자는 디지털 서명을 인증 기관의 공개키(CA 인증서)로 복호화해서 서명 전 인증서의 해시값과 비교/검증한다. 이를 통해 인증서가 변조되었는지 여부, 즉 서버가 진짜인지 여부를 알 수 있다.
3-4. SSL 레코드 포맷
SSL을 통해 전달되는 메시지를 SSL 레코드라고 한다.
- SSL 헤더
- 콘텐츠 타입 (1바이트): 핸드셰이크 레코드, 암호 사양 변경 레코드, 얼럿 레코드, 애플리케이션 데이터 레코드의 4가지로 분류한다.
- 프로토콜 버전 (2바이트): 메이저 버전 / 마이너 버전으로 이루어진다.
SSL 페이로드 길이 (2바이트): SSL 페이로드의 길이를 바이트 단위로 정의한다.
TLS 1.2에서는 애플리케이션 데이터가 \(2^{14}\)(=16384) 바이트를 넘는다면 \(2^{14}\) 바이트로 분할하여 암호화한다.
- SSL 페이로드
3-5. SSL 접속에서 종료까지의 흐름
TLS 1.2에 대응하는 HTTPS 서버를 인터넷에 공개하는 흐름을 살펴보자.
[1] 서버 인증서 준비
- HTTPS 서버에서 비밀키를 만든다.
비밀키를 기반으로 CSR(Certificate Signing Request)을 만들어 인증 기관에 보낸다.
CSR은 서버 인증서를 얻기 위해 인증 기관에 제출하는 신청서와 같은 것으로, 서명 전 인증서의 정보를 암호화하여 만든다.
- 인증 기관이 신청자의 신원을 조회하고, 이를 통과하면 CSR을 해시화 & 인증 기관의 비밀키로 암호화해서 디지털 서명으로 만든다. 그리고 서버 인증서를 발행하고 요청자에게 송신한다.
인증 기관에서 받은 서버 인증서와 중간 인증서를 서버에 설치한다.
중간 인증서를 함께 설치함으로써 웹브라우저는 인증서의 계층에 올바르게 도달할 수 있다.
[2] SSL 핸드셰이크
서버 인증서를 설치하면 웹브라우저에서 SSL 접속을 받을 수 있다. 메시지를 암호화하기 전에, 암호화하기 위한 정보나 통신 상대를 확인하는 사전 준비가 필요한데 이를 SSL 핸드셰이크 단계라고 한다.
- TCP 3-way 핸드셰이크로 TCP 커넥션을 연다.
- 핸드셰이크 레코드를 이용하여 SSL 핸드셰이크 한다.
- 결정된 정보를 기반으로 메시지를 암호화 한다.
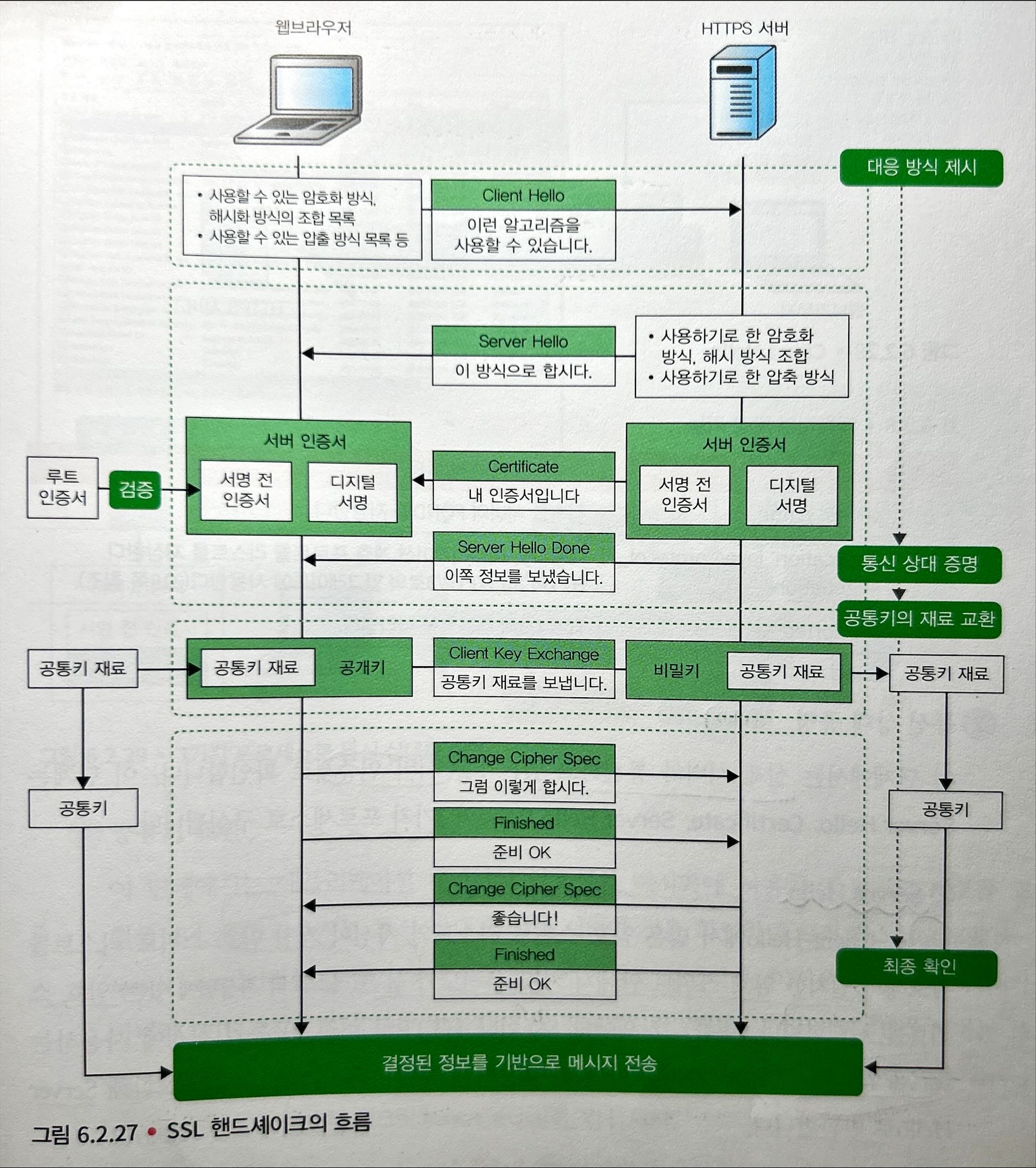
- [웹브라우저] 대응 방식 제시 (암호화 방식 & 해시 함수)
Client Hello를 사용해 웹브라우저가 사용할 수 있는 암호화 방식이나 단방향 해시 함수의 목록을 제시한다. 이를 암호 스위트라 한다.- 서버와 맞추어야 하는 파라미터(ex. SSL, HTTP 버전, 공통키 작성에 필요한
client random)도 전송한다.
