[Paper] Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships
📎 Paper: https://arxiv.org/abs/1807.00119
물체 간의 관계(instance-level relationship)를 이용하여 object detection의 성능을 향상시키고 싶어 읽어봤던 논문이다.
1. Introduction
기존의 object detection 관련 연구는 object의 region of interest 근처의 local information, 즉 visual appearance에만 집중했다.
하지만 주로 이미지는 contextual information(scene context + object relationships) 또한 가지고 있다. 이를 무시하는 것은 object detection의 accuracy에 제한을 줄 수 밖에 없다.

이러한 contextual information을 이용하여 object detection을 cognition problem 뿐만 아니라 inference problem으로도 접근할 수 있다.
각 image 마다 얻어진 tailored graph를 이용하며, object는 scene과 상관 관계가 높은 다른 object들로부터 message를 전달받게 된다.
이를 통해 object state는 scene context와 object relationship의 영향을 받게 되며, 이는 category와 location을 결정하는 데에 이용된다.
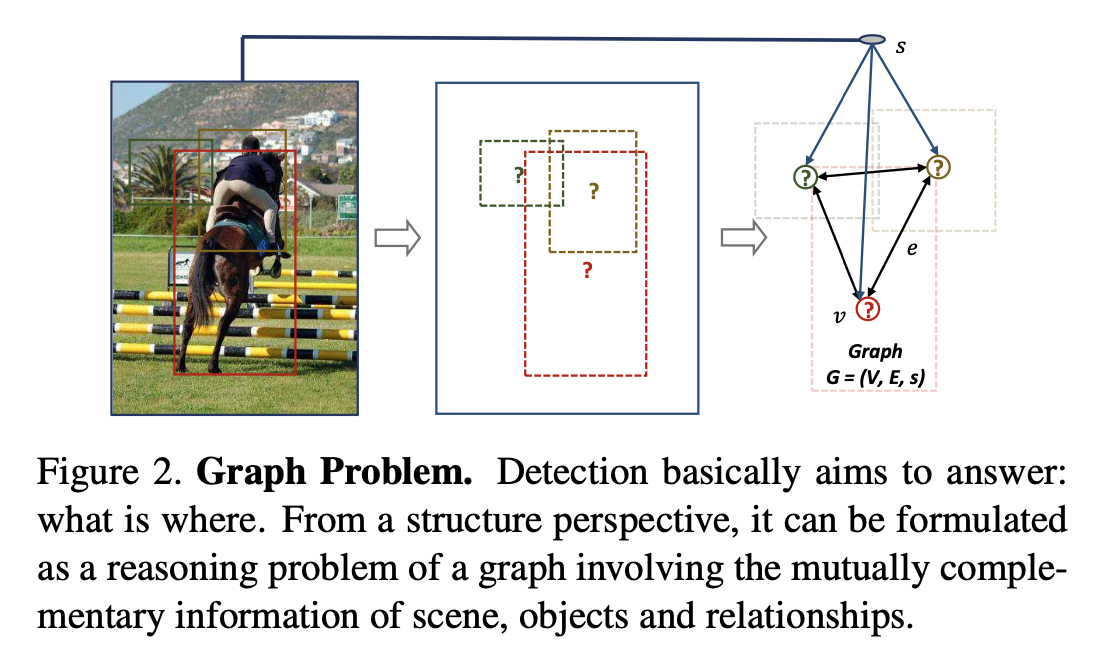 node = object / edge = object relationship
node = object / edge = object relationship
본 논문에서는 graph 내에서의 object state를 추론하기 위해 Structure Inference Network(SIN)을 제안한다.
- 내부에는 object state에 여러 종류의 messages(from scene and different objects)를 encode 하기 위한 memory cell을 가지고 있으며, Gated Recurrent Units(GRUs)로 구성된다.
- GRU의 initial state는 object representation으로 고정하며, 각 message를 입력하여 object state를 update 해나간다.
- 해당 방법은 특정 detection framework에 한정되지 않는다.
2. Related Work
Object Detection
주로 region proposals based methods(two-stage detectors)와 proposal-free methods(one-stage detectors)로 나뉜다.
- two-stage detectors로는 R-CNN, Fast R-CNN, Faster R-CNN 등이 있으며, first stage에서는 candidate boxes를 생성하고, second stage에서는 해당 boxes를 classify 한다.
- one-stage detectors로는 SSD와 YOLO 등이 있으며, real-time detection에 적합하다.
하지만 하나의 image에서 다른 objects를 detect 하는 것은 항상 isolated task로 간주되어 왔다. (특히 two-stage detectors에서)
따라서 vague feature를 가진 작은 object에 대해서는 대응하기 어려웠다.
Contextual Information
context around object or scene-level context를 이용하는 연구(ION, GBD-Net, using segmentation, etc.)는 꽤 진행되어 왔으나, object-object relationship을 이용하는 방법에 대해서는 큰 발전이 없었다.
