[Paper] Siamese Neural Networks for One-shot Image Recognition
📎 Paper: https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
1. Introduction
1.1 One-Shot Learning
- test instance에 대해 예측하기 전, 각 class 마다 하나의 example 만을 학습할 수 있다.
evaluate 시에 분류할 클래스의 개수(= n)에 따라 n-way one-shot task라고 한다.
ex) 분류할 클래스가 25개라면 25-way one-shot task (→ 랜덤으로 예측할 때의 확률 = 4%)
Related Work (Baseline)
- 1-Nearest Neighbor
- 단순히 test image에서 Euclidean Distance로 가장 가까운 학습 이미지와 가까운 것을 선택하는 방법이다.
- 20-way one-shot task에서 정확도 = 21.7%
- HBPL(Hierarchical Bayesian Program Learning)
- generative 하게 문자를 그리는 과정을 모델링하여 image를 작은 부분으로 나눈다.
- 한 획이 그려질 때마다 앞으로 어떻게 획이 그려질지 prior distribution을 사용하여 글자를 생성한다.
- 20-way one-shot task에서 정확도 = 95.2%
- 단점: raw pixel이 아닌 획에 대한 정보를 사용하여 생성 모델을 학습하므로 데이터셋을 구하기가 매우 어렵다.
Deep Networks for One-Shot Learning
- 일반적인 Cross Entropy로는 One-Shot Learning이 불가능한 이유 = overfitting
- 수많은 parameter 때문에 소수의 데이터로는 학습이 불가능하다.
1.2 Approach: Supervised Metric-based Approach