- [서버] 통신 상대 증명: 서버 인증서를 통해 실제 서버와 통신하고 있는가를 확인한다.
Server Hello: 클라이언트로부터 받은 암호 스위트와 자신의 암호 스위트 간 일치하는 암호 스위트를 선택한다. 또한, 클라이언트와 맞추어야 하는 파라미터도 포함해Server Hello로 반환한다.Certificate: 자기 자신의 서버 인증서를 보내어 본인임을 증명한다.Server Hello Done: 정보를 모두 보냈음을 알린다. 웹브라우저는 받은 서버 인증서를 검증한다.웹브라우저는 루트 인증서로 복호화 → 해시값 비교를 통해 올바른 서버인지 확인한다.
서버 인증서, 중간 인증서, 루트 인증서에 관한 자료: 링크
[웹브라우저] 공통키 재료 교환: 애플리케이션 데이터의 암호화와 해시화에 사용할 공통키의 재료를 교환한다.
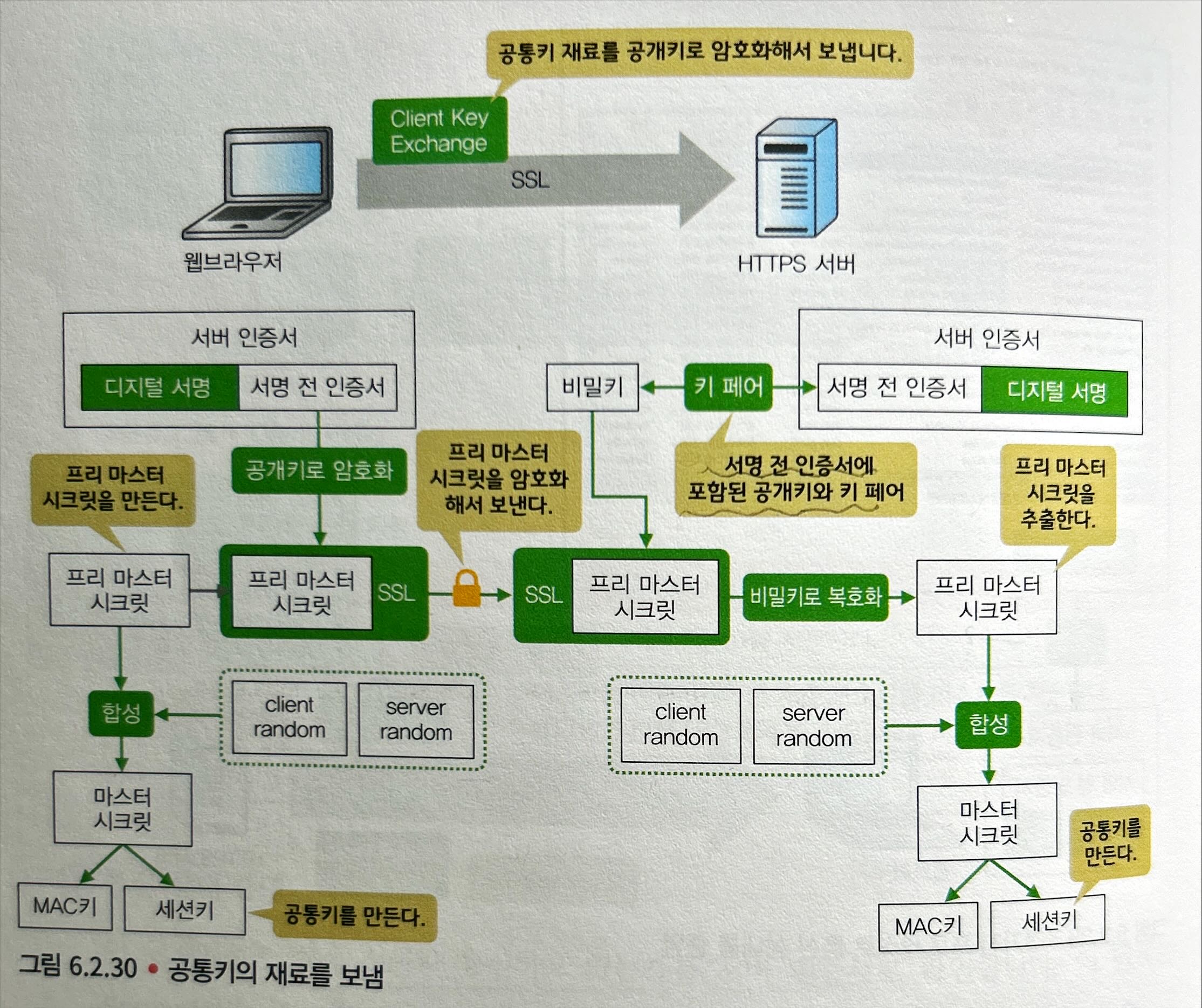
Client Key Exchange: 웹브라우저는 서버에게 프리 마스터 시크릿이라는 공통키 재료를 공개키로 암호화하여 서버로 보낸다.- 암호화에 사용하는 공개키는 서버 인증서의 서명 전 인증서에 포함되어 있다.
