[Python] 파이썬은 왜 느릴까?
본 포스팅의 내용은 파이썬의 공식 구현체인 CPython을 기준으로 작성되었음을 밝힙니다.
파이썬을 접해봤다면 “파이썬은 느리다”는 말을 들어본 경험이 있을 것이다. 도대체 파이썬은 왜 느린 것일까? 그리고 느림에도 불구하고 파이썬이 널리 사용되는 이유는 무엇일까?
파이썬이 느린 이유
고급 언어이기 때문이다.
파이썬은 메모리 관리, 포인터 등 low-level 동작을 추상화한 high-level 언어이기 때문에 파이썬 내부적으로 여러 동작이 수행될 것이므로, C언어와 같은 low-level 언어보다 느리다.
모든 것이 객체이기 때문이다.
파이썬에는 원시 타입(primitive type)이 존재하지 않고, 모든 것이 객체, 즉 참조 타입(reference type)이다. 두 타입의 차이점에 대해 간단히 살펴보면 다음과 같다.
- 원시 타입: 메모리에 값을 그대로 저장
- 참조 타입: 메모리에 해당 값을 저장한 메모리의 위치를 저장 (포인터 같은 개념)
파이썬의 공식 구현체 CPython에서는 모든 것을
pyObject라는 객체로 가지게 되는데, 이것에는 가비지 컬렉션(garbage collection)을 위한 참조 횟수(reference count), 데이터의 타입 등이 포함되게 된다.보통 메모리에서 값을 바로 읽어올 수 있는 원시 타입에 비해, 해당 값이 저장된 메모리 주소에 접근하여 그 값을 읽어와야하는 참조 타입에 접근할 때 시간이 더 소요된다. 예를 들어, 연속된 메모리 공간에 값을 저장한다는 점에서 C언어의 배열과 유사한 numpy
array와 파이썬의 표준list의 내부 구조를 살펴보면 다음과 같고, numpy의 구현이 훨씬 효율적일 것이라는 점을 알 수 있다.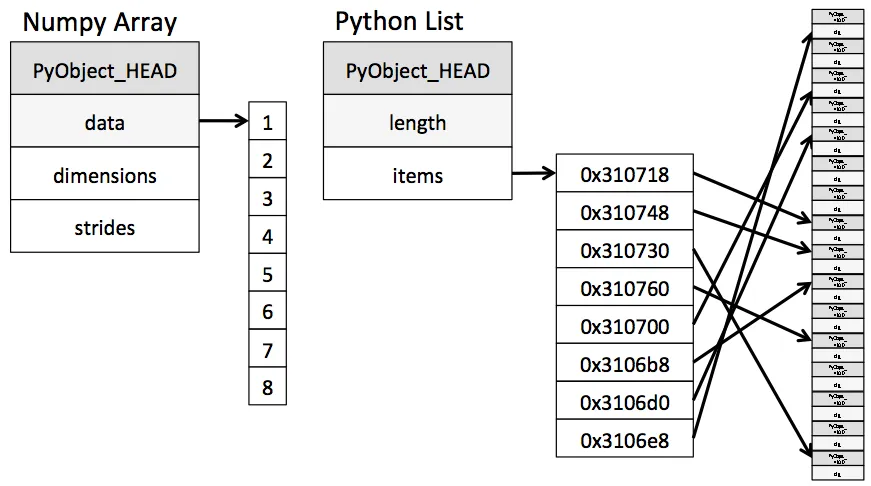 ref: https://medium.com/@cookatrice/why-python-is-slow-looking-under-the-hood-7126baf936d7
ref: https://medium.com/@cookatrice/why-python-is-slow-looking-under-the-hood-7126baf936d7동적 타이핑 언어이기 때문이다.
파이썬은 동적 타이핑 언어이므로 C, C++, Java와 같은 정적 타이핑 언어와는 다르게 변수의 타입을 선언할 필요가 없다. 따라서 처음 값을 변수에 할당할 때는 파이썬 내부에서 해당 변수의 타입을 판단하는 과정이 필요하며, 그 후 변수에 접근할 때마다 해당 변수의 타입 코드(
PyObject_HEAD.typecode)를 확인하고 타입에 해당하는 C의 자료형을 확인 후 대응되는 함수를 호출하는 과정을 거쳐야 하기 때문에 더 많은 작업을 필요로 한다. 또한, 데이터의 타입이 런타임에 결정되므로 얼마만큼의 메모리를 할당할지 미리 알 수 없기 때문에 최적화가 어려워진다.인터프리터 언어이기 때문이다.
컴파일 언어에서는 전체 코드를 컴파일 시점에 기계어로 번역 및 실행 파일을 생성하기 때문에 프로그램을 실행할 때는 실행 파일을 실행하기만 하면 된다. 하지만 인터프리터 언어로 쓰여진 프로그램은 실행 시 런타임에서 라인 단위로 번역이 이루어지므로 번역 동작과 (3번에서 다룬) 동적 타입 관련 작업이 반복적으로 이루어지기 때문에 컴파일 언어에 비해 실행 시간이 오래 걸리는 경향성이 있다.