본 논문에서는 두 가지 정보를 모두 사용하는 방법을 제안한다.
Structure Inference
deep networks와 structured prediction task를 위한 graphical models를 결합한 연구들이 진행되어 왔다. (structure inference machines, Structural-RNN, graph inference model, etc.)
본 논문에서는 object detection task를 graph structure inference problem으로 접근한다.
3. Method
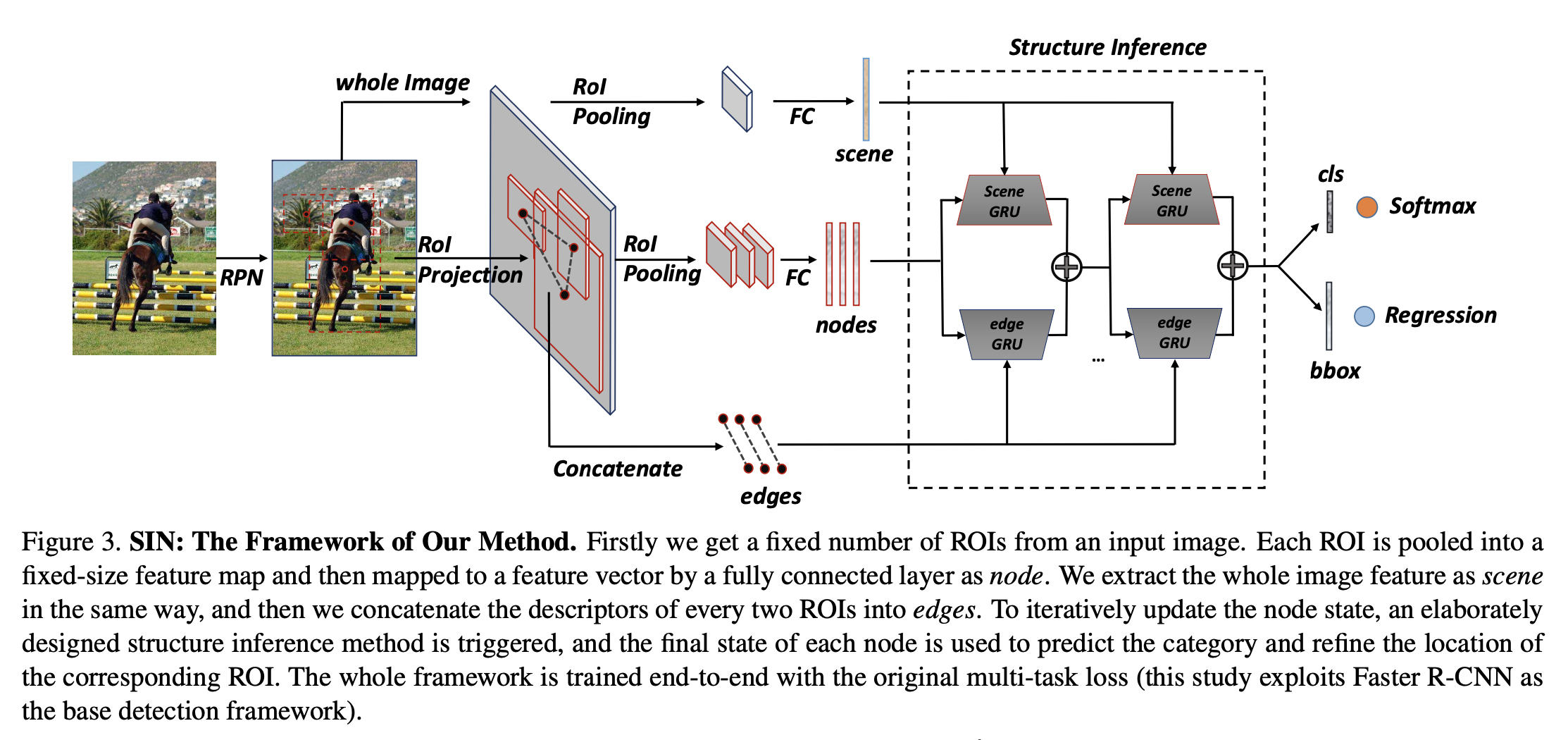
- 반복적으로 node state를 update 해나가며, 각 node의 final state는 해당 ROI의 category를 예측하고 location을 정제하는 데에 사용된다.
- 전체 framework(본 연구에서는 Faster R-CNN)는 end-to-end로 학습되며 original multi-task loss를 사용한다. (base object detection framework와 상관 없이 적용 가능하다.)