- 서버는 비밀키로 복호화해서 프리 마스터 시크릿을 추출한다.
- 웹브라우저와 HTTPS 서버는 프리 마스터 시크릿,
Client Hello로 얻은client random,Server Hello로 얻은server random을 섞어 마스터 시크릿을 만든다. - 마스터 시크릿을 이용해 다음과 같은 공통키들을 만든다.
- 암호화에 사용하는 세션키
- 해시화에 사용하는 MAC키
- 최종 확인
- 서로
Change Cipher Spec과Finished를 교환하고, 이제까지 결정한 사항들을 확인하고, SSL 핸드셰이크를 종료한다. - 이후에는 SSL 세션이 만들어지고, 애플리케이션 데이터 암호화 통신을 시작한다.
- 서로
[3] 암호화 통신
SSL 핸드셰이크가 끝나면 애플리케이션 데이터 암호화 통신을 시작한다.
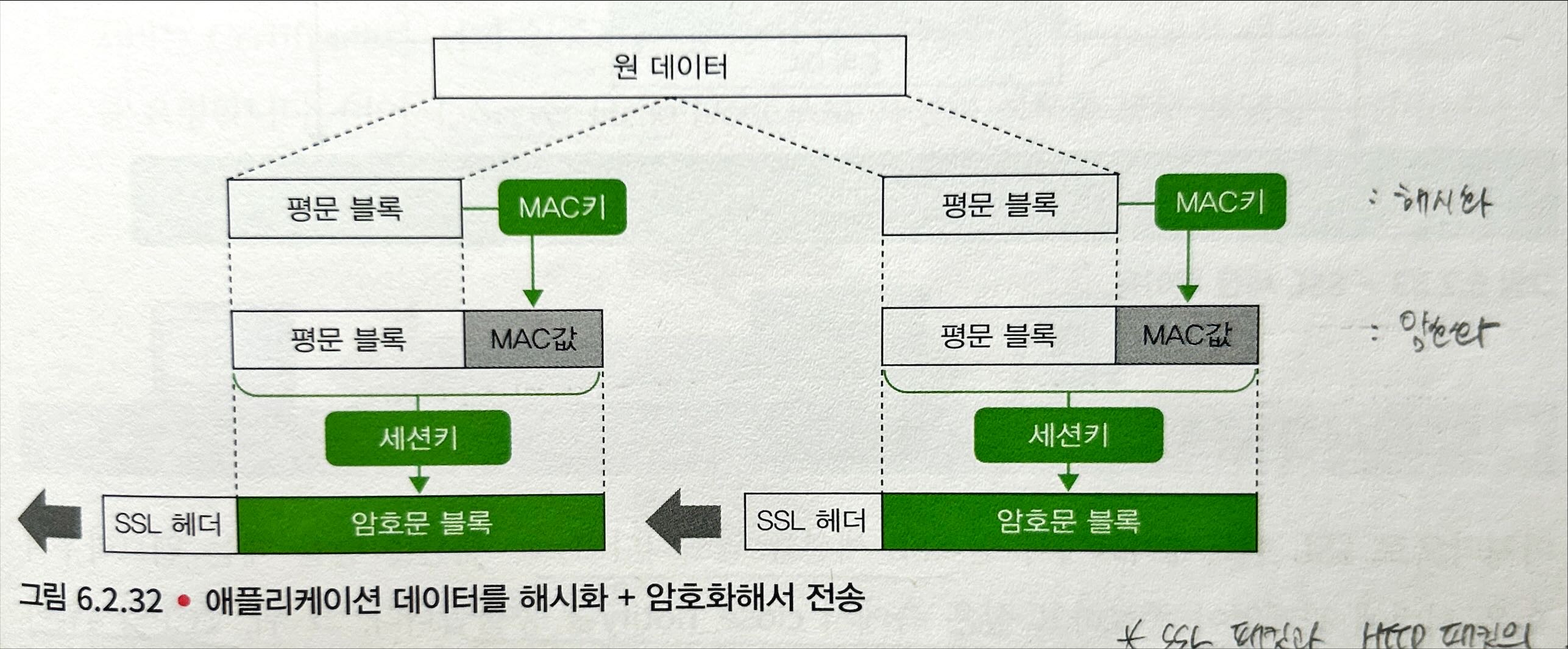
- 애플리케이션 데이터를 MAC키로 해시화하여 MAC값을 얻는다.