- siamese neural network를 사용하여 image representation을 학습한다.
- generic image feature를 학습할 수 있다.
- source data에서 sampling 된 pairs를 이용하여 standard optimization techniques로 쉽게 학습할 수 있다.
- 특정 domain-specific knowledge에 의존하지 않는다.
- one-shot learning을 위해 해당 network의 feature를 재사용 한다. (w/o retraining)
- 학습된 neural network는 image pairs의 class-identity 간 discriminate가 가능해야 한다. (⇒ verification task를 잘 해야 한다!)
- input pairs가 서로 같거나 다른 class에 속할 확률을 이용하여 학습한다.
- 이렇게 학습한 모델은 새로운 이미지(= 새로운 class 마다 하나의 이미지)에 대해 evaluate 할 수 있다.
- test image와 pairwise 방법으로, highest score인 pairing이 highest probability를 가지게 된다.
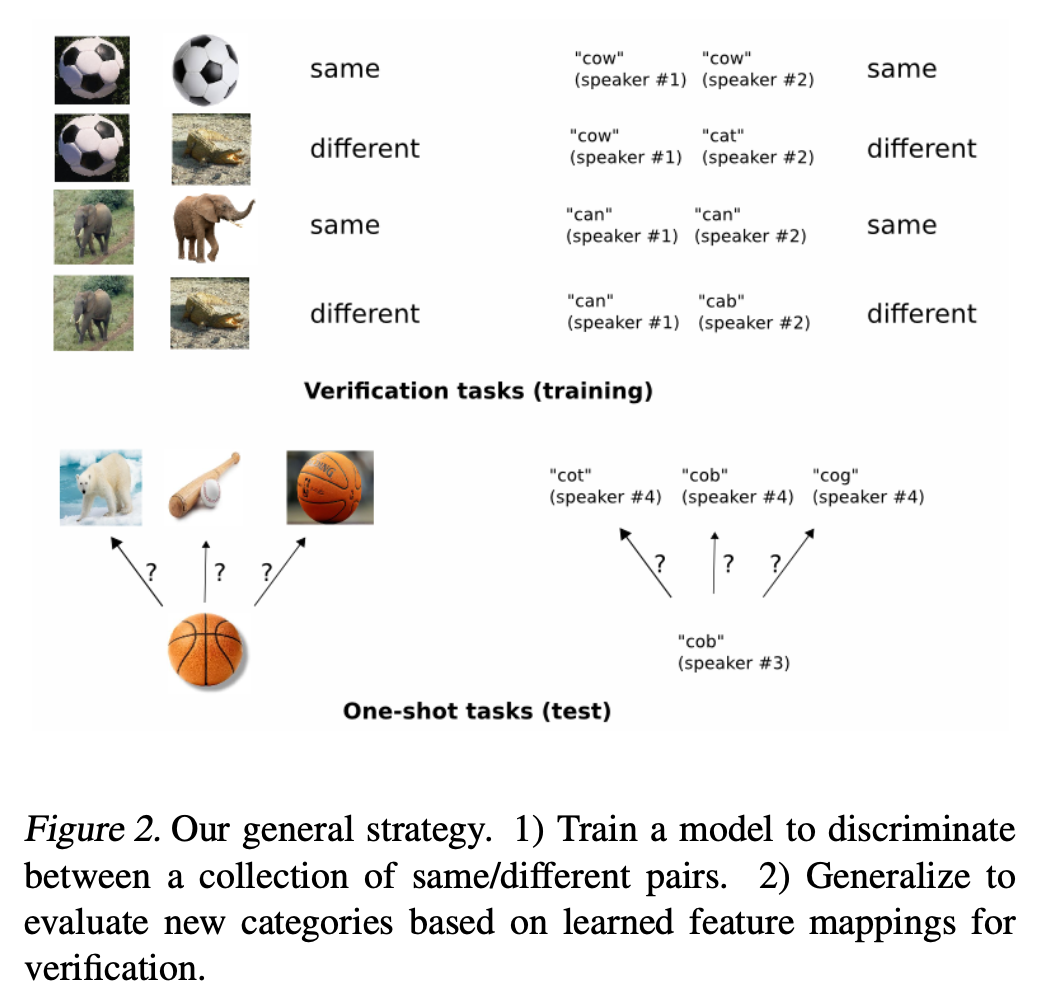
- train: verification task (useful & robust 한 feature 학습)
- test: one-shot task (맞는 class 찾기)
2. Siamese Network
2.1 Introduction
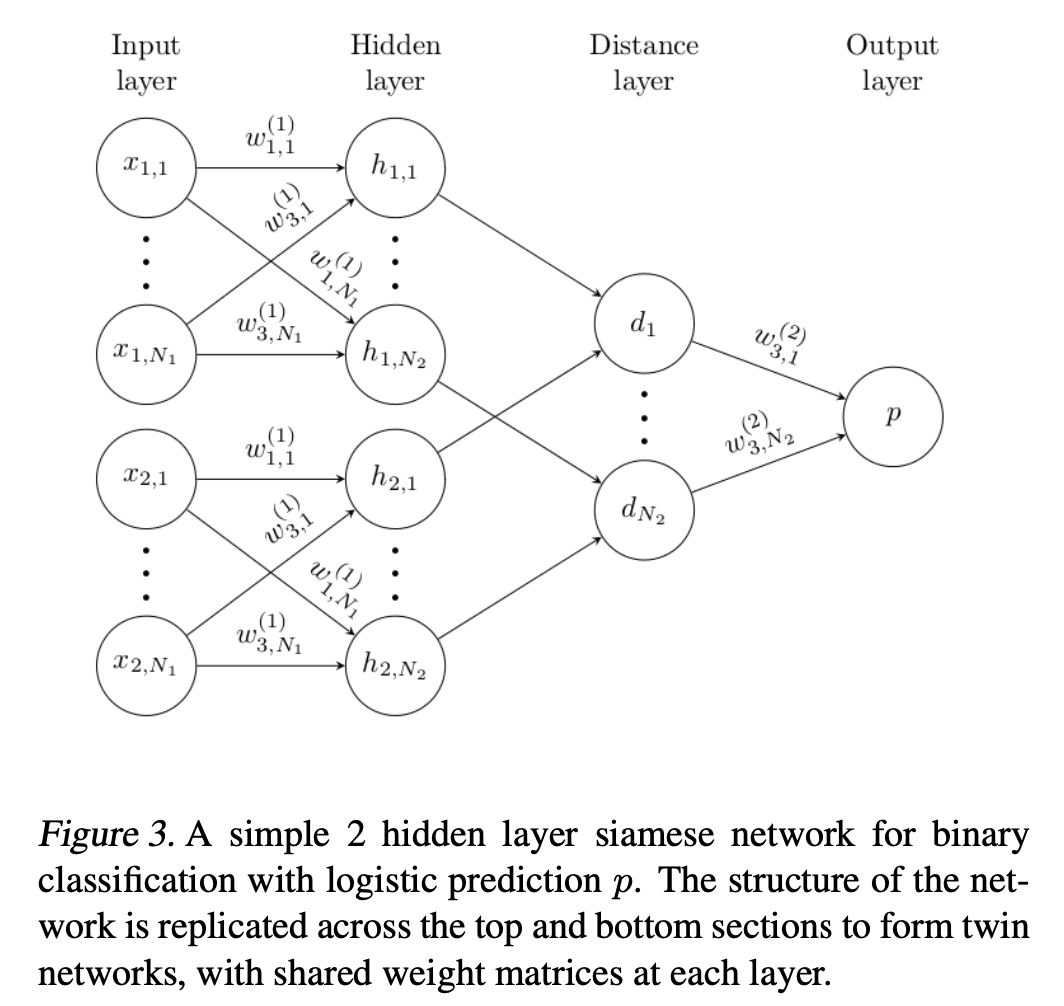
- 서로 다른 input을 입력으로 받지만, 최상단에 energy function으로 join 되어 있는 twin networks로 이루어져 있다.
- twin network의 parameter는 tied 되어 있다. (= weight를 share 한다.)