Graphical Modeling
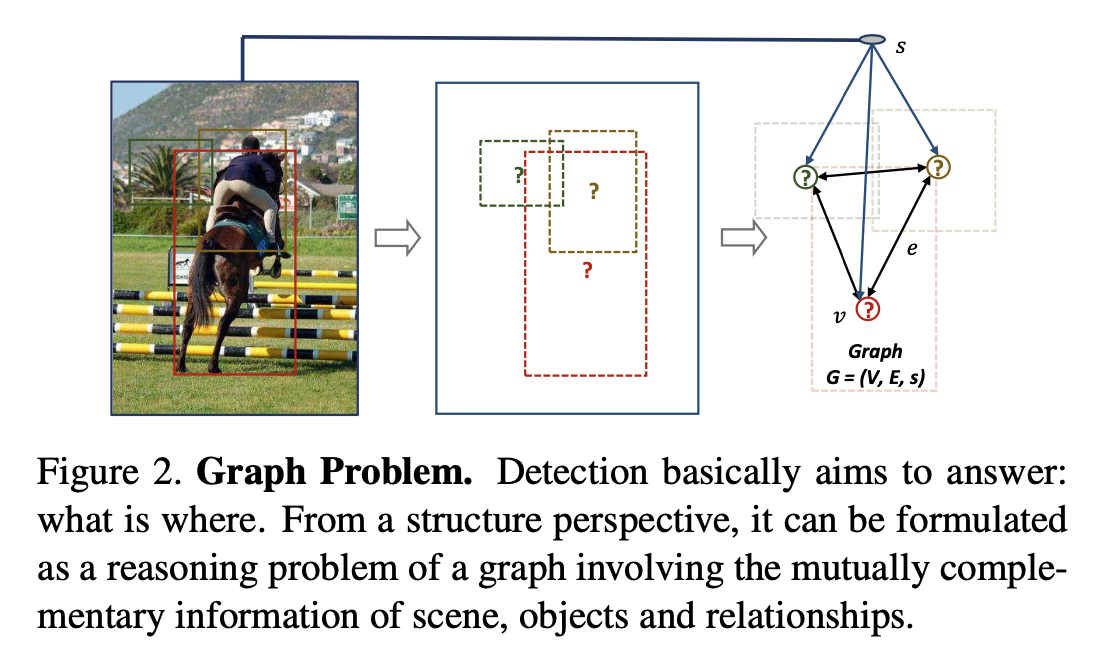
- Graph \(G = (V, E, s)\)
- \(v \in V\) (
node) - region proposals - \(s\) (
scene) - scene of the image - \(e \in E\) (
edge) - relationship between each pair of object nodes
- \(v \in V\) (
- 흐름
- Region Proposal Network(RPN)에서 object가 들어있을 법한 region proposals를 생성한다.
- Non-Maximum Suppression(NMS)을 통해 고정된 수의 ROIs(Region of Interest)를 얻는다.
- 각 ROI \(v_i\)에 대해, ROI pooling layer 이후의 FC layer를 이용하여 visual feature \(f_i^v\)를 추출한다.
- scene label에 대한 ground-truth label이 없으므로 whole image visual feature \(f^s\)를 scene representation으로 사용한다. (node와 같은 연산)
- \(v_i\)에 대한 \(v_j\)의 influence를 나타내는 directed edge \(e_{j\rightarrow i}\) 를 spatial feature와 visual feature를 이용하여 구한다.
Message Passing
node가 interaction 하는 방법은 scene과 다른 nodes로부터 전달 받은 messages를 encode 하는 것이다. 따라서 여러 incoming messages를 기억하고, 의미있는 representation으로 변환해야 한다.
long-term information에 효과적인 memory machine 처럼 동작하는 RNN 중에서 GRU를 사용한다.
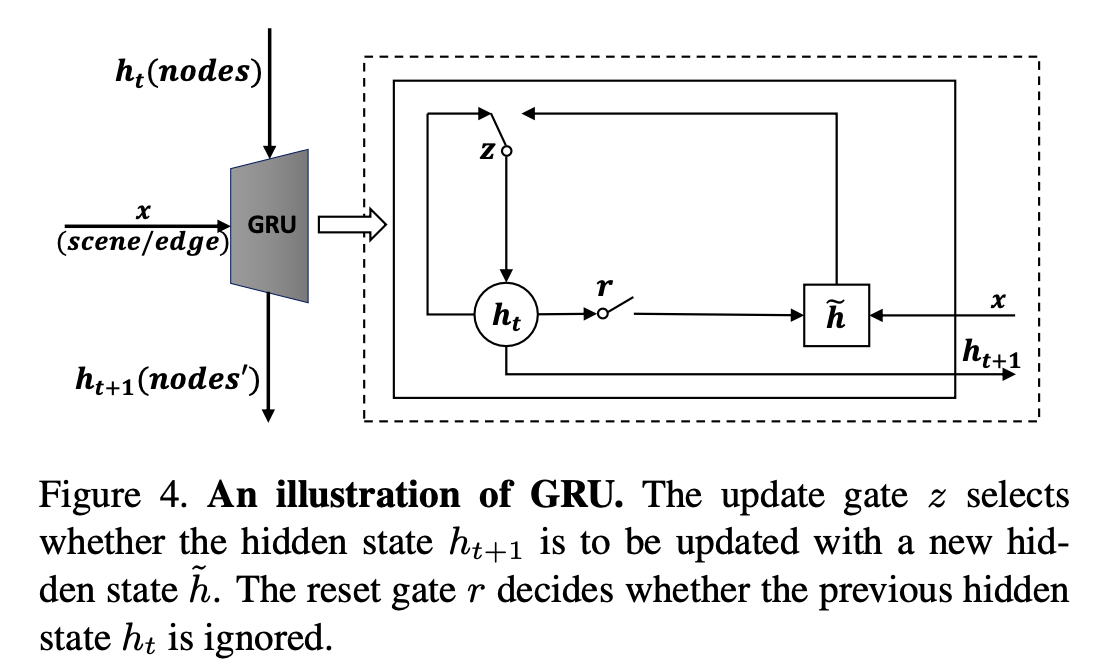
reset gate \(r\):
\[r = σ(W_r[x,h_t])\]update gate \(z\):
\[z = σ(W_z[x,h_t])\]actual activation:
\[h_{t+1}=zh_t+(1−z)\tilde h, \newline \tilde h = \phi(W_x + U(r ⊙ h_t))\]
reset gate를 통해서 관련 없는 information은 drop 되며, update gate를 통해서 더 compact한 representation이 남게 된다.
