[Python] GIL(Global Interpreter Lock, 전역 인터프리터 락)
본 포스팅의 내용은 파이썬의 공식 구현체인 CPython을 기준으로 작성되었음을 밝힙니다.
“파이썬이 왜 느린가?”를 논할 때 항상 등장하는 단어가 있다. 그것은 바로 흔히 GIL이라고 부르는 전역 인터프리터 락(Global Interpreter Lock)이다. 이러한 GIL은 무엇이며 어떻게 동작하는지, 그리고 왜 파이썬에 도입되었고 이로 인해 발생하는 현상에는 어떤 것이 있는지 알아보자.
1. GIL(Global Interpreter Lock)
GIL(Global Interpreter Lock)이란 파이썬 객체에 대한 접근을 보호하는 일종의 뮤텍스(mutex)로, 여러 쓰레드가 파이썬 바이트 코드(byte code)를 동시에 실행하지 못하도록 한다. 이를 통해 thread-safe 하지 않은 CPython 메모리 관리에서 thread-safety를 보장한다.
이렇게만 설명하면 GIL에 대해 잘 와닿지 않을 것이다. 자세히 살펴보기 전, 관련된 용어를 먼저 간단하게 정리해보자.
파이썬 인터프리터의 실행
파이썬 인터프리터 인스턴스는 하나의 프로세스이며, 이러한 파이썬 인터프리터는 사용자 프로그램과 메모리 GC(가비지 컬렉터)를 실행하기 위해 싱글 쓰레드를 사용한다.
쓰레드 안전(Thread-Safe)
쓰레드 안전(thread-safe)하다는 것은 멀티 쓰레드 프로그래밍에서 어떤 공유 자원(ex. 함수, 변수, 객체 등)에 여러 쓰레드가 동시에 접근하더라도 각 쓰레드에서의 수행 결과가 올바르게 나오는 것을 의미한다.
CPython에서 파이썬 쓰레드들은 동일한 메모리를 공유하기 때문에, 여러 쓰레드가 동시에 실행된다면 공유 자원에 접근하는 순서가 스케줄링 알고리즘에 의존하게 되어 그 결과를 예측할 수 없게 된다. 즉, CPython의 메모리 관리는 thread-safe 하지 않다.
이처럼 경쟁 상태(race condition)에 있는 작업들이 안전하게 처리되도록 하려면 동기화(synchronization)가 필요하다.
뮤텍스(Mutex)
여러 개의 작업(프로세스, 쓰레드)이 어떤 공유 자원에 접근하는 경쟁 상태(race condition)는 동기화(synchronization)를 통해 해결할 수 있다. 이러한 공유 자원에 접근하는 코드, 즉 경쟁 상태가 발생할 수 있는 영역을 임계 구역(critical section)이라 하며, 해당 작업이 공유 자원에 대한 배타적인 사용을 보장 받기 위해서는 임계 구역에 대한 상호 배제(mutual exclusion)가 필요하다.
상호 배제란, 하나의 작업이 공유 자원에 접근하고 있을 때 다른 작업은 접근하지 못하도록 제어하는 기법이다. 즉, 하나의 작업이 임계 구역에 들어갔을 때 다른 작업은 들어갈 수 없도록 제한하는 것으로, 프로세스/쓰레드 간 동기화를 구현하는 방법 중 하나이다.
뮤텍스는 상호 배제를 달성하기 위한 기법 중 하나로 mutual exclusion의 약자이다. 뮤텍스의 동작을 실생활에 빗대어 설명하면 다음과 같다.
A가 화장실을 이용할 때, 다른 사람이 들어오지 못하도록 열쇠를 사용하여 문을 잠갔다고 생각해보자. 이렇게 되면 B는 해당 열쇠가 반납될 때까지 화장실을 이용할 수 없으므로 대기해야하며, 추후 A가 화장실을 나오며 열쇠를 넘겨주어야 화장실을 이용할 수 있다. 이때, 화장실은 임계 구역, 열쇠는 뮤텍스가 된다.
즉, 뮤텍스는 (1) 잠김과 (2) 잠기지 않음의 두 가지 상태만 가질 수 있으며, 잠긴 상태일 때는 다른 작업이 해당 임계 구역에 접근할 수 없다.
다시 한 번 GIL에 대해 한 마디로 정리하면 다음과 같다.