- twin network는 symmetric 하다. (= 두 input의 순서가 바뀌어도 top conjoining layer의 결과는 같다.)
- twin feature vectors \(\mathbf h_1\)와 \(\mathbf h_2\) 간의 weighted L1 distance를 이용한다.
- sigmoid activation을 통해 interval [0, 1]으로 mapping 한다.
- train 시에 cross-entropy objective를 사용한다.
2.2 Model
\(L\) layers (각 layer 마다 \(N_l\) units)
앞의 \(L-2\) layers ReLU unit 사용 나머지 layers sigmoidal unit 사용 각 layer에서의 \(k\) th filter map (ReLU → max-pool w/ filter size & stride 2)
\[a_{1,m}^{(k)}=\text{max-pool}(\max(0, \mathbf W_{l-1,l}^{(k)}*\mathbf h_{1, (l-1)}+\mathbf b_l),2)\] \[a_{2,m}^{(k)}=\text{max-pool}(\max(0, \mathbf W_{l-1,l}^{(k)}*\mathbf h_{2, (l-1)}+\mathbf b_l),2)\]\(\mathbf W_{l-1,l}\) layer \(l\)의 feature map을 나타내는 3-dim tensor \(\mathbf h_{1, l}\) first twin의 layer \(l\)의 hidden vector 전체 convolutional architecture
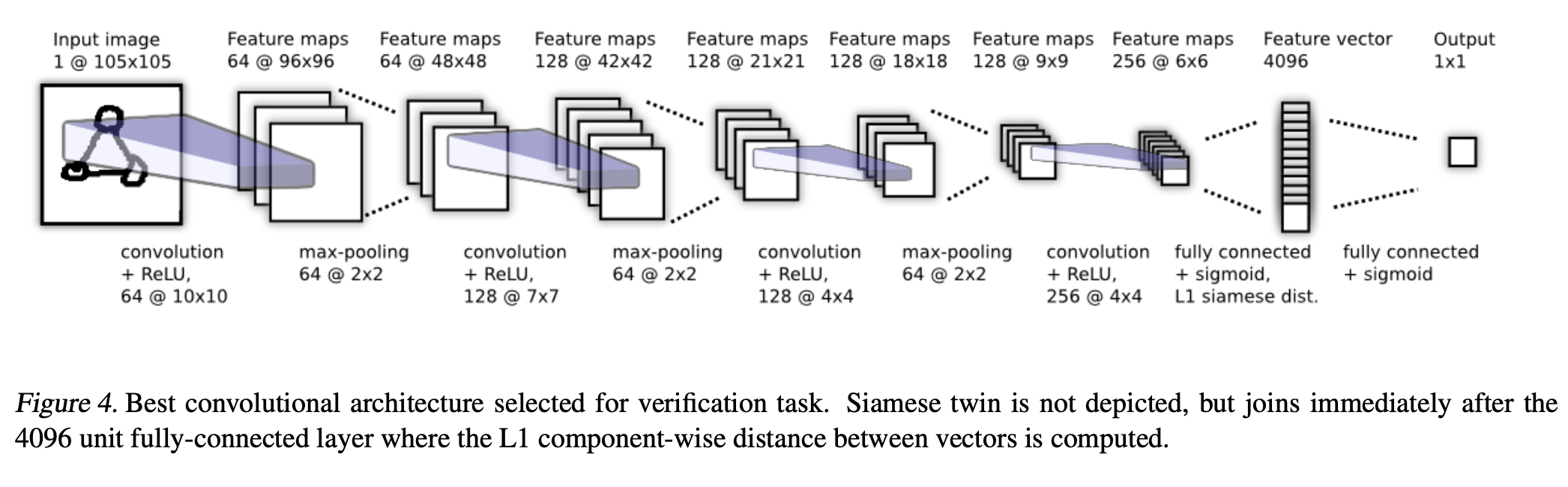
- convolutional layers
- fully-connected layer (+ sigmoid)