- 평문 블록 + MAC값을 세션키로 암호화해서, SSL 헤더를 붙여 애플리케이션 데이터 레코드로 전송한다.
[4] SSL 세션 재이용
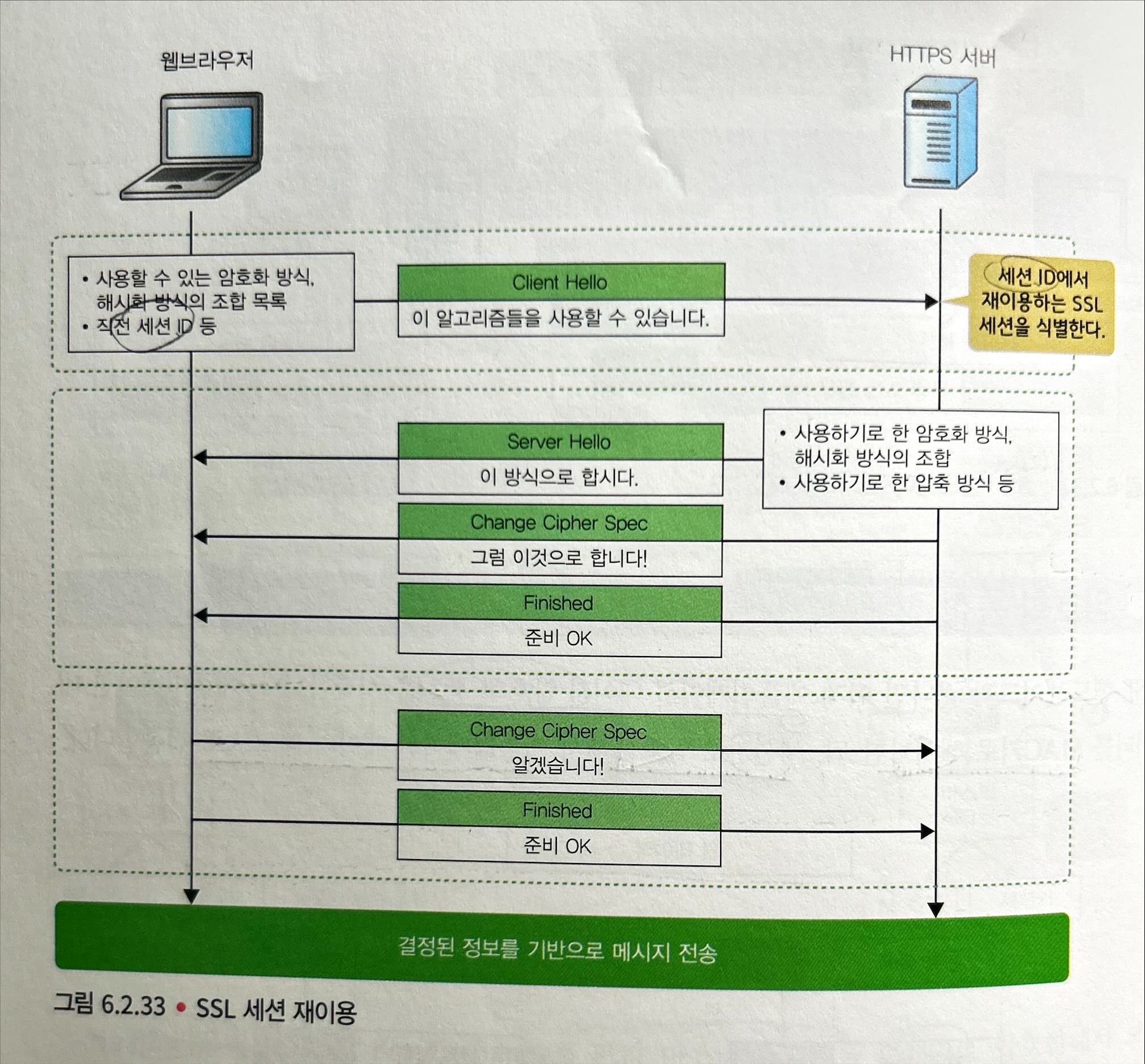
- SSL 핸드셰이크는 처리 시간이 오래 걸리므로, 최초의 SSL 핸드셰이크에서 생성한 세션 정보를 캐시해 재사용하는 기능을 제공한다.
Certificate나Client Key Exchange등 공통키를 생성하기 위해 필요한 처리를 생략할 수 있어 시간을 크게 줄일 수 있으며, 처리 부하도 줄일 수 있다.
[5] SSL 세션 종료
- SSL 핸드셰이크로 연 SSL 세션을 닫는다.
- 웹브라우저 / 서버에 관계없이 종료하고 싶은 측에서
close_notify를 송출한다. - TCP 4-way 핸드셰이크 후 TCP 커넥션을 종료한다.
3-6. 클라이언트 인증
3-5에서는 서버 인증서를 이용해서 서버를 인증하는 것만 다루었다. 그에 비해, 클라이언트 인증은 미리 웹브라우저에 설치한 클라이언트 인증서를 이용해 클라이언트를 인증한다. 클라이언트 인증의 SSL 핸드셰이크는 서버 인증의 SSL 핸드셰이크 + 클라이언트 인증서를 요청하거나 인증하는 프로세스로 이루어진다.
- [서버] 클라이언트 인증서 요청
Client Hello→Server Hello→Certificate를 통해 HTTPS 서버는 서버 인증서를 송신한다.- (➕)
Certificate Request로 클라이언트 인증서를 요청한다. Server Hello Done으로 자신의 정보를 모두 보냈음을 알린다.