GIL(Global Interpreter Lock)
GIL은 하나의 프로세스 내에서 파이썬 인터프리터가 한 시점에 단 하나의 쓰레드에 의해서만 실행될 수 있도록 보장하는 일종의 뮤텍스(mutex)이며, 이는 CPython의 메모리 관리가 thread-safe 하지 않기 때문에 경쟁 상태(race condition)를 방지하기 위해서 도입되었다.
1-1. GIL로 인해 파이썬에서 멀티 쓰레딩 자체가 불가능한가?
아니다. 본래 멀티 코어 CPU 환경에서는 멀티 쓰레딩 시 쓰레드들이 병렬 실행될 수 있으나, 파이썬에서는 그러한 병렬 실행이 불가능하고 다음의 그림과 같이 GIL을 릴리즈/획득하면서 한 시점에 단 하나의 쓰레드만 실행된다는 점이 다를 뿐이다.
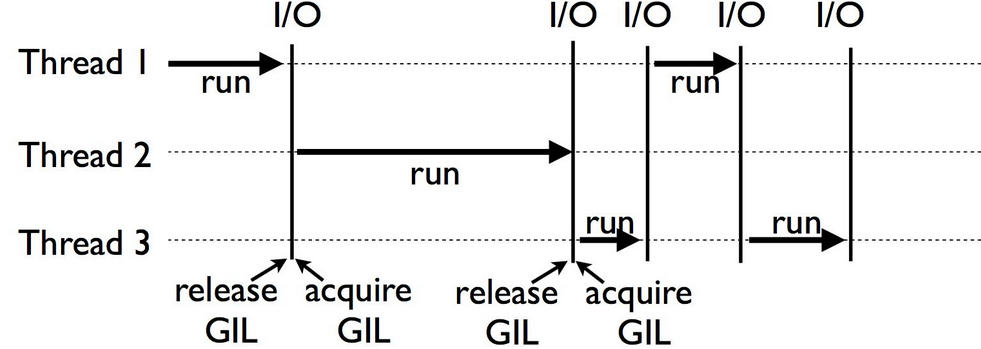 ref: https://www.datacamp.com/tutorial/python-global-interpreter-lock
ref: https://www.datacamp.com/tutorial/python-global-interpreter-lock
1-2. 멀티 쓰레딩 환경에서 GIL이 릴리즈(Release) 되는 시점
여러 쓰레드가 GIL을 릴리즈/획득하며 한 시점에 단 하나의 쓰레드만 실행된다면, 과연 언제 GIL이 릴리즈 되는 것일까?
우선, 실행되고 있던 쓰레드가 blocking operation을 수행한다면 GIL을 릴리즈하게 되며, 다른 쓰레드가 GIL을 획득하게 된다. 대표적인 예로는 디스크 I/O, 네트워크 I/O, 사용자로부터 입력값을 기다리는 I/O 연산이 있으며, 그 외에도 time.sleep()과 같이 시스템 콜을 호출하는 연산들이 있다.
I/O 연산도 low-level에서는 시스템 콜을 호출한다!
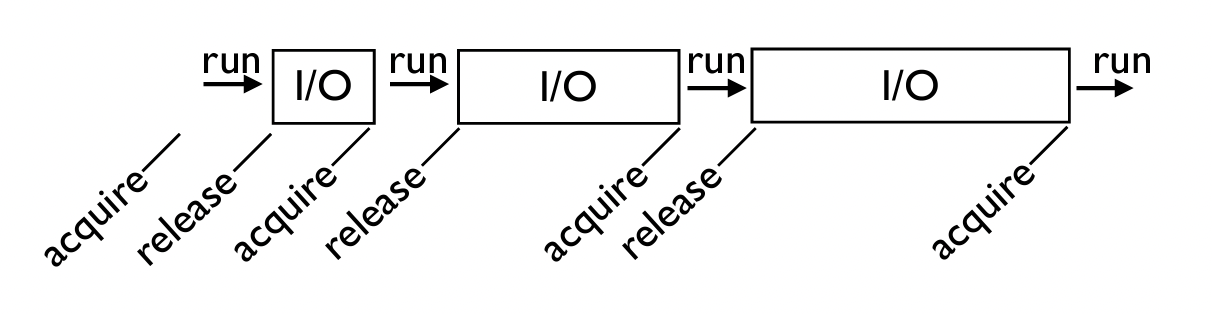 ref: http://www.dabeaz.com/python/GIL.pdf
ref: http://www.dabeaz.com/python/GIL.pdf
추가로, 어떤 쓰레드가 GIL을 독점하여 다른 쓰레드들이 실행되지 않는 starvation 현상을 방지하기 위해, 파이썬 인터프리터는 디폴트로 현재의 쓰레드를 5ms마다 중지(파이썬 3 기준)하여 GIL을 릴리즈한다. 하지만 프로그래머는 이러한 점에 의존해서는 안 된다.