- 각 twin network에서 나오는 feature vector를 통해 L1 Norm을 구한다.
- prediction vector \(\mathbf p = \sigma (\sum_j \alpha_j \vert\mathbf h_{1, L-1}^{(j)}-\mathbf h_{2, L-1}^{(j)}\vert)\)
- a layer computing the induced distance metric (+ sigmoid)
- (L-1)th hidden layer에서 학습된 feature space에서의 metric을 계산한다.
- sigmoid 함수를 통해 two feature vectors 간의 similarity를 score 한다.
- \(\alpha_j\) = component-wise distance의 importance를 weighting 하는 parameter (학습됨)
2.3 Learning
- loss function으로는 regularized cross-entropy objective를 사용한다.
- 직접적으로 same class 끼리는 가깝게, different class 끼리는 멀게 학습시키는 것이 아니다.
최대 200 epochs로 학습시키다가, one-shot validation error가 20 epochs 동안 감소하지 않으면 학습을 중단했다.
one-shot validation error
= validation set에서 랜덤하게 생성된 320 one-shot learning tasks에서 계산
training set에 small affine distortions를 주어 augment 했다.

- 그 외 자세한 내용은 논문 참고
3. Experiments
3.1 Dataset: Omniglot Dataset

- handwritten character recognition domain의 데이터셋이다.
- 50가지 언어에 대해 총 1623개의 문자를 포함하고 있다.