- [웹브라우저] 클라이언트 인증서 전송
- (➕)
Certificate로 미리 설치된 클라이언트 인증서를 송신한다. - 합의한 클라이언트 인증서가 없다면
no_certificate를 보낸다.
- (➕)
- 이제까지의 해시값을 송부
- 웹브라우저는
Client Key Exchange로 프리 마스터 시크릿을 송신한다. - (➕) 계속해서
Certificate Verify로 이제까지의 교환(Client Hello~Client Key Exchange)을 해시화 & 비밀키로 암호화하여 디지털 서명으로 송신한다. - 서버는
Certificate안에 포함된 디지털 서명을 공개키를 이용하여 복호화하고, 스스로 계산한 해시값과 비교해 변조 여부를 확인한다. - 그 후에는 서버 인증과 마찬가지로 서로
Change Cipher Spec과Finished를 교환하고, 실제 애플리케이션 데이터의 암호화 통신을 진행한다.
- 웹브라우저는
3-7. SSL 오프로드
SSL 오프로드란 부하 분산 장치의 옵션 기능의 하나로, 서버에서 수행하던 SSL 처리를 부하 분산 장치에서 수행하는 기능이다. 클라이언트는 항상 HTTPS로 리퀘스트하며, 이 리퀘스트를 받은 부하 분산 장치는 자신이 SSL 처리를 하고, 부하 분산 대상 서버에는 HTTP로 전달한다.
서버가 SSL의 처리를 하지 않아도 되기 때문에 처리 부하가 극적으로 감소하며, 시스템 레벨에서 높은 수준으로 부하 분산할 수 있게 된다.
4. DNS (Domain Name System)
DNS는 IP 주소와 도메인 이름을 상호 교환하는 프로토콜이다.
인터넷에서는 단말을 식별하기 위해 IP 주소를 사용하는데, 이는 숫자의 나열이므로 DNS를 통해 IP 주소에 도메인 이름을 붙여 사람이 이해하기 쉬운 형태로 통신할 수 있도록 한다.
ex) 글로벌 IPv4 주소
172.217.175.4↔ 도메인 이름www.google.com
실제 웹브라우저에서 구글 웹사이트에 액세스할 때는,
- 먼저 웹브라우저가 DNS 서버에게 도메인 이름
www.google.com에 할당되어 있는 IP 주소를 문의하고, - 응답받은 IP 주소에 HTTPS로 액세스한다.
4-1. 도메인 이름
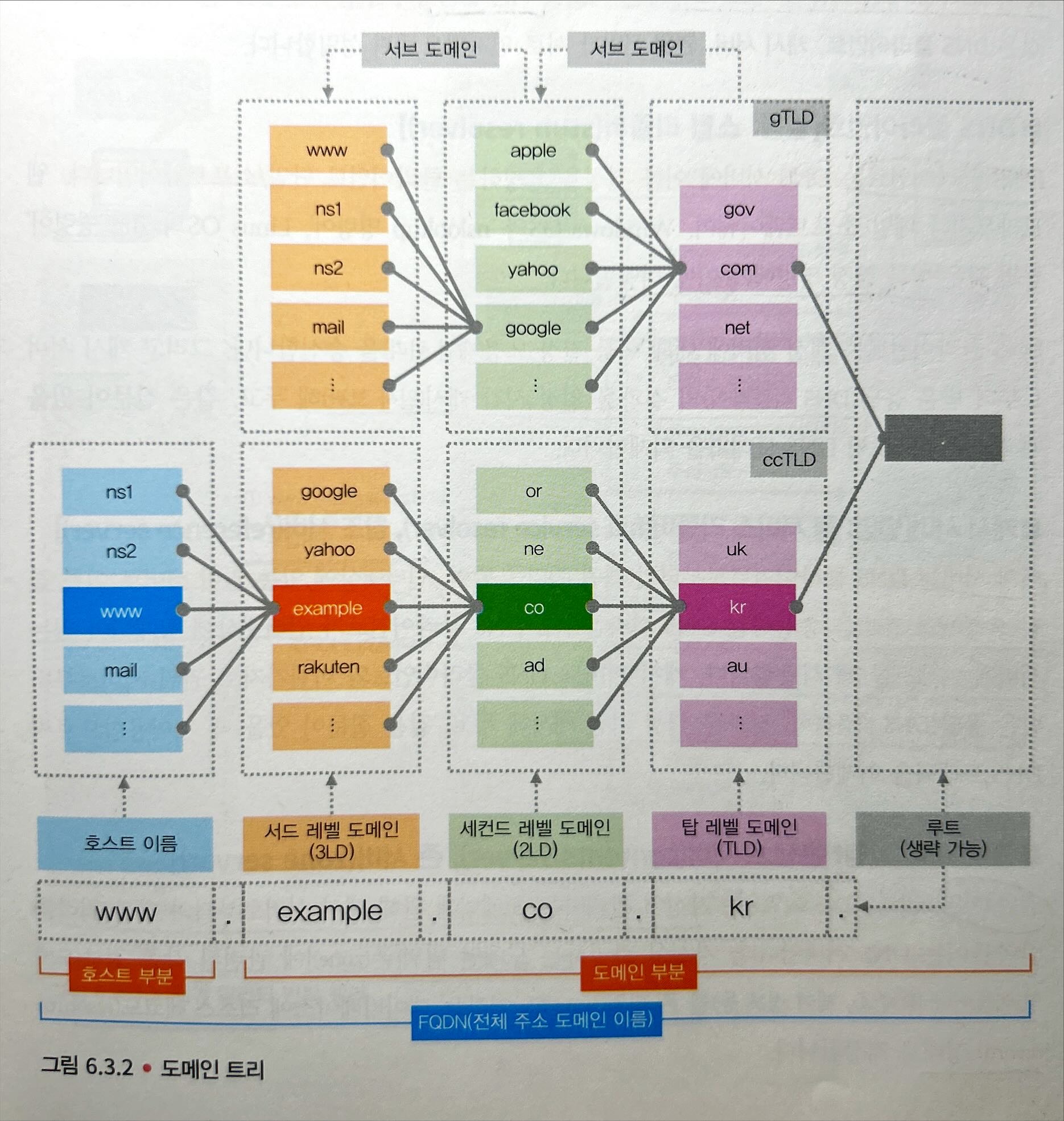
도메인 이름이란, www.example.com과 같이 .으로 구분된 문자열로 구성되며, FQDN(Fully Qualified Domain Name)이라 불린다. 이는 다음의 두 부분으로 나뉜다.