이처럼 GIL이 릴리즈 되는 시점에 여러 쓰레드가 GIL을 기다리고 있다면 OS 스케줄러가 그 중 하나를 선택하게 되며, 해당 쓰레드가 GIL을 획득하게 된다.
2. 파이썬에 GIL이 도입된 이유
파이썬의 공식 구현체 CPython에 GIL이 필요한 이유는 무엇일까?
파이썬에서는 모든 것이 객체이며, 이러한 객체들이 가지고 있는 메모리를 관리하기 위해 참조 카운팅(reference counting) 기반 가비지 컬렉션(garbage collection, GC)을 사용한다. 즉, 파이썬에서 모든 객체는 자신을 가리키는 참조 횟수(reference count)를 저장하고 있으며, 파이썬의 GC는 그 값이 0에 도달하면 해당 객체가 가진 메모리를 회수하게 된다.
이처럼 파이썬의 GC가 참조 횟수 기반이므로, 멀티 쓰레딩 환경에서 여러 쓰레드가 동일한 객체를 사용한다면 객체의 참조 횟수 변수에 동시에 접근할 때 경쟁 상태가 발생하게 된다. 이로 인해 최악의 경우에는 메모리 누수(memory leak)가 발생하거나, 회수 되어서는 안 될 메모리를 회수하게 될 수도 있기 때문에 모든 객체에 대해 락(lock)을 추가하여 thread-safety를 보장해야 한다.
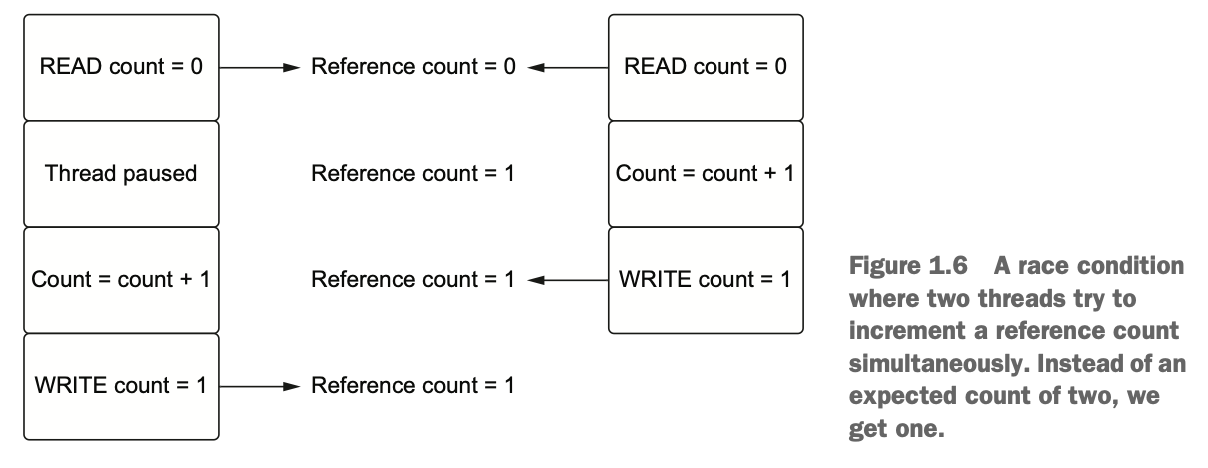 ref: “Python Concurrency with Asyncio”
ref: “Python Concurrency with Asyncio”
하지만 이렇게 락(lock)을 추가하는 것에는 다음과 같은 문제점들이 있다.
- 데드락(deadlock)이 발생할 수 있다.
- 반복적인 락 획득/릴리즈 과정으로 인해 성능이 저하될 수 있다.
- 모든 객체에 락을 추가하는 것을 프로그래머가 직접 수행할 경우, 굉장히 비효율적이며 실수가 발생할 수 있다.
따라서 CPython의 메모리 관리는 thread-safe 하지 않기 때문에, 멀티 쓰레딩 환경에서 객체의 참조 횟수에 대해 발생할 수 있는 경쟁 상태 자체를 방지하기 위해서 GIL을 도입한 것이다.