| encoding message from scene | encoding message from other objects | |
|---|---|---|
| initial state of GRU | object details | object details |
| input | message from scene | integrated message from other nodes |
| 기타 | scene context와 관련 없는 부분은 ignore | object의 state가 update되면 objects 간의 relationship도 변화함 |
Structure Inference
두 종류의 messages를 encode 하기 위해 scene GRUs와 edge GRUs가 사용된다. (scene / other objects → node 로 propagate)
- scene GRU
- initial hidden state - node visual feature \(f^v\)
- input - scene message \(m^s\) (= fixed scene context \(f^s\))
- edge GRU
- integrated message \(m_e\)를 미리 계산해야 한다.
- 한 node에 대해 여러 object들이 다르게 contribute 하므로, 모든 object-object relationship \(e_{j\rightarrow i}\) 을 scalar weight로 모델링 해야 한다. 이는 relative object position과 visual clues를 토대로 결정된다.
node \(v_i\)로의 integrated message는 다음과 같이 계산한다.
\[m_i^e=\max_{j\in V}pooling (e_{j\rightarrow i}*f_j^v), \newline e_{j\rightarrow i}=relu(W_pR_{j\rightarrow i}^p)*tanh(W_v[f_i^v, f_j^v])\]- max-pooling을 이용하는 이유는 mean-pooling을 이용한다면 많은 수의 상관 없는 ROIs에 의해 message가 방해받을 수 있기 때문이다.
- visual relationship vector는 visual feature를 concat 하여 만든다.
spatial position relationship은 다음과 같이 구한다. (ROI의 위치 정보 이용)
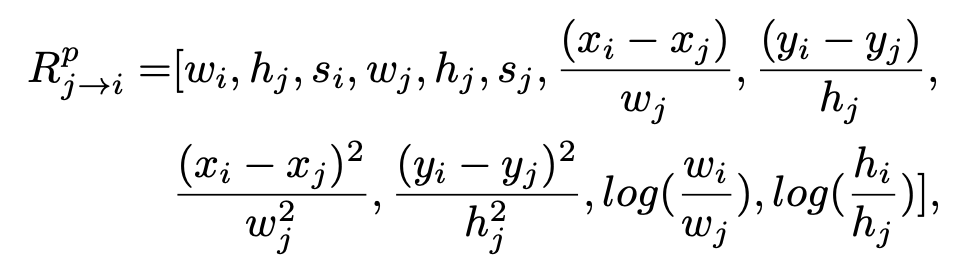
- input - new object-object message
node \(v_i\)는 scene과 다른 nodes로부터 messages를 받으므로, 이를 모두 이용하여 node state \(h_{t+1}\)를 구한다. 이는 GRU의 다음 hidden state로 입력된다.
\[h_{t+1}=\frac{h_{t+1}^s+h_{t+1}^e}{2}\]- \(h_{t+1}^s\) = scene GRU의 결과 / \(h_{t+1}^e\) = edge GRU의 결과
- mean-pooling이 가장 효율적이었다.
- 이를 이용하여 object category와 bounding box offsets를 계산한다.