- 호스트 부분: FQDN의 가장 왼쪽에 있는 라벨로, 컴퓨터 그 자체를 나타낸다. (
www) 도메인 부분: 오른쪽부터 순서대로 루트, 탑 레벨 도메인(TLD), 세컨드 레벨 도메인(2LD), 서드 레벨 도메인(3LD)…으로 구성되어 있다.
맨 오른쪽 끝의 루트는
.으로 나타내며, 일반적으로 생략한다.
4-2. 이름 결정 (Name Resolution)
IP 주소와 도메인 이름을 서로 교환하는 처리를 이름 결정이라 한다. DNS를 이용한 이름 결정은 DNS 클라이언트, 캐시 서버, 권위 서버가 서로 연계함으로써 성립한다.
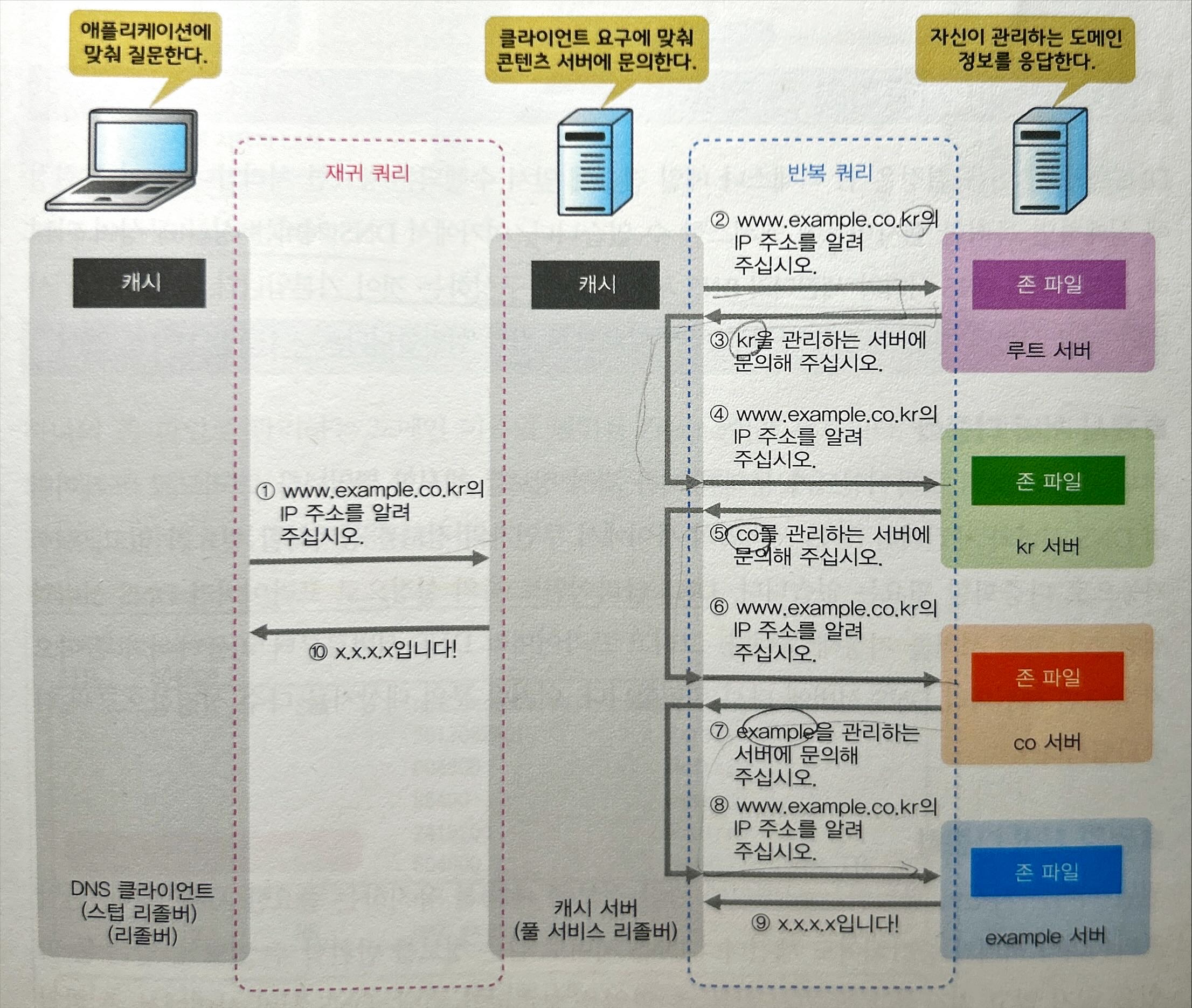
- DNS 클라이언트 (stub resolver)
- DNS 서버에 이름 결정을 요청하는 클라이언트 단말/소프트웨어이다.