한 순간에 단 하나의 쓰레드만 파이썬 인터프리터를 실행할 수 있도록 제한하면 애초에 한 쓰레드만 공유 자원에 접근이 가능하다. 그러나 파이썬 3 기준으로는 5ms마다 GIL가 릴리즈되기 때문에, OS 스케줄링에 따라 경쟁 상태가 발생할 수 있다.
2-1. [🧩 조각 지식] 싱글 코어(Single-Core) vs. 멀티 코어(Multi-Core)
우선, CPU와 코어의 관계에 대해 간단히 알아보면 다음과 같다.
- CPU(central processing unit, 중앙 처리 장치): 컴퓨터 시스템에서 모든 산술 및 논리 연산을 수행하는 핵심 장치
- 기억 / 연산 / 제어라는 기본 동작을 수행한다.
명령을 수행하기 위해 다음의 단계를 따른다.
fetch → decode → execute
- 코어(core): CPU의 핵심 구성 요소로, 프로그램의 명령을 읽고 수행하는 처리 장치
- 이전에는 CPU 한 개당 코어가 하나 존재하는 형태인 싱글 코어(single-core) CPU를 사용했으나, 2005년에 CPU 한 개당 코어가 n개 존재하는 형태인 멀티 코어(multi-core) CPU가 처음 등장하였다.
본래 CPU는 한 번에 하나의 작업(= 프로세스 혹은 쓰레드)을 처리할 수 있다고 알려져 있으나, 사실 이는 싱글 코어 CPU(더 자세히 말하면, 단일 CPU이며 하이퍼 쓰레딩(hyper-threading)이 지원되지 않는 경우)일 때에 해당한다. 싱글 코어와 멀티 코어의 멀티 태스킹 방법을 비교해보면 다음과 같다.
싱글 코어(single-core): 한 번에 단 하나의 작업만을 처리할 수 있으며, OS 수준에서 시분할 기법(time sharing)을 통해 여러 작업 간에 빠르게 전환하며 실행함으로써 마치 동시에 여러 작업이 수행되는 것처럼 보이게 한다. (실제로는 동시에 실행되는 것이 X)
멀티 코어(multi-core): 여러 작업(멀티 프로세스/쓰레드)을 각 코어에 분배하여 병렬 처리(parallel execution)가 가능하기 때문에 실제로 동시에 여러 작업을 처리할 수 있으나, 개발자가 프로그램 구현 시 직접 병렬 프로그래밍 관련 작업을 해주어야 한다.
즉, 정리하면 다음과 같다. (하이퍼 쓰레딩이 적용되지 않은, 단일 CPU 환경 가정)
- 싱글 코어 CPU에서의 멀티 태스킹은 한 시점에 여러 작업이 동시에 수행되는 것처럼 보이지만 실제로는 여러 작업이 빠르게 번갈아가며 실행되는 것이다. 이를 시분할 기법이라고 한다.
- 멀티 코어 CPU 환경일 때 비로소 한 시점에 여러 작업이 동시에 수행되는 병렬 처리가 가능하다.
2-2. 파이썬이 GIL을 채택한 이유
멀티 쓰레딩 환경에서 제약이 생기는 데도 불구하고 GIL을 채택한 이유는 무엇일까?
- 파이썬에 필요한 많은 확장 기능들이 C로 쓰여져 있었으며 thread-safe 메모리 관리를 필요로 했다. GIL은 하나의 락(lock)만 관리하면 되므로 간단하고 쉽게 적용 가능한 방법이었다.
- 현재처럼 멀티 코어 CPU가 당연한 환경에서는 하나의 쓰레드가 자원을 독점하는 형태가 제한적으로 느껴지지만, 당시에는 싱글 코어 CPU 환경이었으므로 충분히 타당한 설계였다.
3. 파이썬의 멀티 쓰레딩은 항상 느린가?
지금까지의 내용을 종합해보면 파이썬을 이용한 멀티 쓰레딩은 성능 향상에 큰 도움이 되지 않을 것으로 예상된다. 과연 항상 그럴까?