- 20명의 다른 사람으로부터 쓰였다. (→ 총 20*1623개의 데이터)
- 구분 (→ train / validation / test set과 별개로 사용됨)
- 40 alphabet background set
- hyperparameter와 feature mapping을 학습하는 모델을 학습시킬 때 사용
- 10 alphabet evaluation set
- one-shot classification performance를 측정할 때 사용
- 40 alphabet background set
3.2 Training Verification Network
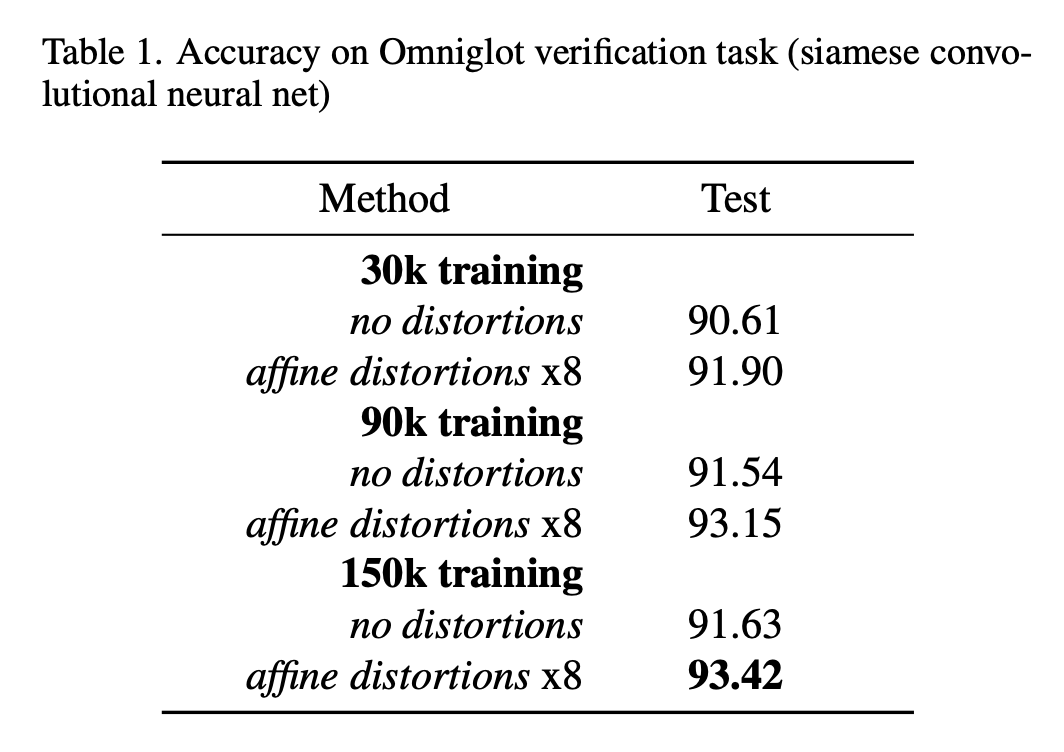 best validation checkpoint & threhsold 에서의 test accuracy
best validation checkpoint & threhsold 에서의 test accuracy
- random same / different pairs를 sampling 하여 각각 30,000, 90,000, 150,000 training examples로 이루어진 dataset을 만들었다.
- affine distortions는 각 크기별 dataset에 augmented version(8x)으로 추가했다.
- training 단계에서의 performance monitoring에 사용한 dataset
- verification task를 위한 validation set (w/ 10,000 example pairs)
target task(= one-shot recognition)를 위한 validation set (w/ 320 one-shot recognition trials)
→ termination criterion으로 사용
3.3 One-shot Learning
- siamese network를 verification task에 잘 동작하도록 학습했으므로, 학습된 features가 discriminative potential을 가졌다고 판단할 수 있다.
- test 시 다음의 이미지를 입력하여, \(\mathbf x\)가 어떤 class와 가장 비슷한지 query 할 수 있다.