캐시 서버에 대해 이름 결정 요청(재귀 쿼리)을 송신한다. 그리고 캐시 서버로부터 받은 응답의 결과를 일정 시간 캐시해두고, 같은 질문이 있을 때 재이용함으로써 DNS 트래픽을 억제한다.
재귀 쿼리는 일종의 위임이다. (ref: 자료)
- 캐시 서버 (full service resolver, reference server)
- DNS 클라이언트로부터의 재귀 쿼리를 받아, 인터넷상에 있는 권위 서버로 이름 결정 요청을 반복 쿼리로 송신하는 DNS 서버이다.
- DNS 클라이언트가 인터넷상에 공개되어 있는 서버에 액세스할 때 사용한다.
- 캐시 서버 또한 권위 서버로부터 받은 응답 결과를 일정 기간 캐시해두고, 같은 질문이 있을 때 재이용함으로써 DNS 트래픽을 억제한다.
- 권위 서버 (contents server, zone server)
자신이 관리하는 도메인에 관해 캐시 서버로부터의 반복 쿼리를 받아들이는 DNS 서버이다.
자신이 관리하는 도메인 범위를 존(zone)이라 한다.
인터넷 상의 권위 서버는 루트 서버라 부르는 부모격의 서버를 꼭짓점으로 한 트리 형태의 계층 구조로 되어 있다.
루트 서버 수는 13개 서버 주소로 제한되어 있다. (ref: 자료)
루트 서버 → 탑 레벨 도메인의 권위 서버 → 세컨드 레벨 도메인의 권위 서버 → … 의 순서로 존의 관리를 위임한다.
DNS 클라이언트로부터 재귀 쿼리를 받은 캐시 서버는, 받은 도메인 이름의 라벨로부터 순서대로 검색해서 그 존을 관리하는 권위 서버로 점점 반복 쿼리를 실행해간다. 마지막까지 도달하면 그 권위 서버로부터 도메인 이름에 대응하는 IP 주소를 받는다.
용어가 헷갈릴 수 있다!
- DNS 서버: 캐시 서버를 가리키는 경우도, 권위 서버를 가리키는 경우도, 양쪽 모두를 가리키는 경우도 있다.
- 네임 서버(name server): 권위 서버를 가리키는 경우도, 캐시 서버와 권위 서버를 모두 가리키는 경우도 있다.
DNS 서버의 IP 주소는?
DNS 서버의 IP 주소는 TCP/IP 설정 항목 중의 하나이므로 컴퓨터에 미리 설정되어 있다.
DHCP 시에 IP 주소, 서브넷 마스크, DNS IP 주소, 기본 게이트웨이 IP 주소를 학습한다.
- 통신사(ISP, Internet Service Provider) 별로 DNS 서버 IP 주소가 정해져 있다.
ref: https://blog.naver.com/lyshyn/221301323596

4-3. DNS 메시지 포맷
- 이름 결정은 웹 액세스나 메일 전송 등 애플리케이션 통신에 앞서 수행된다. 따라서 이름 결정은 처리 속도를 위해 L4 프로토콜로 UDP(포트 번호
53)를 사용해 처리 속도를 우선시 한다. - DNS 메시지는 header / question / answer / authority / additional 섹션으로 구성된다.
DNS가 UDP를 사용하는 이유
- 속도가 빠르기 때문이다.
- DNS는 신뢰성보다 속도가 더 중요한 서비스이다. UDP는 비연결성 프로토콜이므로 overhead가 작아 TCP에 비해 속도가 빠르다.
- 보통 UDP로는 512byte를 넘어가지 않는 데이터를 전송하는데, DNS가 전송하는 데이터 패킷 사이즈 또한 매우 작다. 전달하는 패킷 사이즈가 작기 때문에 재전송이 쉬우므로 신뢰성을 따로 보장하지 않아도 된다.
- 연결 상태를 유지할 필요가 없기 때문이다.
- UDP를 사용하면 연결 관련 정보를 기록/유지할 필요가 없다. 따라서 DNS 서버는 TCP보다 많은 클라이언트를 수용할 수 있다.
4-4. DNS를 이용한 기능
DNS는 HTTP 패킷, HTTPS 패킷, 메일 패킷 등의 행선지를 결정하는 중요한 역할을 한다. 이를 이용한 몇 가지 확장 기술에는 여러 가지가 있다.
- DNS 라운드 로빈
- DNS를 이용한 부하 분산 기술이다.
- 권위 서버에서 하나의 도메인(FQDN)에 여러 IP 주소를 등록해주면, DNS 쿼리(반복 쿼리)를 받을 때마다 순서대로 다른 IP 주소를 반환한다. 따라서 클라이언트는 같은 도메인 이름으로 다른 서버에 접속할 수 있게 되어 서버 부하를 분산할 수 있다.
- 손쉽게 서버의 부하 분산을 구현할 수 있으나, 서버의 상태나 애플리케이션의 움직임에 관계없이 순서대로 IP 주소를 반환하므로 장애에 대한 내성이나 유연성은 부족하다.