3-1. [🧩 조각 지식] CPU-Bound vs. I/O-Bound
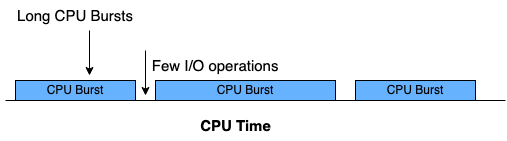
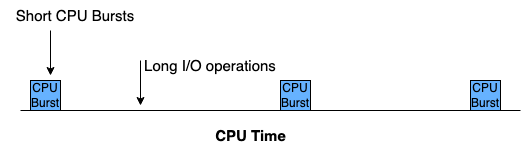
CPU burst: CPU를 직접 가지고 명령을 수행하는 일련의 단계
CPU-bound 작업: I/O 작업을 거의 수행하지 않아 CPU burst가 길게 나타나는 작업
I/O-bound 작업: I/O 작업이 길거나 빈번하여 CPU burst가 짧게 나타나는 작업
3-2. CPU-Bound 작업의 경우, 멀티 쓰레딩이 더 느릴 수 있다
실험 환경: MacBook Pro (2021), Apple M1 Pro chip, 8-core CPU
다음과 같이 CPU-bound를 simulate 하는 작업인 work_cpu를 2회 수행하는 실험을 해보자. 두 작업을 [1] 싱글 쓰레드 환경에서 순차적으로 수행했을 때와 [2] 멀티 쓰레드(2개) 환경에서 각 쓰레드에 하나씩 분배하여 수행했을 때의 소요 시간을 측정해보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import random
from threading import Thread
import time
def work_cpu():
min([random.random() * 100 for _ in range(100_000_000)])
if __name__ == "__main__":
# [1] Single-Thread (Sequential)
s = time.time()
work_cpu()
work_cpu()
e = time.time()
print(f"[Single-Thread] {e - s:5f}s")
# [2] Multi-Thread
s = time.time()
t1 = Thread(target=work_cpu)
t2 = Thread(target=work_cpu)
t1.start()
t2.start()
t1.join()
t2.join()
e = time.time()
print(f"[Multi-Thread] {e - s:5f}s")
측정 결과, 오히려 싱글 쓰레드 환경에서 작업 수행에 소요된 시간이 짧다는 것을 알 수 있다.
1
2
[Single-Thread] 22.589264s
[Multi-Thread] 28.020673s
그렇다면, 왜 CPU-Bound 작업은 멀티 쓰레딩으로 처리하면 느려지는 것일까? 다음과 같은 이유 때문이다.
- 파이썬에서는 멀티 쓰레딩을 적용하여도 GIL 때문에 한 시점에 하나의 쓰레드만 파이썬 인터프리터를 실행한다.
- 멀티 쓰레딩을 사용하면 오히려 쓰레드 생성 및 문맥 교환(context switch) 비용이 추가로 발생하게 된다.
CPU-bound 작업을 다룰 때에는 순차적 & 싱글 쓰레드 코드가 더 간단하고 빠르다!
3-3. I/O-Bound 작업의 경우, 멀티 쓰레딩의 효과를 얻을 수 있다
다음과 같이 time.sleep()을 호출하여 I/O-bound를 simulate 하는 작업인 work_io를 2회 수행하는 실험을 해보자. 이전의 CPU-bound 실험에서 I/O-bound 작업으로 변경하였다는 점만 다르다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import random
from threading import Thread
import time
def work_io():
time.sleep(2)
min([random.random() * 100 for _ in range(50_000_000)])
time.sleep(2)
min([random.random() * 100 for _ in range(50_000_000)])
time.sleep(2)
min([random.random() * 100 for _ in range(50_000_000)])
if __name__ == "__main__":
# [1] Single-Thread (Sequential)
s = time.time()
work_io()
work_io()
e = time.time()
print(f"[Single-Thread] {e - s:5f}s")
# [2] Multi-Thread
s = time.time()
t1 = Thread(target=work_io)
t2 = Thread(target=work_io)
t1.start()
t2.start()
t1.join()
t2.join()
e = time.time()
print(f"[Multi-Thread] {e - s:5f}s")
측정 결과, CPU-bound 실험과는 다르게 멀티 쓰레드 환경에서 작업 수행에 소요된 시간이 더 짧다는 것을 알 수 있다. 이는 멀티 쓰레딩을 도입한 의도에 부합하는 결과이다.
1
2
[Single-Thread] 39.043801s
[Multi-Thread] 27.756528s
그렇다면 왜 I/O-bound 작업에서는 멀티 쓰레딩을 사용하는 것이 더 좋은 성능을 보일까?
이는 위에서도 언급했듯이, 실행 중인 파이썬 쓰레드는 blocking operation(ex. I/O 연산, 시스템 콜 함수 호출) 시에 GIL을 릴리즈하기 때문이다. 하나의 쓰레드가 time.sleep(2)을 만나게 되면 해당 쓰레드가 GIL을 릴리즈하고, GIL을 다른 쓰레드가 획득하여 곧바로 자신의 작업을 수행하므로, 싱글 쓰레드 환경에서 작업들이 순차적으로 수행될 때보다 효율적으로 동작하는 것이다.