CPython vs. PyPy
흔히 PyPy를 파이썬의 공식 구현체인 CPython 보다 (훨씬!) 빠른 파이썬 구현체라고 알고 있을 것이다. 그 둘의 차이점을 간단하게 정리하면 다음과 같다.
- CPython은 파이썬 소스 코드를 중간 코드인 바이트코드로 컴파일하고, 바이트코드가 가상머신에 의해 인터프리트 되는 방식이다.
PyPy는 JIT(Just-In-Time) 컴파일 방식을 채택하여, 프로그램 실행 시 필요한 부분의 파이썬 소스 코드를 즉석으로 머신 네이티브 어셈블리어로 컴파일한다. 또한, 그 과정에서 자주 사용되는 코드를 캐싱하여 인터프리터의 느린 실행 속도를 개선한다.
PyPy는 C를 기반으로 구현된 일부 라이브러리와 관련하여 호환성 및 버그 문제가 존재한다.
GIL(Global Interpreter Lock) 때문이다.
CPython에서는 GIL로 인해 하나의 프로세스 내에서 파이썬 인터프리터가 한 시점에 단 하나의 쓰레드에 의해서만 실행될 수 있다. 따라서 CPU-bound 작업에 멀티 쓰레딩을 적용하더라도 오히려 쓰레드 문맥 교환 오버헤드로 인해 싱글 쓰레딩 환경에서보다 성능이 저하될 수 있으며, 멀티 코어를 활용한 병렬 처리가 불가능하게 된다.
파이썬이 널리 사용되는 이유
이토록 느린 파이썬을 왜 사용할까?
어떤 상황에서는 실행 속도보다 개발 속도가 더 중요하다.
일례로, 스포티파이(Spotify)에서는 개발 속도에서 이점을 얻기 위해 파이썬을 사용한다고 밝힌 바 있다. 어플리케이션의 성능은 개발을 완료하는 것 자체보다 중요하지 않다!
파이썬은 빠른 확장에 유리하므로 더 생산적이다.
파이썬은 크로스 플랫폼 지원, 좋은 가독성, 학습의 용이성 등의 강점을 가지고 있으므로 빠른 확장이 가능하다. 이를 통해 구현, 테스트, 배포를 비롯한 개발 사이클을 빠르게 유지할 수 있다. 또한, 대부분의 대형 어플리케이션에서는 한 가지의 언어가 독점적으로 사용되지 않기 때문에, 아주 빠른 성능이 요구되는 부분에 대해서는 다른 언어로 개발하기도 한다.
어떤 분야에서는 프로그래밍은 목적을 위한 수단에 불과하다.
파이썬에는 데이터 분석, 웹 개발, 머신러닝 등 여러 분야에 관련된 프레임워크 및 라이브러리가 존재한다. 따라서 원하는 기능을 밑바닥부터 개발하는 상황은 많지 않으며, 해당 분야의 전문가들에게는 성능보다는 작업을 편리하게 수행하고 완료하는 것이 중요하다.
현대의 어플리케이션들은 I/O 작업에서 대부분의 시간을 소모하는 경향을 띠므로, 실제로 다른 언어들에 비해 크게 느리지 않다.
파이썬 3.11은 빠르다?
이번 포스팅을 작성하며 자료를 찾아보다가 파이썬(CPython) 3.11은 빠르다는 글을 보게 되었다. 공식 문서를 참조하면 3.10에 비해 3.11은 10-60% 사이의 성능 향상을 이끌어내었으며, 표준 벤치마크에서는 평균적으로 25% 정도 빨라졌다고 한다.
관련된 자세한 내용은 다음의 자료들을 참고하자.
관련 자료
References
- https://medium.com/@trungluongquang/why-python-is-popular-despite-being-super-slow-83a8320412a9
- https://medium.com/@cookatrice/why-python-is-slow-looking-under-the-hood-7126baf936d7
- https://medium.com/geekculture/in-defense-of-python-is-slow-85cf38cb1a9e
- https://michigusa-nlp.tistory.com/42
- https://hkim-data.tistory.com/267
- https://jjongguet.tistory.com/77
- https://hitzi.tistory.com/31
- https://velog.io/@jimin_lee/파이썬의-속도가-느리다는-말의-의미
- “더 쉽고 빠른 파이썬” 파이파이(PyPy)의 이해 - https://www.itworld.co.kr/news/302293
- https://docs.python.org/3/reference/datamodel.html#objects-values-and-types
- https://blog.hanlee.io/2018/under-the-c-2
- https://frhyme.github.io/python-basic/python_id_in_python/
- “파이썬은 느리다”에 대한 반론 - https://yozm.wishket.com/magazine/detail/1608/