4. Results
Implementation Details
- dataset - PASCAL VOC, MS COCO
- backbone - VGG-16 pre-trained on ImageNet
- detector (baseline) - Faster R-CNN
- …
Overall Performance
PASCAL VOC (20 categories)
MS COCO (more challenging dataset)

5. Design Evaluation

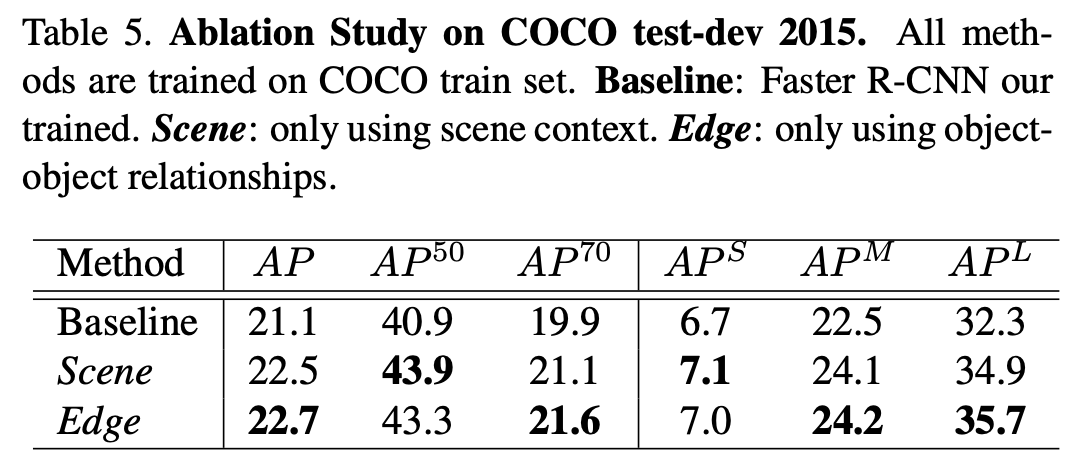
Scene Module
node feature update 시 scene contextual information만 사용한 경우 (= scene GRUs만 사용)
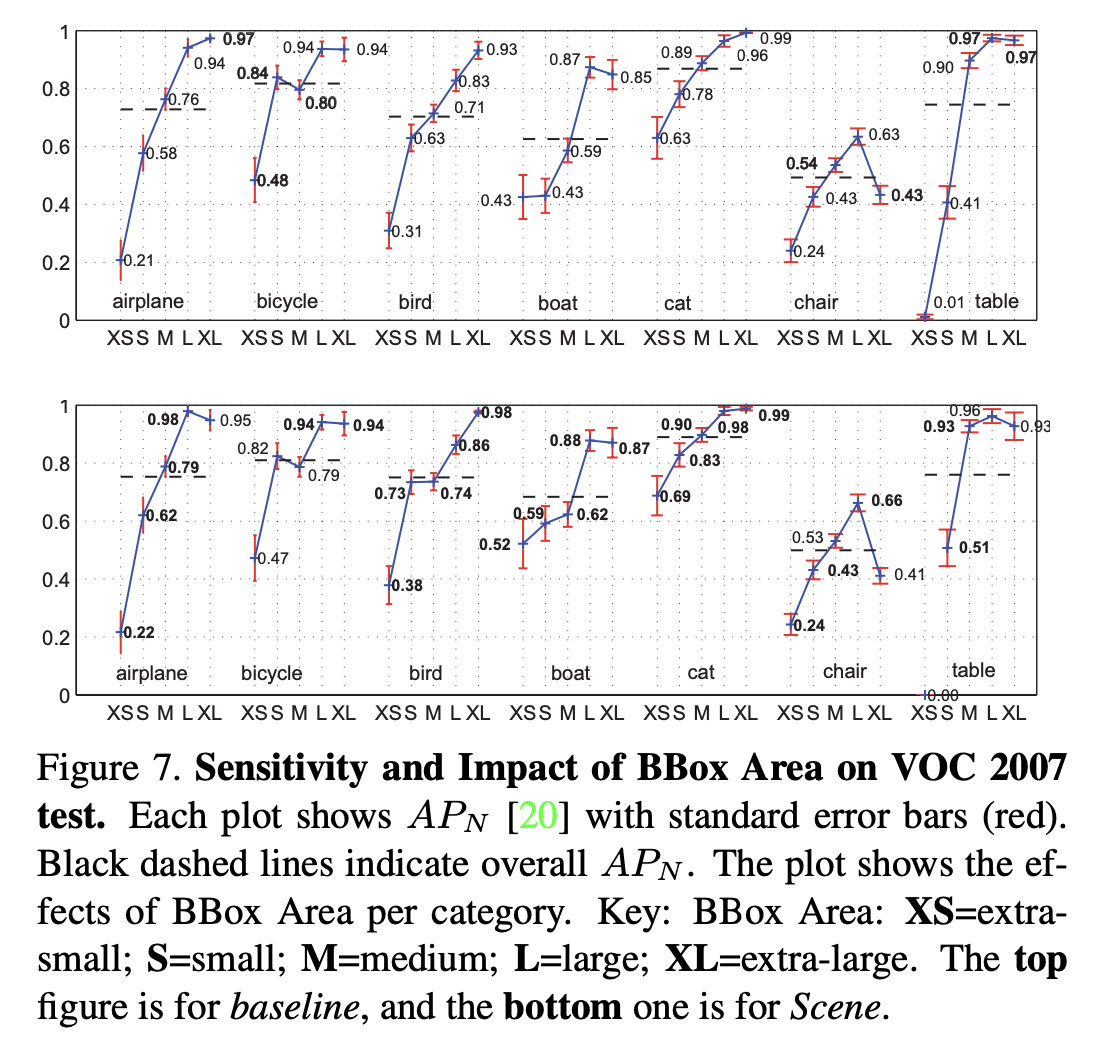
- scene context와 상관관계가 높은 categories(ex. aeroplane, bird, boat, table, train, tv 등)에 대해서 성능 향상이 크게 나타났다.