4. CPU-Bound 작업을 병렬로 처리하려면?
I/O-bound 작업은 멀티 쓰레딩을 활용해도 성능 향상을 기대할 수 있다. 그렇다면 멀티 쓰레딩 시 성능이 저하되는 CPU-bound 작업을 병렬로 처리하려면 어떻게 해야 할까?
[1] 멀티 프로세싱 사용하기
멀티 쓰레드 대신 멀티 프로세스를 이용할 수 있다. 이때, 프로세스마다 각각 파이썬 인터프리터와 메모리 공간을 가지게 되므로, 서로 자원을 공유하지 않기 때문에 GIL이 문제가 되지 않게 된다. 파이썬에서는 multiprocessing, concurrent.futures 모듈을 통해 멀티 프로세싱을 사용할 수 있으며, 이렇게 하면 멀티 코어를 활용할 수 있다.
CPython에서는 GIL로 인해 멀티 쓰레딩만 사용하면 멀티 코어를 활용할 수 없다! 하나의 파이썬 인터프리터 프로세스에서 한 시점에 단 하나의 쓰레드만 실행될 수 있기 때문이다.
다음과 같은 코드를 통해 3회의 CPU-bound 작업을 멀티 쓰레딩으로 구현했을 때와 멀티 프로세싱으로 구현했을 때의 소요 시간을 비교해보자. (본 코드에서는 multiprocessing 모듈을 사용한다.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import random
from threading import Thread
from multiprocessing import Process
import time
def work_cpu():
min([random.random() * 100 for _ in range(50_000_000)])
if __name__ == "__main__":
# [1] Multi-Thread
s = time.time()
t1 = Thread(target=work_cpu)
t2 = Thread(target=work_cpu)
t3 = Thread(target=work_cpu)
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
e = time.time()
print(f"[Multi-Thread] {e - s:5f}s")
# [2] Multi-Process
s = time.time()
p1 = Process(target=work_cpu))
p2 = Process(target=work_cpu))
p3 = Process(target=work_cpu)
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
e = time.time()
print(f"[Multi-Process] {e - s:5f}s")
측정 결과, 멀티 프로세싱 시에 소요되는 시간이 더 적다는 것을 알 수 있다.
1
2
[Multi-Thread] 23.084413s
[Multi-Process] 9.981085s
다만, 프로세스는 자신만의 메모리 공간을 가지기 때문에 멀티 쓰레딩보다 멀티 프로세싱의 상황에서 더 많은 메모리를 필요로 하므로 문맥 교환(context switching) 비용이 더 들게 된다는 점에 유의해야 한다.
[2] CPython이 아닌 다른 구현체 사용하기
GIL은 파이썬 공식 구현체인 CPython에만 존재하기 때문에, Jython, IronPython, PyPy 등의 다른 인터프리터 구현체를 사용하면 GIL의 영향을 받지 않는다.
References
- https://wiki.python.org/moin/GlobalInterpreterLock
- https://python.land/python-concurrency/the-python-gil
- http://www.dabeaz.com/python/GIL.pdf
- https://en.wikipedia.org/wiki/Thread_safety
- https://realpython.com/python-gil/
- https://granulate.io/blog/introduction-to-the-infamous-python-gil/
- https://www.datacamp.com/tutorial/python-global-interpreter-lock
- https://www.guru99.com/cpu-core-multicore-thread.html
- https://pythonspeed.com/articles/python-gil/
- https://stackoverflow.com/questions/7542957/is-python-capable-of-running-on-multiple-cores
- https://iosdevlime.tistory.com/entry/iOSCombine-CPU와-코어-그리고-프로세스와-스레드의-개념
- https://kimsring.tistory.com/entry/CPU-작동-방식-싱글코어-vs-멀티코어
- https://velog.io/@injoon2019/병렬화와-장단점에-대하여
- https://stackoverflow.com/questions/4496680/python-threads-all-executing-on-a-single-core
- https://it-eldorado.tistory.com/160
- https://ssungkang.tistory.com/entry/python-GIL-Global-interpreter-Lock은-무엇일까
- https://tibetsandfox.tistory.com/43
- https://hero-space.tistory.com/entry/파이썬으로-간편하게-Multiprocessing-의-시작하기
- https://atonlee.tistory.com/88
- https://monkey3199.github.io/develop/python/2018/12/04/python-pararrel.html
- https://changhyeonnam.github.io/2022/02/03/multitasking.html