- CDN(Content Delivery Network)
- 웹 콘텐츠를 대량 송신하기 위해 최적화된 인터넷상 서버 네트워크이다.
- 오리지널 컨텐츠를 가진 오리진 서버와 그 캐시를 가진 에지 서버로 구성된다.
- CDN은 사용자를 물리적으로 더 가까운 에지 서버로 유도하기 위해 DNS를 사용한다.
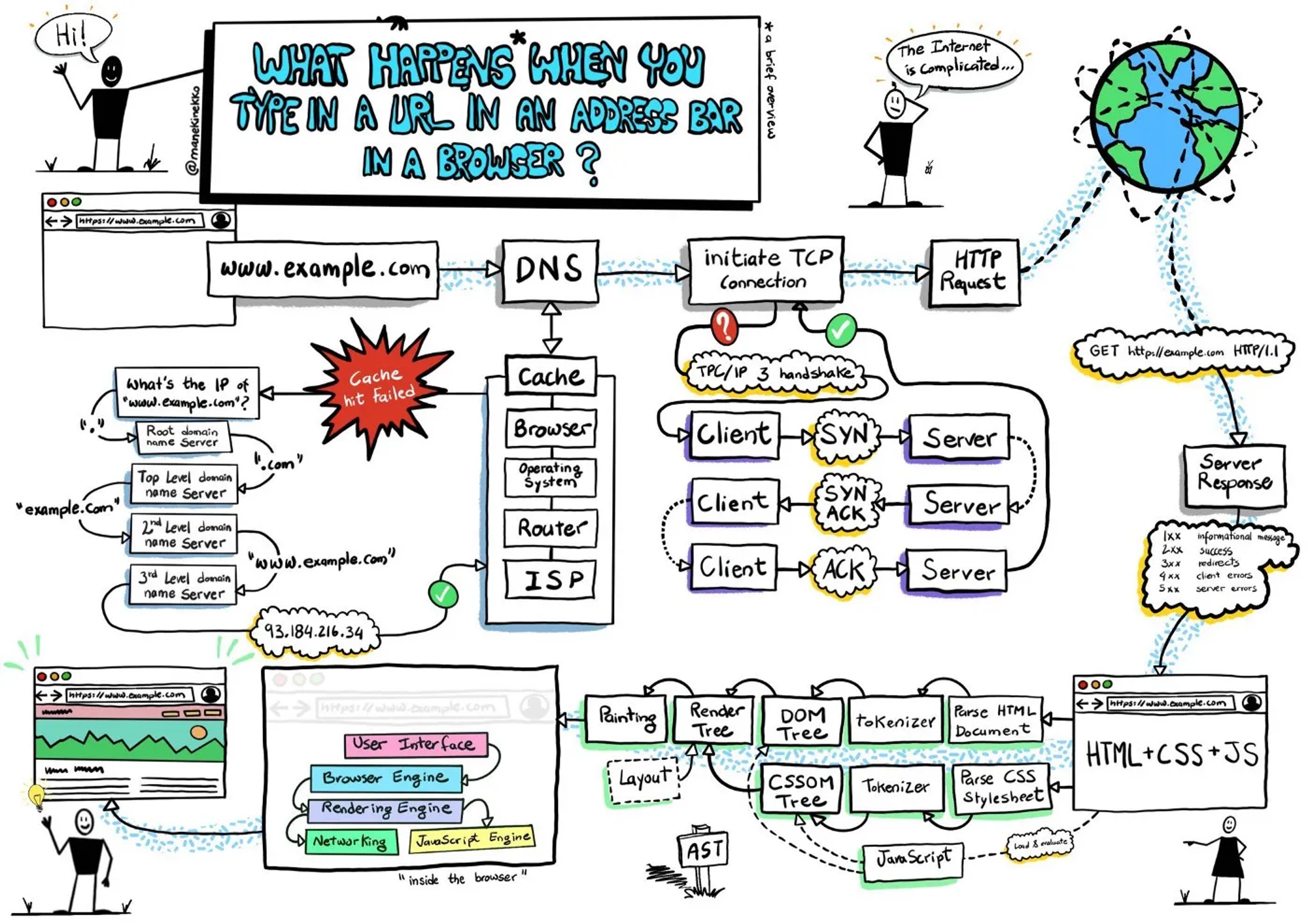
브라우저에 URL을 입력하고 접속할 때 (간략 흐름)
DNS lookup — 웹사이트의 IP 주소를 찾는다.
이 과정에서 ARP 수행 (for UDP)
- 만약 DNS 서버가 같은 서브넷에 존재한다면 이 네트워크 라이브러리는 DNS 서버에 대해 ARP 프로세스를 거친다.
- 만약 DNS 서버가 다른 서브넷에 존재한다면, 네트워크 라이브러리는 기본 게이트웨이 IP에 대해 ARP 프로세스를 거친다.
- TCP 3-way handshake — TCP 커넥션을 시작한다.
- TLS handshake — 웹사이트가 HTTPS라면, SSL/TLS 세션을 확립한다.
- HTTP request를 작성하고 보낸다. (
GET메서드)- 서버로부터 HTML, CSS, JavaScript 파일들을 받는다.
ref:
References
- “그림으로 공부하는 TCP/IP 구조(미야타 히로시 저)”, Ch6. 애플리케이션 계층
- https://brunch.co.kr/@sangjinkang/47
- https://blog.naver.com/lyshyn/221301323596
- https://steady-coding.tistory.com/523
- https://kingofbackend.tistory.com/198