- baseline과 비교했을 때 occlusion, truncation, area size와 part visibility 부분에서 더 robust 하다.
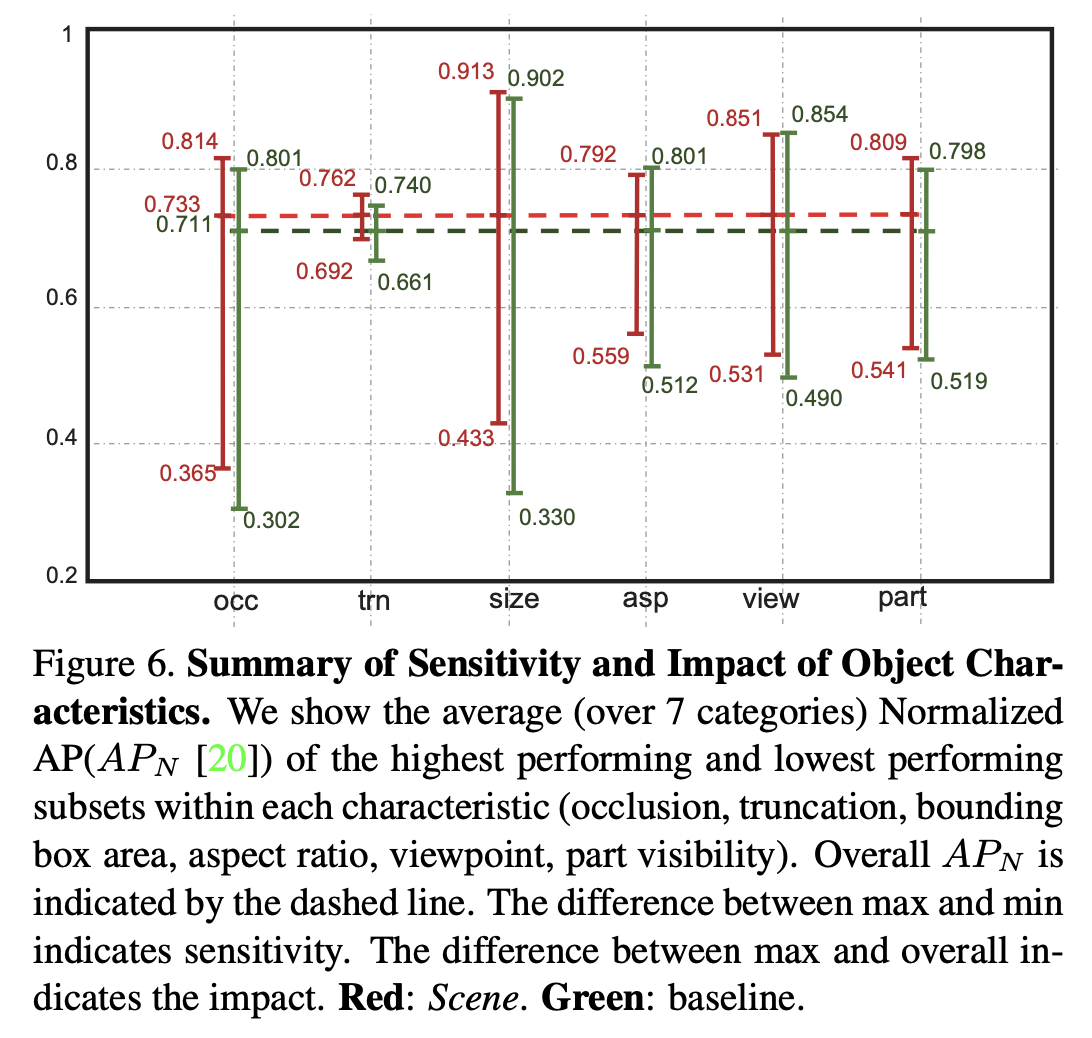
- VOC 데이터셋에서는 XS 크기의 bird, boad, cat category에서 성능 향상이 있었으며, COCO 데이터셋에서도 small object에 대한 성능인 \(AP^S\)가 향상되었다.
실제 예시
(c), (f) - failure case이다. global scene context의 중요도를 weighting 하여 general cases와 rare cases의 balance를 맞추는 방향으로 개선할 수 있다.