- test image \(\mathbf x\) : \(C\) categories 중 하나로 분류하고 싶은 column vector
- some other images \(\lbrace\mathbf x_c\rbrace_{c=1}^C\) : 각 \(C\) categories의 example을 나타내는 column vectors의 set
⇒ maximum similarity \(C^*= \arg\max_c \mathbf p^{(c)}\)
Evaluate One-shot Learning Performance
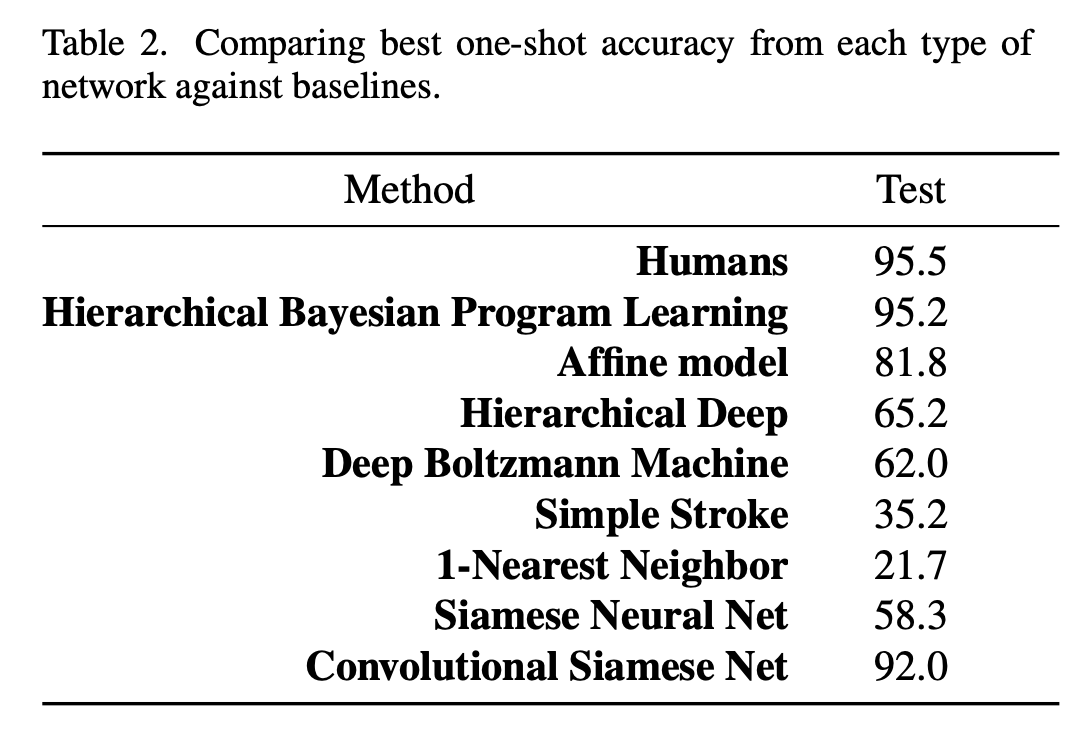
- 20-way within-alphabet classification task
- evaluation set에서 사용할 alphabet의 종류를 고른다.
- 해당 종류의 alphabet에서 20 characters를 고른다. (uniformly at random)
- 20명의 drawers 중 2명을 선택하여 각각 20 characters를 그리게 한다.
- first drawer의 characters는 각 1개의 test image \(\mathbf x\)
- second drawer의 characters는 some other images \(\lbrace\mathbf x_c\rbrace_{c=1}^C\)
- 두 번 반복하여 40 one-shot learning trials가 생기며, 10 alphabet evaluation set이므로 총 400 one-shot learning trials가 생성된다.
- 92%의 test accuracy를 달성했다.
MNIST One-shot Trial

Omniglot dataset으로 학습된 모델이 MNIST dataset에도 일반화가 잘 되는지 실험했다.
→ 10-way one-shot classification task
꽤나 잘 generalize 된다고 판단할 수 있다.
4. Conclusion
- verification을 위한 deep convolutional siamese neural networks를 학습시킴으로써 one-shot classification을 수행하는 방법을 제시했다.
- metric learning approach로 human-level accuracy를 달성할 수 있었으며, 다른 도메인의 one-shot learning task에도 적용될 수 있다.
- 본 논문에서는 global affine transform을 이용한 distortions만을 추가로 고려했으나, individual stroke trajectories에 대한 local affine transformations를 수행 후 하나로 합치는 방법으로 확장한다면 variations에 더 적합한 feature를 학습할 수 있을 것이다.