Edge Module
edge GRUs만 사용
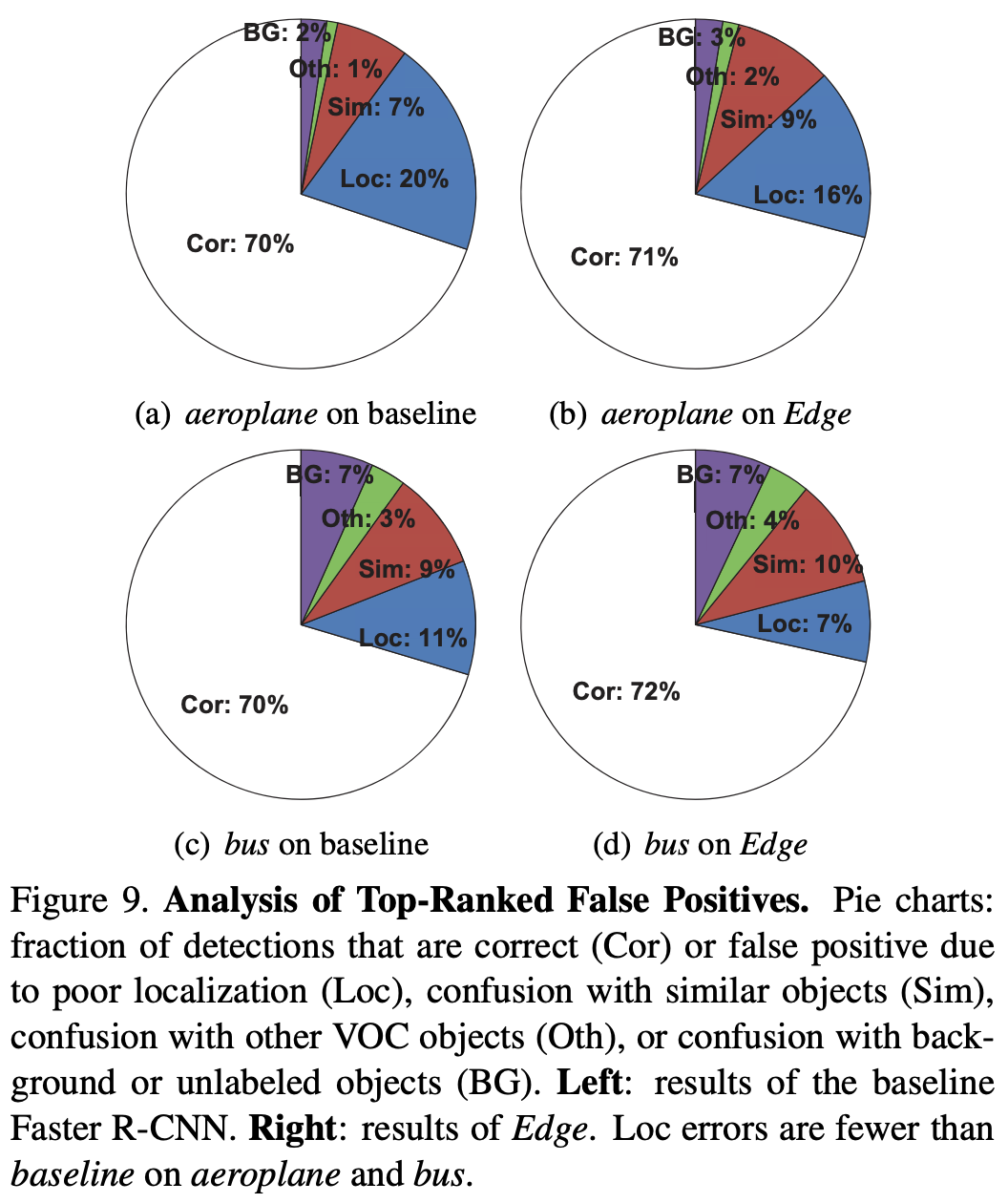
대부분의 카테고리들의 localization 성능이 향상되었다.
aeroplane과 bus에 대해 False Positive를 분석한 결과, localization 오류로 인한 false positive의 비율이 크게 줄었다.
Faster R-CNN에서 자주 발생하는 문제인 ‘하나의 object를 2개 이상의 bbox에서 비슷한 categories로 판단하는 문제’를 크게 개선하였다. (object relationship 사용)

object relationship이 잘 학습되었는지 maximum \(e_{j\rightarrow i}\)를 시각화 한 결과

Ensemble
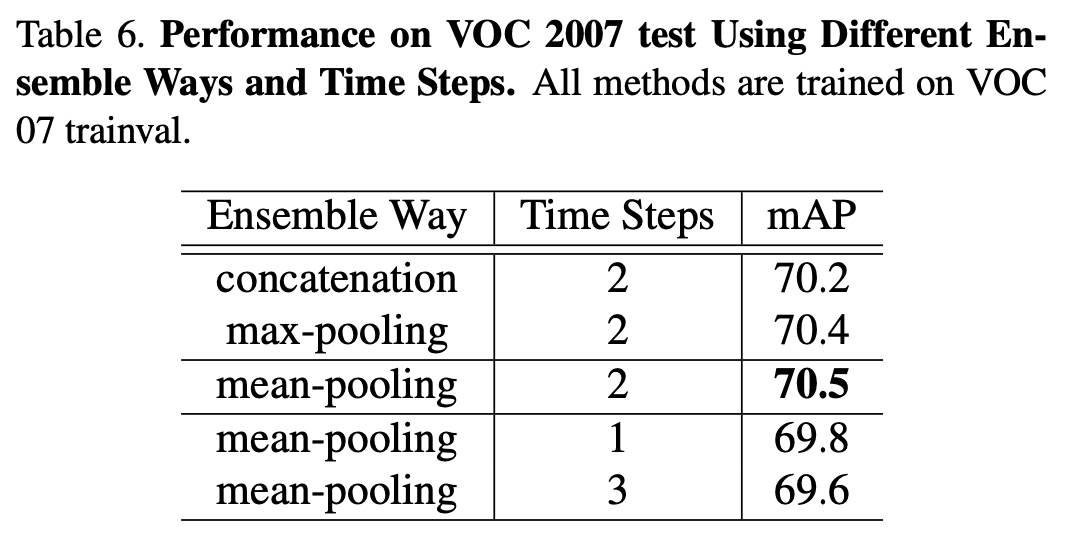
- scene module과 edge module의 hidden state \(h^s\)와 \(h^e\)를 mean-pooling 하여 fusion 하는 것이 성능이 가장 좋았다.
- 학습 시 time steps가 2일 때 성능이 가장 좋았다. (더 늘어나면 message communication의 close loop를 형성할 수도 있으므로)
baseline에 비해 precision은 높고, recall은 비슷했다.
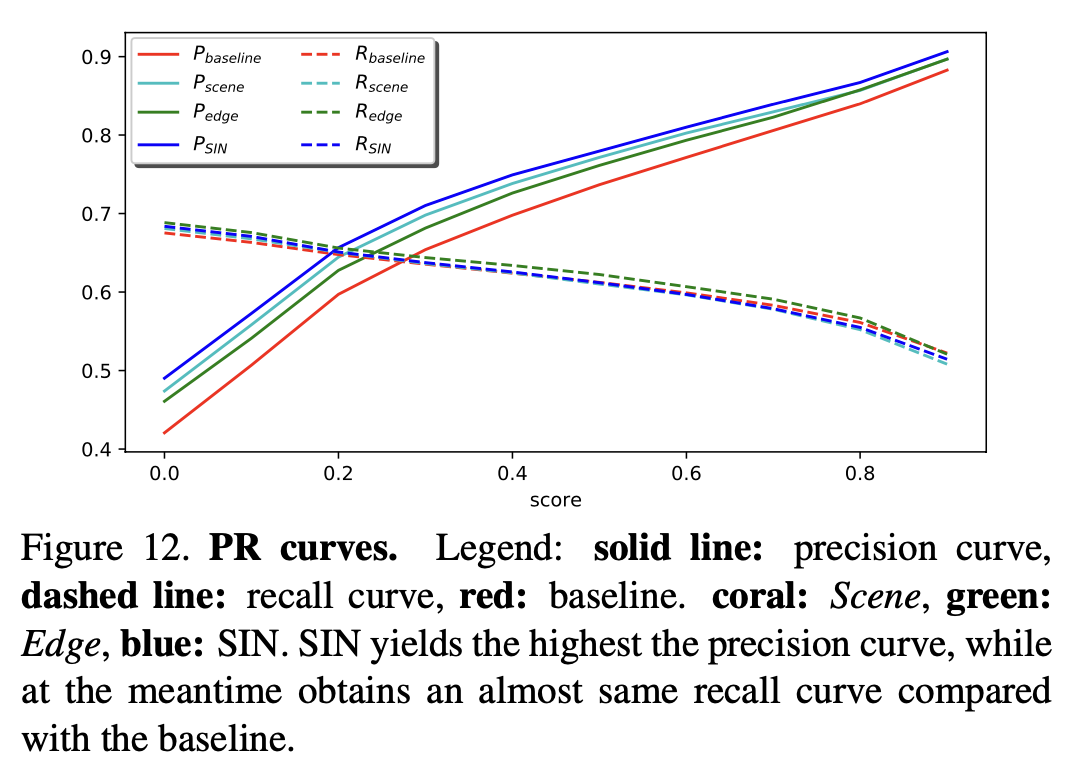
- 이는 같은 수의 positive instances를 recall할 때, SIN의 detection 결과가 더 적고 더 정확하다는 것을 뜻한다.
- recall이 향상되지 못한 것은 additional relationship이 rare case(ex. a boat lies on a street)에 대해서는 방해요소로 작용했기 때문이다.
6. Conclusion
- scene context와 상관관계가 높은 categories에 대해서 scene-level context가 유용했다.
- instance-level relationships 또한 detection 성능 향상에 중요한 역할을 하였으며, 특히 object localization accuracy를 크게 개선했다.